안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation'입니다. 이 논문은 ICCV 2021년에 발표가 되었습니다
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation'영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/-ShKE82TSYI)

오늘 발표할 논문인 Simple Baseline에 대해서 먼저 짧게 알아보겠습니다.
Simple Baseline 표현은 다른 분야에서도 간단한 방법론으로 좋은 성능을 달성하는 기본 모델이 되는 그런 모델들을 표현할 때 종종 쓰이는 데이터셋입니다. 오늘 다룰 논문은 Semi supervised 모델이고, 현재 Simple Baseline 모델이 Papers with Code 기준으로는 다섯 번째 정도에 분포하고 있는 모델입니다. 보시면 Semi supervised learning에 대해서 간단히 표현이 되어 있는데 label 된 Data와 unlabel 된 Data를 섞어서 Segmentation 모델을 학습시키는 방법이라고 보시면 될 것 같습니다.

연구를 하는 동기에 대해서 설명드리겠습니다.
이미지뿐만 아니라 여러 가지 딥러닝 모델들을 학습시키다 보면 labeling을 하는데 들어가는 시간적이나 인력적인 노력이 굉장히 크다는 거를 볼 수 있습니다. 위 사진은 테슬라 수석 엔지니어의 발표자료인데 PhD일 때는 모델을 개발하는데 본인의 시간 90% 가까이를 썼다면 테슬라에서 자율주행 모듈 개발 Data를 가공하고 편집하는데 거의 75% 시간을 사용하고 있다고 얘기를 하고 있습니다.

이렇게 굉장히 비싼 Data labeling 작업에 효율성을 더하기 위해서 Weakly Supervised 혹은 Semi supervised라는 광고문들이 많이 제안됐었습니다. Segmentation이나 detection 쪽에서는 Weakly Supervised learning은 이렇게 bounding box나 Segmentation 역시 이미지 안에 어떤 클래스의 물체가 있는지를 제시가 되어 있는 Data를 가지고 하였습니다.
Semi supervised는 일부는 label이 되어 있고 일부는 label이 안되어 있는 형태의 모델을 학습 데이터셋 구성을 사용한다고 보시면 될 것 같습니다.
오늘 내용은 Semi supervised 방법론입니다.

Semi supervised learning을 수행하는 데 있어서 몇 가지 기존 방법론들에 대해서 알아보겠습니다.
첫 번째로 GAN based Approaches입니다. 이 같은 경우는 Input 이미지와 label 이미지가 있고 Input 이미지를 가지고 먼저 Segmentation 네트워크를 학습을 시키고 prediction을 수행합니다. 그리고 Label Map입니다. 두 개 같은 경우에는 cross entropy Loss를 가지고 비교를 해서 학습하게 되는데 여기서 보시는 prediction map이랑 Label Map을 Discriminator 네트워크에 집어넣게 됩니다. 그래서 Confidence Map을 이용해서 조금 더 사실적인 어떤 prediction을 했냐라는 추가적인 Loss를 주게 됩니다. 이를 prediction에 반영해서 조금 더 label이 없이도 학습을 할 수 있는 방법론들을 제안을 하고 있습니다.

그 외에는 Consistency Regularization-based Approaches라고 어떤 Pseudo label을 생성을 해서 학습을 시키는 방법입니다.
기존 방법론 중에 CCT라는 방법이 있었는데 맨 처음에 보시는 첫 번째 라인에서 encoder와 decoder를 label 이미지를 이용해서 학습시키고 그다음에는 추가적인 decoder들을 가져온 다음에 encoder와 decoder를 별도로 연결을 합니다. 그래서 여기서 학습이 된 teacher 모델을 가지고 Pseudo label을 생성한 다음에 조금 더 강한, 일종의 perturbation 즉, 문제를 조금 어렵게 해서 student 모델이 예측한 prediction Map과 teacher 모델이 생성한 Pseudo label을 비교해서 Unsupervised Loss를 학습을 하게 됩니다.
보통은 이런 식의 방법론을 구성한다고 보시면 됩니다.

이 논문은 성능이 좋기로 알려져 있는데 오늘 소개해드릴 논문에는 언급이 안 됐던 거 같아서 설명드리겠습니다.
(a)가 제안된 방법이라고 보시면 됩니다. Cross Pseudo Supervision이라는 방법입니다.
기존 방법론은 그냥 단순하게 teacher 모델이 일방적으로 student 모델을 학습하는 방법이었다면 이 방법은 두 개 모델을 놓고 teacher 모델이랑 student 모델이라고 부르는 것도 어색할 정도로 동등한 입장에서 학습을 수행하게 됩니다. 둘이 만들어낸 prediction Map을 각각의 Pseudo label로 사용하면서 서로서로를 교차하게 label을 구현하는 방식을 소개가 되고 있고 꽤나 높은 성능을 달성한 것으로 알려져 있습니다.

오늘 소개해드릴 Simple Baseline의 특징입니다.
단순한 Semi supervised framework를 제시한다고 보시면 될 거 같습니다. 그 방법론을 구성하는 요소가 Strong Augmentation 그리고 Data Distribution, Specific Batch Normalization입니다.
즉 Data Distribution마다 거기에 최적화되어있는 Batch Normalization layer를 따로 쓰는 그런 방법론을 제안합니다. 그리고 Self Correction Loss를 또 추가적으로 제안을 해서 학습 안정화를 통해 이렇게 크게 세 가지가 본 논문에서 제안하는 가장 중요한 내용들이라고 보시면 될 거 같고 최종적으로는 그때 당시에 SOTA 성능을 달성했었다고 보시면 될 거 같습니다.
baseline DeeplabV3 모델이 68.9%인데 약 6% 정도의 큰 gap으로 성능을 개선한 걸 확인할 수 있습니다.

제안된 내용에 대해서 그림으로 설명을 드리겠습니다.
첫 번째 단계에서는 label 된 Data를 가지고 teacher 모델을 학습시킵니다. 여기서는 Cross entropy Loss를 사용을 합니다. 그렇게 해서 학습들이 일단 끝나게 되면 teacher 모델을 가지고 Pseudo label을 생성하게 됩니다.여기서 생성되는 Pseudo label은 one-hot encoding 형식의 hard label을 생성을 하게 되고 label 생성을 한 것을 student 모델에 입력을 합니다. 이때 student 모델 안에 Batch Normalization이 두 가지 종류가 따로 있습니다. Weak Augmentation에만 대응하는 Batch Normalization layer와 Strong Augmentation에 대응하는 layer입니다.
Unlabel Data는 Strong Augmentation을 거쳐서 student 모델에 입력이 되기 때문에 별도의 Strong Augmentation 전용 Batch Normalization으로 통과가 되고 label된 Data는 Weak Augmentation으로 들어간다고 보시면 됩니다. 그래서 최종적으로 계산되는 Loss는 Cross entropy Loss와 Self Correction Loss로 계산이 되고 한 번 iteration이 끝나게 되면 여기 있는 student 모델을 teacher 모델로 옮겨서 다시 이 과정을 반복하게 됩니다.

위에서 설명한 것들을 알고리즘 표로 요약이 되어 있는 것을 볼 수 있습니다.

Data Augmentation에서 사용된 Augmentation 방법론들은 리스트 화가 되어 있습니다.
대표적인 걸로 보자면 이미지 대비 조절하는 방법론들, 밝기 조절하는 방법론들 그리고 histogram equalization도 있습니다. 그리고 채널을 셔플 하는 방법론도 있었고 노이즈를 추가하는 방법들 그리고 bluring 하는 방법들 그리고 dropout 이미지 내에서 특정 영역을 아예 없애 버리는 그런 방법론들도 있습니다. texture의 손상부터 어떤 매크로 한 feature의 손상까지 굉장히 여러 가지 종류의 Augmentation이 들어간 것을 확인할 수 있습니다.
그에 반해서 기존 baseline Augmentation는 단순한 스케일 조정이나 좌우반전, 랜덤 crop 정도로 있는 것을 보실 수가 있습니다. 그래서 Strong Augmentation에 pipeline을 통과하는 이미지들은 여기 두 가지 종류의 Augmentation을 전부 합한 리스트 중에서 랜덤 하게 선택을 해서 Augmentation을 수행한다고 보시면 될 것 같습니다.

두 번째 Distributiion Specific Batch Normalization입니다.
여기서 Batch Normalization layer를 보통은 이미지 비전 분야에 모델들이 사용을 하게 되는데 원래 있던 Batch Normalization 해서 Strong Augmentation에 대응하는 Batch Normalization layer 하나를 좀 평행하게 배치한다고 보시면 될 것 같습니다
그래서 어떤 Weak Augmentation이 들어올 때는 BN w로 통과시키고 Strong Augmentation 이미지가 들어올 때는 BN s로 통과시키는 방식입니다.
테스트를 할 때는 위에 있는 Weak Augmentation layer만 사용을 하게 됩니다.

Self Correction Loss입니다.
Self Correction Loss는 기존 Crosss entropy Loss를 조금 변형한 형태라고 보시면 됩니다. Self Correction Loss 구성은 Y 가 원래는 label 자리가 되고 그리고 Y가 prediction 자리가 되는데 텀을 가지고 하나를 더 만든 다음에 Y와 Y의 자리를 swap 해 준다고 보시면 될 거 같습니다.
그래서 literal에 나왔던 일종의 상호 보완하는 그런 효과를 가지게 됩니다. 앞쪽에 동적으로 계산되는 가중치가 들어가는데 이 가중치는 픽셀의 소프트맥스 값 중에 가장 큰 값을 가중치로 사용을 하게 되고 뒤쪽에 있는 가중치는 1-로 앞에서 계산된 동적 가중치를 계산한 값으로 사용을 하게 됩니다
여기까지 내용이 전체 framework에 대한 설명이었습니다.

실험 내용입니다.
Pytorch 코드가 깃허브에 공개되어 있습니다. 가서 확인해 보셔도 좋을 거 같습니다.
learning rate 조절하는 policy는 poly로 사용을 했습니다. 그리고 보시는 수식에 따라서 base learning rate를 계속해서 조절하는 식으로 했습니다.
Optimizer는 Stochastic gradient descent를 사용했고, 769 x 769의 Cityscapes Dataset을 이용했습니다.
baseline 모델은 DeepLabV3 Plus입니다. DeepLabV3 Plus를 가지고 계속 실험을 진행하고 그리고 평가지표는 가장 흔한 mIoU로 사용한다고 보시면 될 것 같습니다.
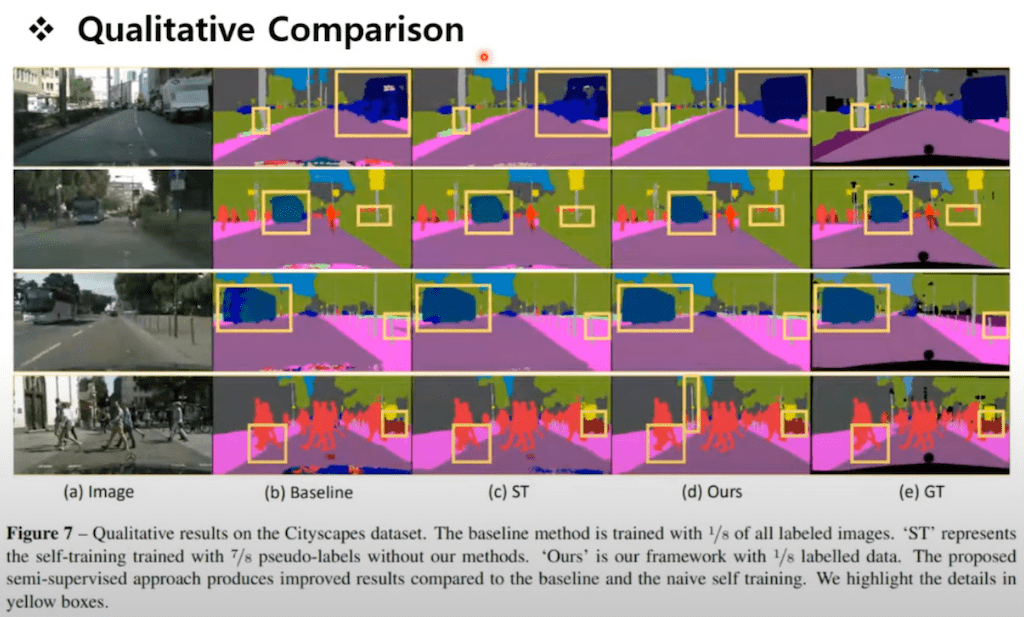
먼저 Qualitative Comparison table입니다. 여기 첫 번째 컬럼이 baseline이고 이렇게 학습 자체가 불완전하게 된 부분들이 상당히 많은 것을 보실 수가 있습니다. 반면에 제안한 방법론이 굉장히 깔끔하게 prediction이 된 것을 확인할 수 있습니다.

Ablation Study입니다.
DeepLab V3에서 점점 논문에서 제안하는 방법론들을 적용을 시켰을 때 얼마만큼 더 성능이 좋아지는지 확인한 테이블입니다.
왼쪽에 mIoU-1/8은 전체 Dataset에서 얼마만큼 비율의 Data에 대해서 label을 가져갔는지를 보시면 될 것 같습니다.
여기 가장 오른쪽에 Full는 Cityspaces 가서 보시면은 fine label이랑 coarse label이 있습니다. coarse label에 있는 것들을 unlabel Data를 사용한 그런 학습 Dataset 구성이라고 보시면 될 것 같습니다.
DeepLab V3 plus 자체가 mIoU 1/8 테스트에서도 68.9%로 아주 낮은 성능은 아니었다 라는 부분이 조금 신기하고 물론 거기에서 어떤 요소를 더 할 때마다 적게는 mIoU에서 1 정도의 꾸준한 상승을 보이는 걸 확인할 수 있습니다. Full 같은 경우에도 DeepLab v3 plus가 기존 baseline 성능이 78.7인데 80.5로 거의 2% 가까운 성능 향상을 가져왔다고 보시면 될 것 같습니다.

그리고 이 테이블은 Data Specific Batch Normalization이 어느 정도 성능을 향상했는지 확인했는데 0.7% 정도의 성능 향상을 가졌습니다.

이 그래프는 참고하시면 좋을 것 같아서 설명드리겠습니다.
Semi supervised Segmentation을 수행할 때 가장 어려운 부분 중에 하나가 뭐냐면 Pseudo label은 신뢰성이 부족해서 학습이 잘 안 된다는 불안정성이 문제가 될 것 같습니다. 그런 경우에는 본 논문에서 제안한 Self Correction Loss가 도움이 된다고 테이블이 얘기를 해주고 있습니다.
초록색 같은 경우에는 SCE Loss를 썼을 때의 그래프입니다. 보시면은 5,000 iteration 후에 갑자기 mIoU 0으로 가라앉는 거를 보실 수 있습니다.
반면에 빨간색 Self Correction Loss 한 학습방법은 잘 된 것으로 확인할 수 있습니다.

Strong Augmentation에 대한 Ablation Study까지 전체 구성 요소에 대해서 어느 정도의 성능 향상을 하는지
저자들이 꼼꼼하게 실험을 했다고 보시면 될 것 같습니다.




댓글