안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘MetaFormer is Actually What You Need for Vision’입니다. 해당 논문은 2022년 CVPR에서 Oral presentation에 선정된 논문입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘MetaFormer is Actually What You Need for Vision’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/ThCkRzh9Ohw)

오늘 발표드리려고 하는 MetaFormer 논문에 대해서 간략하게 요약을 해드리고 시작하겠습니다.
간단하게 표현을 하면은 일반화된 트랜스포머 구조 정도로 이해해 주시면 될 거 같습니다. 왼쪽에 보시면 저자들이 제안하는 것처럼 token mixer 부분이 아무 영상이나 와도 되는 그런 형태로 MetaFormer가 제안이 되어 있습니다.
원래 기존 트랜스포머 같은 경우에는 이전에 attention이 오게 됩니다. 여러 가지 vit들 다양화되는 모델들 중에서 Fully connected layer를 쓰는 경우도 있었습니다.
저자들은 파라미터도 포함하지 않는 Average pooling을 넣어서 구조를 디자인을 했는데 오히려 SOTA를 달성하는 결과를 얻었다고 합니다.
그래서 이게 논문의 전체적인 콘셉트가 된다고 이해해 주시면 될 거 같고 좀 더 자세한 내용은 뒤에서 설명드리도록 하겠습니다.
컴퓨터 비전에서는 요즘 트랜스포머를 이용한 아키텍처가 유행을 하고 트랜스포머로 넘어오면서 어떤 변화가 있었는지에 대해서 좀 살펴보면 일단 patch embedding이란 부분이 가장 클 것 같습니다. 슬라이딩 윈도우 방식으로 커널이 지나가면서 feature map을 생성하는 방식입니다.
이런 부분들이 바뀌어서 이미지가 하나가 있으면 이 이미지를 잘게 조각을 낸 다음에 그 각각 잘게 조각을 낸 patch에서 특징을 추출하는 방식으로 shift화 되는 경향이 있다고 보시면 될 것 같습니다.
두 번째는 트랜스포머 구조에서 기인하는 attention의 효과를 볼 수 있는데 빨간색 점으로 찍혀 있는 부분이랑 상관성이 높은 부분들은 좀 더 강한 신호를 나타내는 feature map으로 뽑아 줄 수가 있습니다. 여기서 보면은 가위 부분을 찍으면 가위 주변부가 조금 더 강하게 시각화되는 것을 보실 수가 있습니다.
이런 attention에 의한 feature의 explainability도 이런 트랜스포머로 변환이 되면서 얻을 수 있었던 강점입니다.
이런 강점들을 이렇게 사용할 수 있었던 가장 큰 원인으로 저자들은 attention을 뽑았습니다.
지금까지는 이 논문에서 직접 언급했던 논문은 아닌데 intriguing properties of ViT라고 ViT가 왜 잘 되고 강건한가에 대해서 스터디했던 논문입니다.
위 그림을 보시면 patch 형식의 가리는 Occlusion, 색상 자체가 shift가 되는 Distribution shift, 물체에 한 부분이 완전히 가려버리는 Adversarial Patch, 그리고 이미지를 완전히 섞어버리는 Permutation 등의 악조건 속에서도 patch 간의 관계를 인식하는 트랜스포머의 attention 기능이 힘을 발휘해서 정확도가 별로 떨어지지 않는다라고 사람들이 생각을 해오고 있었습니다.
그리고 아까 보여드렸던 feature map을 이용해서 auto segment도 가능했었습니다.
이렇게 attention이 굉장히 좋은 방식이다라고 사람들이 믿었기 때문에 그 후에 후속작들은 attention을 어떻게 하면 더 잘할까에 대해서 많이 고민을 했었습니다. 위 그림 보시면 GPSA라는 새로운 형태의 attention 방식을 제안을 했고 원래는 key, query가 들어가는데 key, query에다가 두 가지 정도 더 Input을 집어넣어서 attention 자체를 좀 강화하려는 시도들이 많이 있었습니다.
한편으로는 attention 자리에 조금 더 다른 연산을 넣으면 어떨까 그런 제안들도 있었습니다.
이 논문도 비전 공부하시는 분들은 한 번쯤 보셨을 수 있는데 이 token Mixer 자리에 Multi layer perceptron을 넣어서 attention이 가지는 그런 token mixing 효과를 내보려고 노력을 했고 그 결과 SOTA에 뒤지지 않는 성능이 충분히 달성할 수 있었다라고 저자들이 이야기를 하고 있습니다.
조금 흥미로운 게 MLP까지 내려왔는데 최근 논문중에서는 여기 이렇게 FFT를 token mixer 자리에 놔서 성능을 발휘하려는 시도도 있었고 이 모델 역시 SOTA에 뒤지지 않는 그런 성능을 보여주는 것을 확인을 할 수 있었습니다.
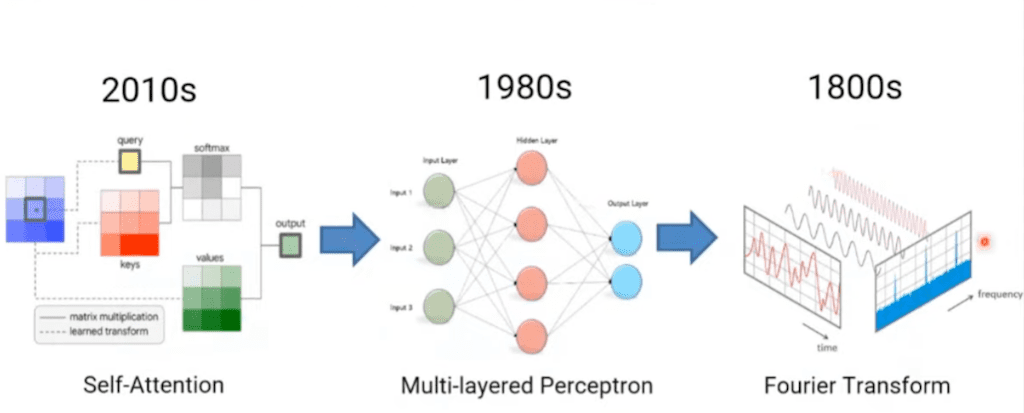
이 흐름을 좀 정리를 해 보면 2010년도에는 어떤 self attention이 Multi Layer perceptron에 다소 옛날 연산 방식으로 퇴화가 됐고 거기에서 한 번 더 Fourier Transform이라는 더 과거에 연산 방식이 token mixer 자리에 오더라도 성능이 잘 나온다 라는 흐름의 저자들이 보게 됐다고 이야기를 합니다.

그래서 저자들은 이럴 거면 화끈하게 Pooling을 넣으면 어떨까?, 아예 파라미터 자체가 없는 Pooling을 넣어 봐서 성능이 잘 나오는지 보면 괜찮지 않을까 라는 그런 생각을 하게 되었습니다.
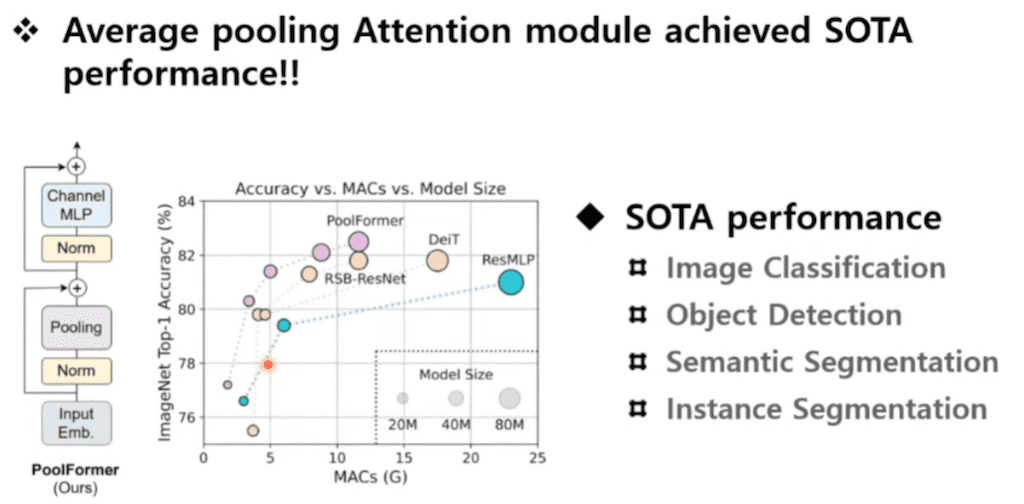
그 결과 실험에서 Pooling을 넣어서 SOTA 성능을 달성하는 PoolFormer라는 아키텍처를 제안하게 됩니다. 그래서 여기 보시면 기존에 있었던 RSB-ResNet, DeiT, ResMLP까지 전부 상회하는 성능을 달성할 수 있었고 백본으로서 다른 테스크에 적용을 했을 때도 좋은 성능이 나오는 것을 관측했다고 저자가 리포트를 하고 있습니다.

저자들이 제안하는 MetaFormer의 개념입니다.
MetaFormer는 트랜스포머 구조에서 attention 들어가는 자리에 아무 영상만 넣어도 괜찮다고 하는 구조를 제안을 합니다. 그래서 input 이미지가 들어올 때 input embedding이라고 해서 이미지 자체를 작은 단위로 쪼개는 patch wise 된 input을 넣게 되고 그 X Input으로 들어와서 patch 단위로 쪼개진 X가 Normalization Layer를 하나 거치고 하나는 Skip connection으로 이어져서 token mixer를 타고 다음 단계로 넘어가게 됩니다.
그다음 단계에서는 Normalization Layer를 통과를 하고 채널 mlp를 가게 되는데 여기서 Expansion ratio가 있어서 feature map 자체를 한번 확장했다가 다시 줄어드는 그런 형태로 fully connected layer를 구성을 하게 됩니다.

저자들이 제안하는 아키텍처는 거기에 average Pooling을 집어넣게 됩니다. average Pooling에 집어넣을 때 다른 점은 Input 자체를 한번 빼줍니다. 그래서 보시면 이 Pooling 자리에서 average Pooling을 하고 Normalization Layer에서 넘어온 Input을 한번 빼놓고 skip connection을 이어받아서 넘어가는 방식으로 이 Pooling 단계를 디자인을 했다고 보시면 될 것 같습니다.
그래서 이게 저자들이 생각을 했을 때 실험적으로 분석을 했을 때 가장 잘 나왔던 구조가 아닌가라고 생각을 합니다.
그래서 PoolFormer를 가장 성능이 잘 나왔던 모델로 제안을 하고 논문에서도 PoolFormer 구조를 메인으로 제안을 하고 있습니다.
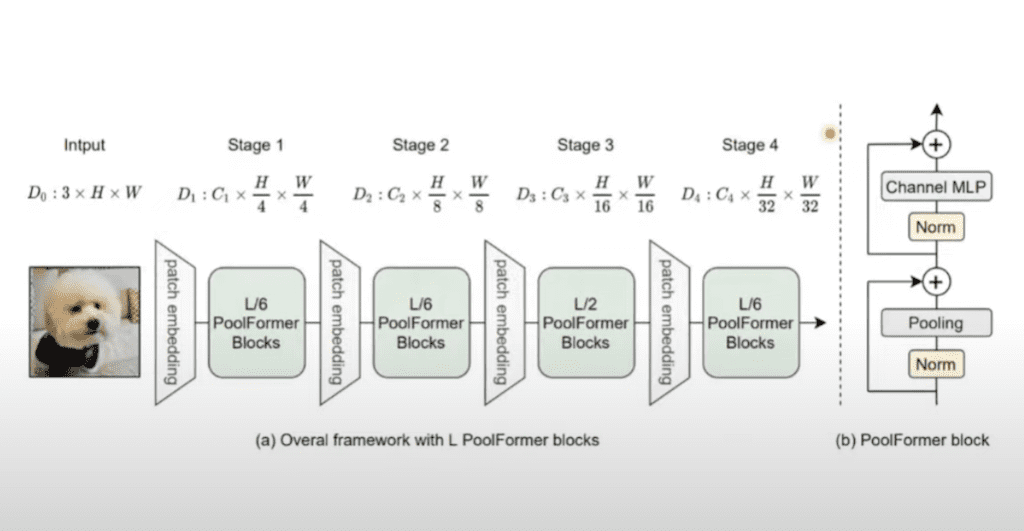
이 구조를 전체적으로 보면 patch embedding이 총 네 번 들어가게 됩니다. 각 patch embedding 사이에 PoolFormer들을 여러 개를 집어넣어서 특징을 추출하는 단계로 구성했습니다.
이미지의 스테이지 자체는 기존에 사용되었던 이미지 classification 모델들의 feature map을 축소하는 비율 정도와 유사하게 4, 8, 16, 32배 정도 축소가 되는 걸 보실 수 있습니다.
여기 보시면 L 자체가 전체의 블록의 개수를 나타내는 데 이 중에 1/6이 여기에 분포한다는 뜻입니다. 1단계, 2단계랑 마지막 단계는 1/6에 블록들이 분포하고 가운데 3번째 스테이지에서 가장 많이 블록들이 배치가 되면서 특징 추출 되는 것을 보실 수가 있습니다.
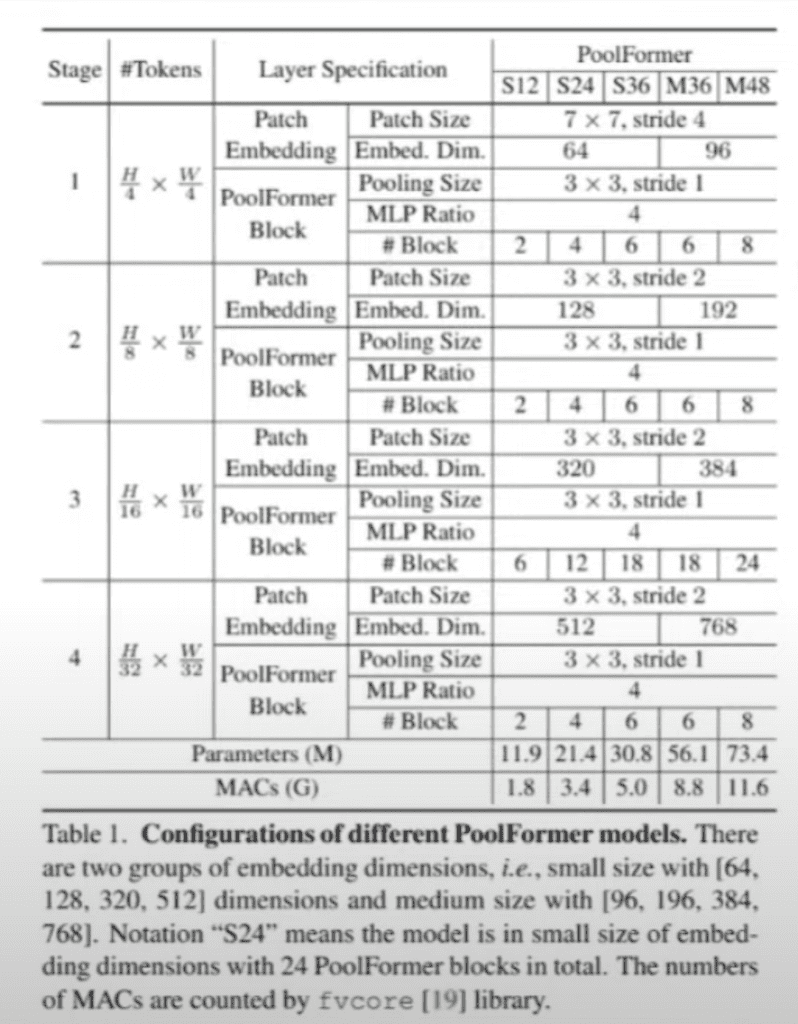
이런 큰 구조상에서 총 다섯 개의 다른 아키텍처가 제시가 되고 첫 번째 요소는 patch embedding 요소가 되고 그 뒤에는 Pooling size 그리고 mlp ratio는 mlp에 의해서 feature map이 확장되는 사이즈를 뜻합니다.
그리고 블록은 PoolFormer 블록 개수를 얘기합니다. 블록 개수는 가면 갈수록 커지는 형태를 전부 취하고 있고 mlp ratio은 각각의 스테이지별로 전부 다 똑같이 4로 고정된 것을 보실 수 있습니다. pooling 사이즈는 3 x 3으로 해서 전체 map을 1 stride 건너뛰지 않고 천천히 스캔하는 방식으로 구성이 되어 있고 patch embedding 자체는 아무래도 Input 이미지 자체가 크다 보니까 patch 사이즈를 조금 크게 가져간 다음에 뒤쪽에서는 3 x 3 정도면은 feature map에 꽤 큰 범위를 차지한다고 판단해서 그런지 3 x 3 정도에 사이즈로 뒤쪽에는 patch embedding을 하는 전략을 보실 수가 있습니다.
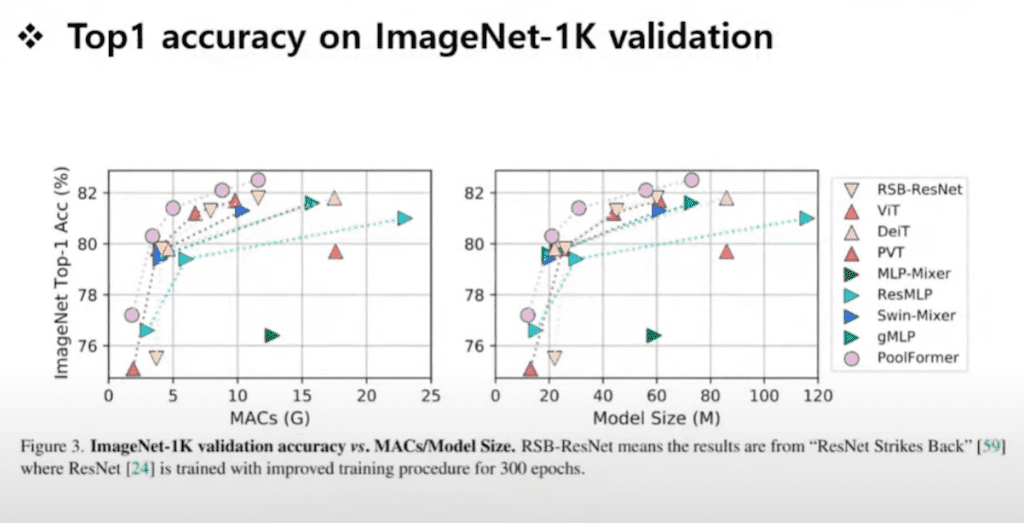
실험입니다.
이렇게 딥러닝 모델들 보면 SOTA를 충분히 달성했다. 여기 왼쪽 상단에 Mac 대비해서 성능이 가장 잘 나왔고 모델 사이즈에 대비해서 성능이 가장 잘 나오는 모습들이다라고 저자들이 이야기를 하고 있습니다.
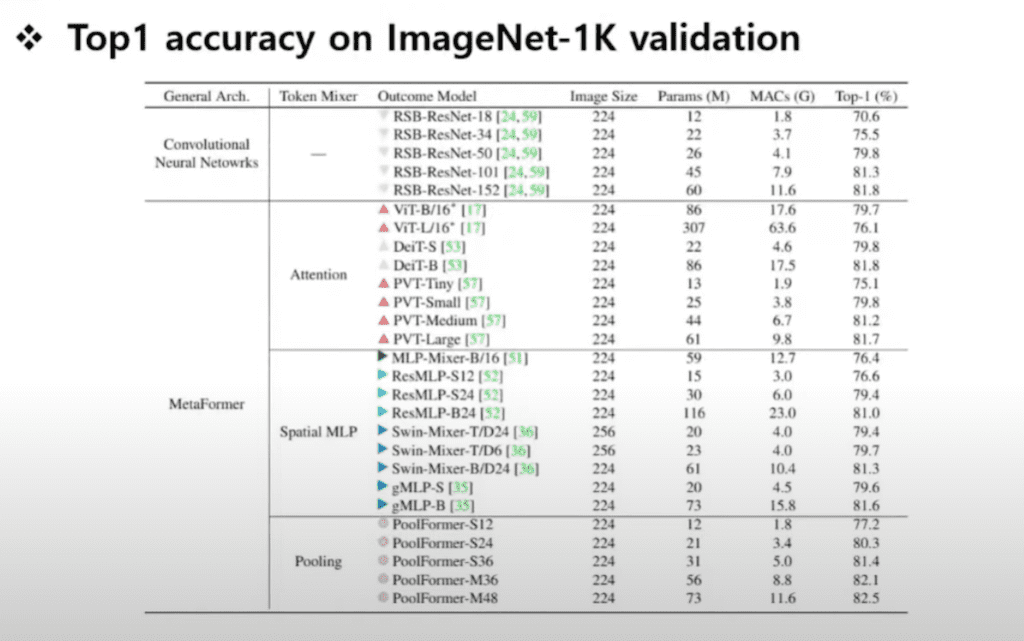
저자들이 상당히 많이 비교군들을 가져와서 비교했습니다. 전통적인 Convolutional 기반한 모델 RSB이라는 논문에서 나온 모델들이랑도 비교했고 attention 자체를 잘하려고 시도했던 모델들이랑도 비교를 했습니다.
그리고 또 다른 모델의 어떤 MLP로 token mixing을 잘해서 성능을 올리는 대부분의 어떤 아키텍처들이랑 다 비교를 했고 성능이 우수하다는 것을 입증시키기 위해서 노력을 많이 했다고 보시면 될 거 같습니다.
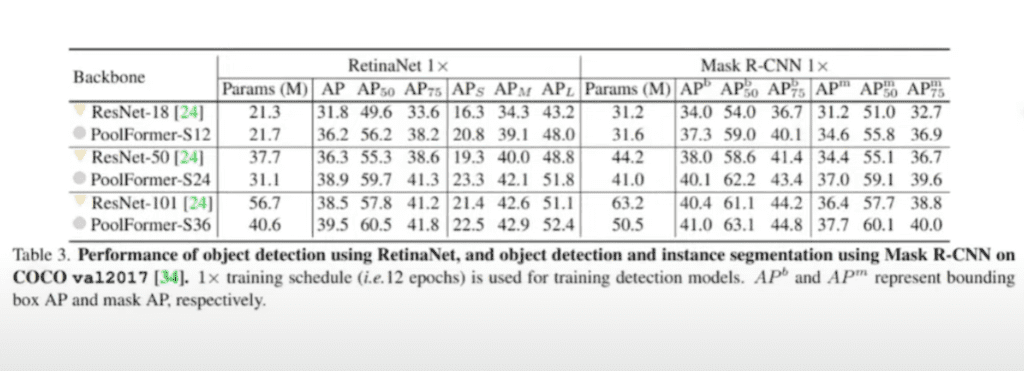
보통 backbone 네트워크에 대해서 제안을 하게 되면 downstream task인 object detection이나 semantic Segmentation에서도 성능이 잘 나오는 곳에 보여야 되기 때문에 RetinaNet과 Instance Segmentation 모델인 Mask R-CNN까지 성능 테스트를 해서 ResNet 대비 잘 나오는 성능을 보였다고 얘기를 하고 있습니다.
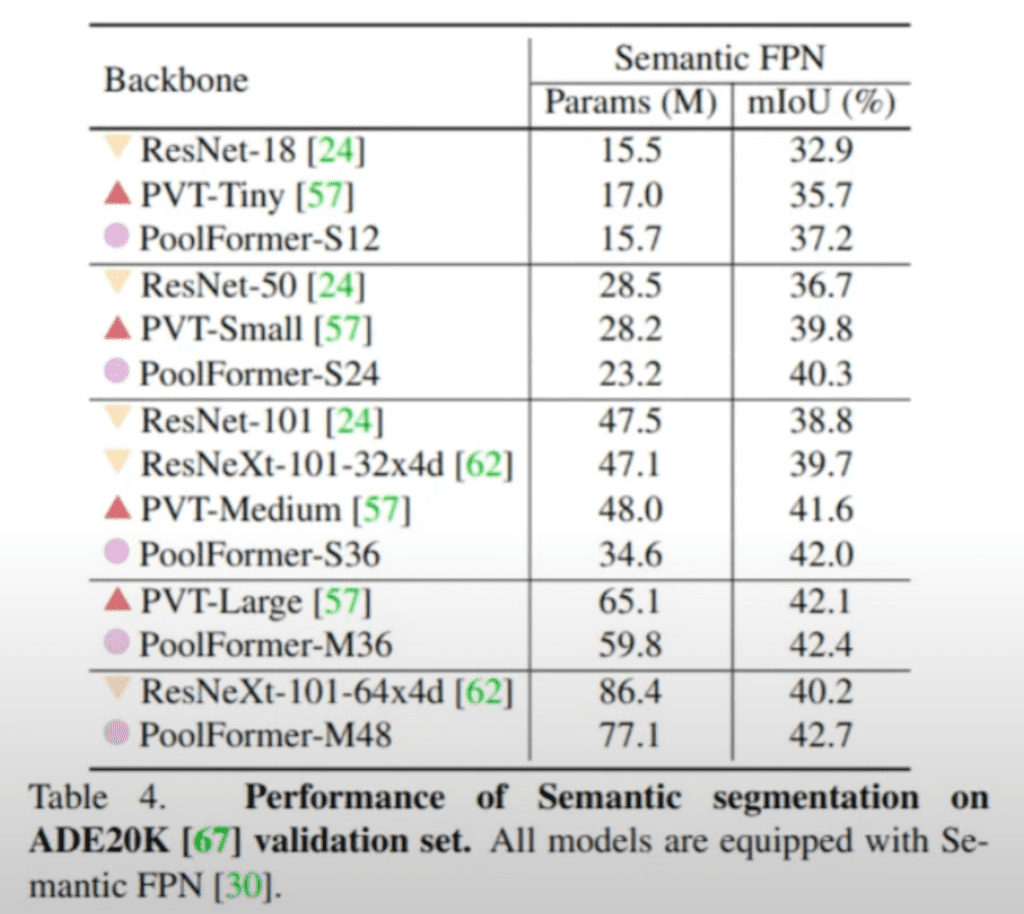
그리고 ADE20 K validation set에서도 PoolFormer 아키텍처를 이용해서 Segmentation을 수행을 했습니다. 그 모델 실험을 수행할 때 Semantic FPN이라는 Segmentation 아키텍처를 이용했다고 밝히고 있습니다.
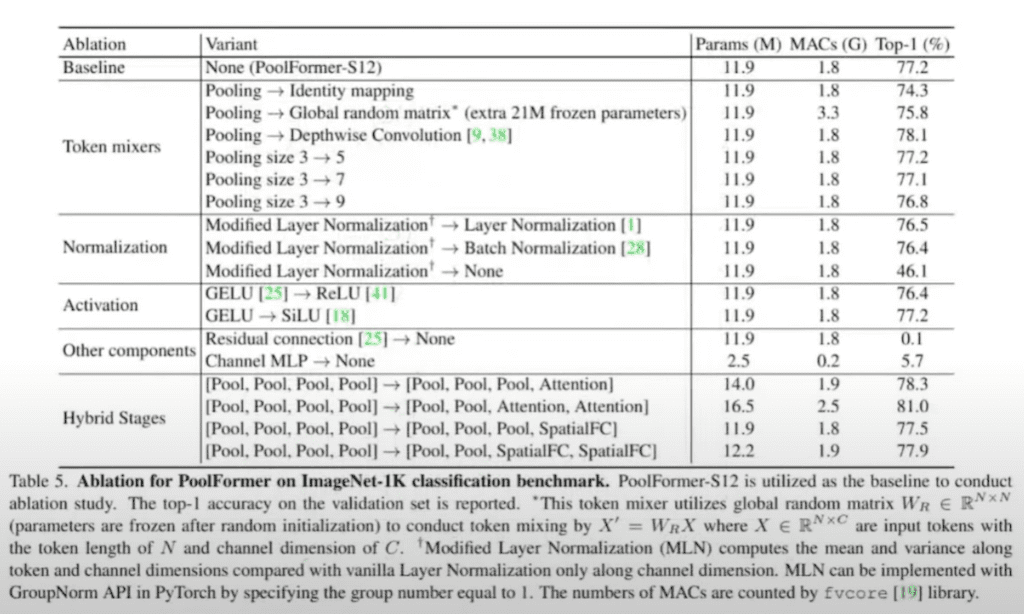
Ablation study 부분이 저자들이 신경을 많이 써서 리뷰를 했습니다.
첫 번째 Ablation study입니다.
Pooling 자체를 Identity mapping. Input 뒤로 똑같이 넘기는 방식을 사용해도 성능이 74% 나온다. 3% 밖에 baseline에서 안 떨어집니다.
MetaFormer라는 구조 자체가 되게 훌륭한 구조라고 저자들은 믿는다라고 이렇게 실험적으로 보여줬고 여기에다가 랜덤 한 token mixing frozen 파라미터니까 따로 학습은 안 했는데 그렇게 하면 조금 성능은 올라갑니다. 앞에서 보셨던 것처럼 average Pooling 자체 사이즈가 3 x 3으로 가져갔기 때문에 사실 이게 non parametric convolution weight랑 bias가 없는 Convolution이랑 똑같다고 봐도 무방하기 때문에 weight를 주면 어떨까 생각을 해서 그런지 depth wise convolution을 썼는데 성능이 0.9% 올라가는 그런 결과를 관측했다고 설명하고 있습니다.
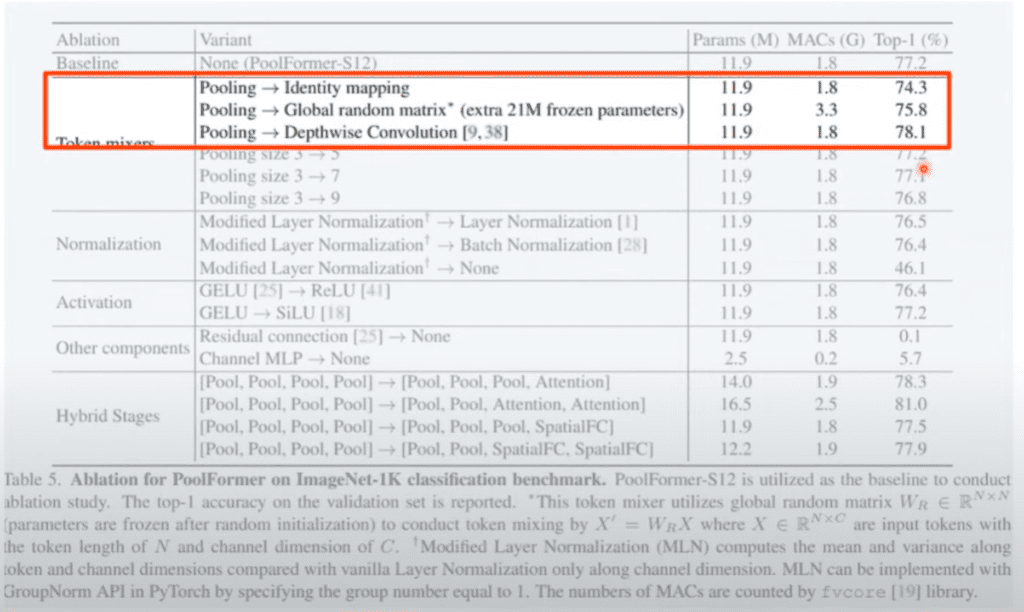
그리고 여기 Pooling 사이즈는 3 x 3에서 5, 7 ,9로 올렸는데 오히려 떨어지는 거를 관측을 해서 Pooling 사이즈는 3으로 했다고 이야기하고 있습니다.
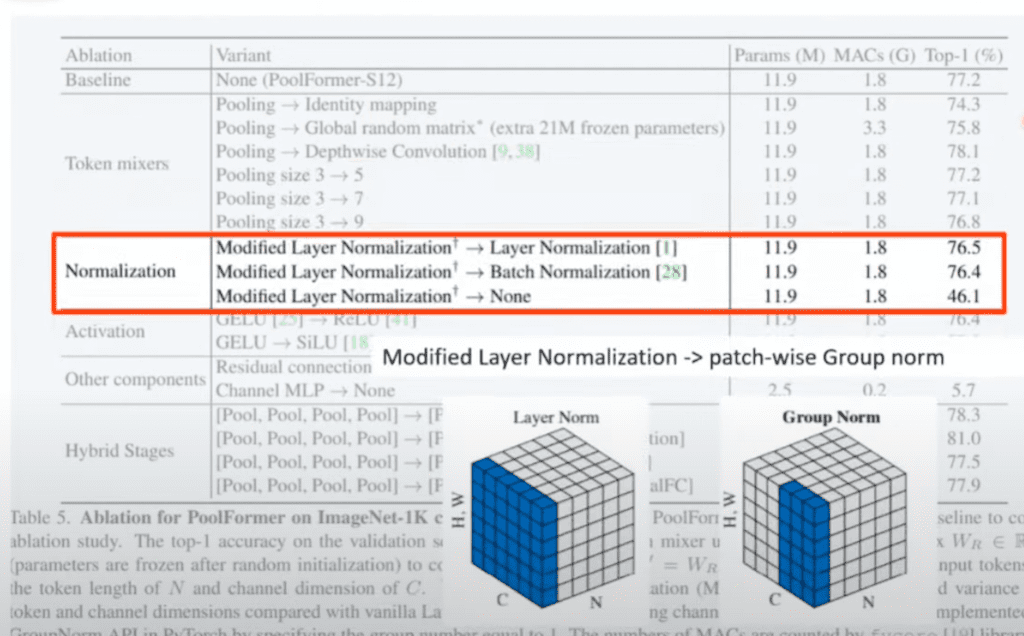
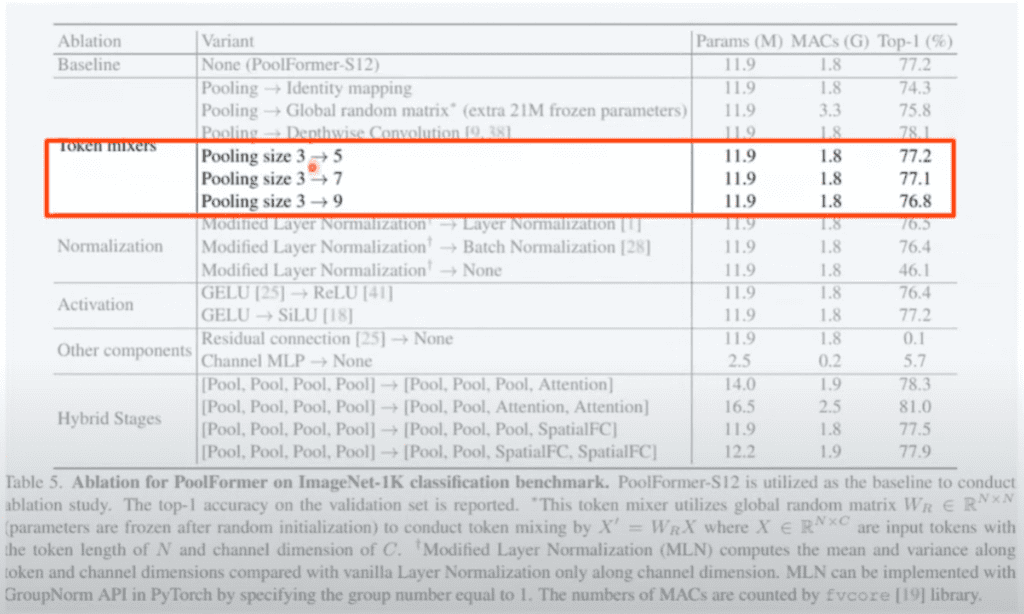
Normalization Layer를 저자들이 Modified layer Normalization라는 것을 사용했다고 밝히고 있습니다. 이게 patch wise group Normalization이라고 저자들은 얘기를 설명합니다. 채널 자체 전체에 대해서 Normalize를 하는 게 어떤 방식이라고 보면 됩니다.
group Normalization은 원래 특정 영역을 그룹 짓습니다. patch 하나가 되어서 patch 하나를 그냥 사용함으로써 Normalization을 했을 때 제일 잘 됐다고 얘기를 하고 Normalization 자체를 없애버리면 성능이 많이 떨어진다라고 얘기를 하고 있습니다.
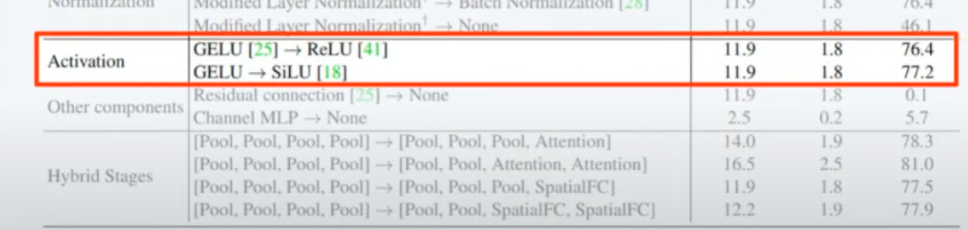
activation 자체는 성능에 크게 영향을 주는 내용은 아닌 거 같다고 이야기하고 있습니다.
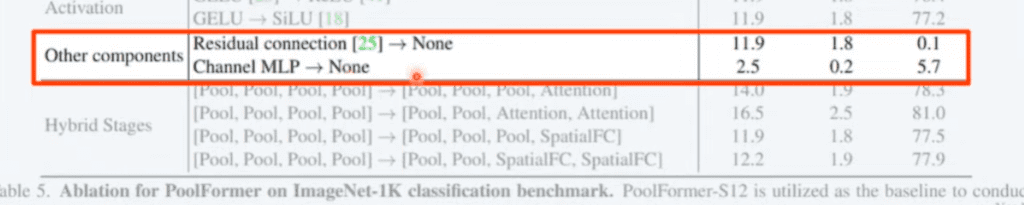
skip connection 부분은 아예 학습조차 안 되는 굉장히 중요한 부분이라고 얘기하고 있습니다. 그리고 채널 MLP 뒤쪽에 Multi Layer perceptron을 없앴을 때도 정확도가 5.7 정도로 아예 안 나오는 그런 수준으로 나왔다고 얘기하고 있습니다.

그래서 Pooling 같은 경우에다가 attention 넣어서 성능이 더 잘 나오는지를 좀 탐색을 해봤습니다. attention을 스테이지 3,4 정도 넣어줬을 때가 성능이 꽤 많이 올라가는 효과를 얻을 수 있었다고 얘기합니다.
attention을 뒤쪽에 넣은 이유는 attention을 해야 되는 요소 수가 많아지면 많아질수록 computational cost가 기하급수적으로 올라가다 보니까 feature map 사이즈 자체가 뒤 쪽으로 가면 갈수록 작다 보니까 작은 feature map 사이에서 attention을 하는 게 좀 부담이 없어서 이런 식으로 좀 설계를 한 거 같습니다.
어쨌든 큰 파라미터 차이나 그런 거 없이 파라미터는 조금 올라가겠는데 Mac 자체는 1.5니까 많이 올라가긴 했는데 그래도 괜찮은 수준에서 성능을 올릴 수 있는 방법이다라고 저자들이 이야기하고 있습니다.
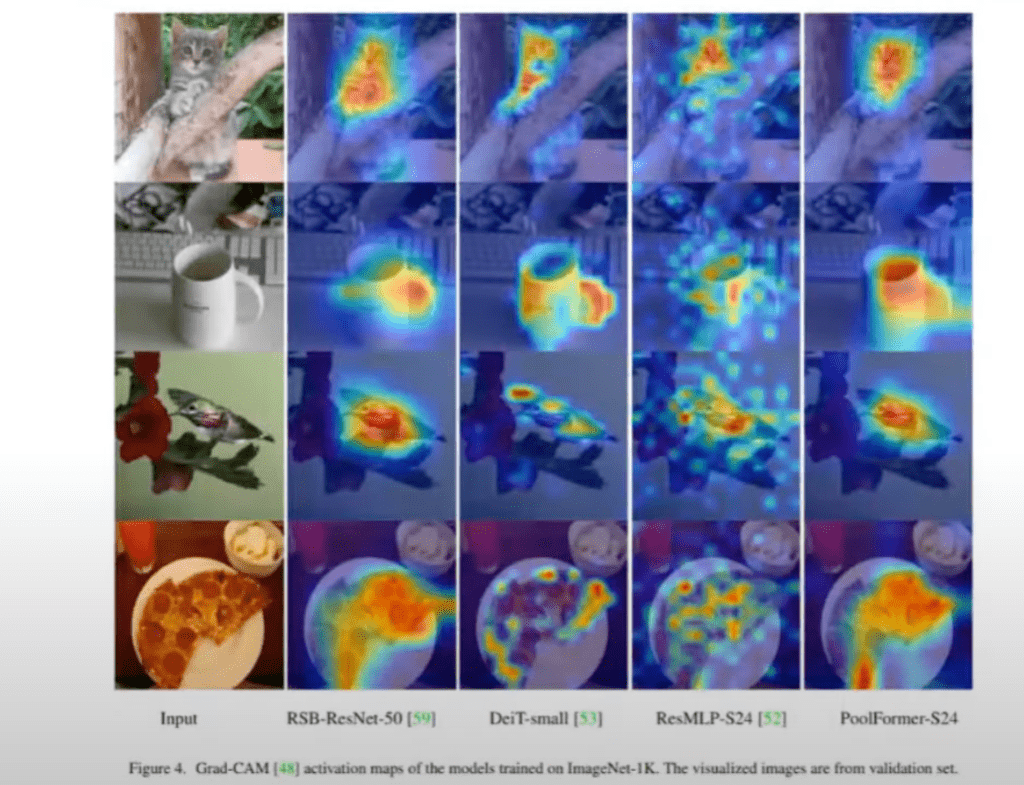
모델 explain ability 자체도 올바른 곳을 바라보고 있다고 Grad-CAM의 결과까지 이렇게 나오고 있습니다.

attention이 ViT모델에서 과연 진짜 불필요한 것인가라고 생각할 때는 여전히 좀 쓸모는 있는 것 같은 부분이 이렇게 attention map을 이용해서 explain ability를 가져가는 부분에 있어서 굉장히 효용성 있다고 생각하고 있습니다.
아무래도 이 attention 자체가 그 Input 이미지 사이즈가 커지면 커질수록 computatioanl cost가 기하급수적으로 올라간다는 단점이 있습니다. 그런 단점을 단순화된 token mixer를 이용하면 충분히 trade off 할 수 있는 그런 방법론이 있다고 방향성을 제시해주는 의미 있는 논문이 아닌가라고 리뷰를 하게 됐습니다.




댓글