안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer'입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘UCTransNet’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/SFwsc7s_Bww)
진행순서는 논문에서 전체적인 구성을 잘 짜주어서 논문과 같은 순서대로 진행을 하겠습니다.

발표에 앞서 들어가기 전에 전체 논문에서 제안했던 모델에 대해서 보고 넘어가겠습니다. U-Net과 비슷한 구조에다가 Skip connection이 Transformer 베이스의 모델로 대체된 것을 확인할 수 있습니다. 그리고 추가적으로 decoder에 만나기 전에 한번 더 가공하는 모듈이 추가되어서 U-Net 구조에다가 CCT와 CCA 두 가지 모듈을 통합해서 제안한 모델을 이야기하고 있습니다.

논문에서는 encoder와 decoder Skip connection의 역할이 있다고 이야기를 하고 있고 encoder는 low level과 high level feature들을 모아주고 decoder는 semantic feature들을 하나의 목표 결과물로 모아주고 average pooling이나 max pooling과 같은 과정을 통해서 사라지는 spatial information을 회복하는데 도움을 준다고 얘기를 하고 있습니다.
그런데 이 세 가지 역할이 뚜렷하게 나눠져 있기 때문에 두 가지 semantic gap이 생긴다고 이야기하고 있습니다. 첫 번째로는 여러 가지 resolution에 multi-scale encoder feature들이 사이에 Semantic gap이 있다고 이야기하고 있습니다.
두 번째로는 encoder와 decoder 사이에서 Semantic gap이 발생하고 있다고 이야기하고 있습니다. 이러한 feature들을 어떻게 하면은 더 효과적으로 그리고 효율적으로 잘 섞어 줄 수 있는지 초점을 맞춰서 모듈을 개발했습니다.

이전에 어떤 식으로 Semantic gap을 줄이려고 모델이 발전해 왔는지 보겠습니다.
Unet++ 는 Skip connection 구조를 dense path로 대체를 해서 Semantic gap을 줄이려고 했습니다.
두 번째로 MultiResUnet은 Skip connection을 residual을 합쳐서 좀 더 강화하는 식으로 Semantic gap을 줄이려고 했습니다.
두 가지 한계는 Unet++ 는 same scale feature만 섞어주는 것으로 마쳤고 MultiResUnet는 어느 정도는 밸런스를 맞췄지만 조금 부족하다고 이야기하고 있습니다.
그래서 논문에서는 Multi scale의 feature들을 섞어 주는 것이 정말로 중요하다고 이야기를 하고 있습니다.

그래서 결국은 어떻게 Semantic gap을 encoder와 decoder 사이에서 줄일 것인가 그리고 multi scale channel wise information을 non-local semantic dependencies.
Convolution이 아니라 Transformer 계열의 모듈로 어떻게 만들 것인지 고민을 하였고 그래서 그 고민의 결과로 Skip connection을 대체할 수 있는 하나의 모듈을 제안했습니다.
모듈은 크게 두 가지로 나누어지고 CCT와 CCA 두 모듈을 전반적으로 채널에 집중해서 만들어진 모델이라고 이해하시면 될 것 같습니다.
논문에서 contribution이라고 이야기를 하는 것은 어떻게 보면 Skip connection의 잠재되어있던 단점을 안 보고 개발을 해왔었는데 이 부분에 대해서 우리가 다 파헤쳐 봤다는 것과 그다음에 channel wise 한 perspective로 segmentation의 퍼포먼스를 올리기 위한 것의 contribution이 있었다고 하고 그리고 less computational cost로 높은 성능을 가져왔다고 이야기를 하는데 이 부분 같은 경우에는 뒤에서 한번 더 설명해 드리겠습니다.

이 모델이 나오기까지 어떤 모델이 있었는지 한번 살펴보겠습니다.
첫 번째로 TransUNet 그리고 Swin-Unet 같은 경우에는 Vision Transformer가 크게 유행하면서 제안된 모델들입니다. TransUNet 같은 경우에는 CNN과 vision Transformer를 합쳐서 UNet 구조를 개선하였고 Swin-Unet은 Swin Transformer block을 decoder까지도 만들어주면서 성능을 올려서 다양한 데이터셋의 SOTA를 달성하고 있는 모델입니다. 여기 base 모델의 아쉬운 점은 Convolution의 단점 자체에만 집중을 하다 보니까 UNet 구조에 대해서 고민을 덜 했다고 이야기를 하고 있습니다.

두 번째로 Skip connection 베이스로 모델을 개발한 모델들입니다.
처음에 Attention Unet 같은 경우에는 encoder에서 quick connection 해서 들어가기 전에 1 * 1 * 1 Convolution을 활용을 해서 얼마나 이런 feature들이 더 효과가 있는가 대해서 sigmoid로 전달해 주어서 유용한 feature들만 남기는 추가적인 attention Gate를 제안했습니다.
R2U-Net 같은 경우에는 residual를 여러 가지 방면으로 실험한 논문입니다. recurrent를 Convolution에도 넣거나 Convolution을 recurrent를 넣은 채로 진행하는 실험을 한 논문입니다.

Dense UNet이나 UNet3+같은 경우에는 block을 Dense block으로 바꾸거나 decoder도 dense path로 구성하였습니다. 이런 모델의 아쉬운 점은 Skip connection들이 동일하게 전체적으로 좋은 성능 향상에 Contribution이 있을 것이다라는 가정에서 만들어졌던 거를 단점으로 꼽고 있습니다.
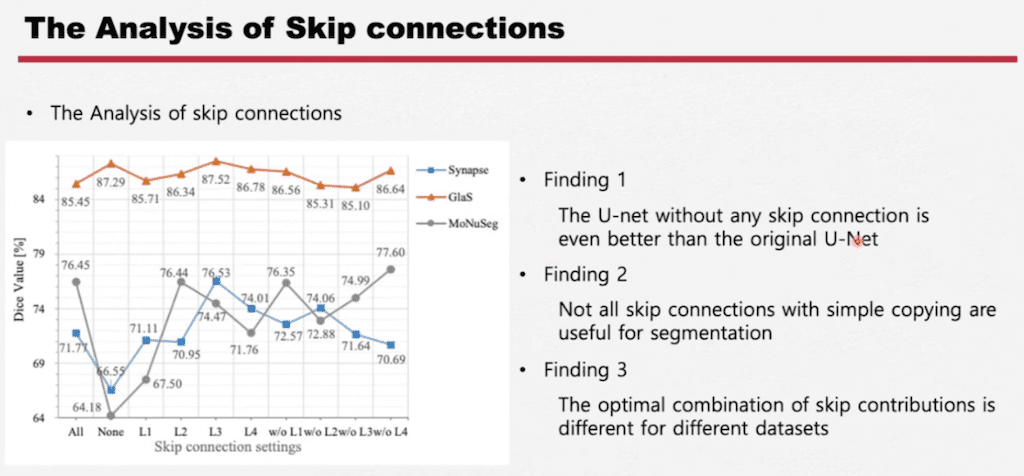
Skip connection에 대해서 한번 좀 자세하게 살펴보겠습니다. 유명한 데이터셋 3가지를 가지고 실험을 진행했습니다.
- Skip connection이 하나도 없는 게 오히려 Skip connection이 있는 거보다 좋은 데이터셋이 있더라 라는 것을 찾았습니다.
- Segmentation의 Skip connection이 항상 좋은 것이 아니다 즉, copy 방식의 Skip connection이 항상 좋은 것이 아니다.
- 다른 데이터셋마다 Skip connection의 조합이 다 다르다. 당연한 말이지만 뒤에서는 좀 더 구체적으로 분석한 데이터도 있습니다.

UCTransNet의 두 가지 모듈에 대해서 살펴보겠습니다.

처음으로 Multi scale feature를 어떻게 하나로 모아 줄지에 대해서 Transformer 모듈을 생각을 했고, 그다음에 Transformer 모듈에 들어가기 위해서 Tokenization이 진행됩니다.
여기에서 조금 이전에 Transformer 계열의 모델과 가장 다른 점은 vision Transformer나 아니면 Swin Transformer 같은 경우에는 Spatial 한 정보를 패치 단위로 보고 그 부분을 Tokenization 하는 방식으로 바라보게 되는데 여기 CCT 모듈 같은 경우에는 채널에 대해서 좀 더 집중적으로 보겠다는 관점으로 접근을 했기 때문에 채널의 데이터를 Tokenization을 하게 됩니다.
그렇게 하기 위해서 모델 resolution을 동일하게 만들어 주는 패치를 다른 resolution마다 각각의 다른 패치를 적용을 해서 resolution을 맞추게 되고 그 부분에 채널 부분만 Tokenization을 해서 Transformer 모델에 들어가게 됩니다.

Multi head Cross Attention 모델에 대해서 좀 더 살펴보겠습니다.
dimension은 Tokenization이 진행되면서 모두 동일하게 되고 채널만 이렇게 남게 되는데 이 부분이 Linear layer를 거쳐서 query, key, value가 만들어지고 key나 value 같은 경우에는 조금 독특하게 모든 채널의 concat을 key, value로 적용하게 됩니다.
Cross Attention mechanism는 Attention is all you need에 나온 Transformer와 동일한데 이미지라서 좀 다른 점은 instance Normalization을 사용한다는 점입니다.
그리고 두 번째로는 Attention is all you need에서는 multi head attention을 할 때 어떤 dimension을 잘라서 연산의 효율성을 위해서 dimension을 자른 다음에 여러 개 head에 Transformer를 거치고 나중에 concat 시키고 linear layer를 만들어서 동일한 임베딩을 만들어주지만 여기에서는 Cross attention mechanism을 여러 개를 정말 태우고 그 부분에 평균값으로 Multi head Cross attention을 진행합니다.
그 이유는 논문에서는 채널의 관점에서 바라보고 모듈이 진행될 때 스무스한 업데이트를 원한다고 해서 이 평균값으로 업데이트한다고 이야기를 하고 있습니다.
최종적으로는 MCA를 query와 더해서 MLP를 지나고 그 부분을 더해서 아웃풋으로 출력하게 됩니다.

두 번째로는 CCA 모듈입니다.
이 모듈 같은 경우에는 이미지 쪽을 아시면 조금 익숙할 수 있는 Squeeze Excitation과 비슷하다고 느꼈습니다. 여기서 encoder CCT 모듈에서 나온 아웃풋을 Global Average Pooling을 해서 각각의 채널마다 얼마나 중요한지에 대해서 바라보는 모듈입니다. 그 부분에 decoder까지 같이 합류하게 되면서 encoder와 decoder의 어떤 부분의 채널을 더 중요시할 것인가 이 부분이 고려된 모듈이라고 생각하고 있습니다.

실험입니다.
데이터셋 같은 경우에는 크게 세 가지 있습니다.
- MoNuSeg는 1000 x 1000 큰 이미지가 7개 organs에서 세포핵을 segmentation을 하는 task입니다.
- GlaS는 염색을 해서 세포를 현미경으로 바라본 데이터셋입니다. 위장의 조직 검사 데이터셋이고 165개 데이터, 그리고 픽셀마다 0.465 마이크로미터입니다.
- Synapse 데이터셋은 512 x 512 x 85 512 x 512 x 198로 3D 데이터셋입니다. 여섯 개 organ에 대해서 6가지 organ을 segmentation 하는 task입니다.

정량적인 지표입니다.
GlaS나 MoNuSeg 같은 2D에서 굉장한 복잡도를 가진 데이터셋에서는 UCTransNet이 Swin Unet보다 조금 더 좋은 성능을 보여주고 있지만 Synapse 같은 CT 데이터에 대해서는 Swin Unet이 여전히 SOTA를 유지하고 있습니다.

정성적인 평가입니다.
단순하게 groundtruth를 보고 다른 모델의 결과를 다 봤더니 UCTransNet의 결과가 가장 깔끔하고 좋았다고 이야기를 하고 있습니다.

CCT와 CCA 각각의 모듈이 UNet에서 추가될 때마다 각각의 데이터셋이 어떻게 성능이 올라가는가를 보여주고 있습니다.
그다음에 두 번째 Ablation study로는 query랑 key가 들어갈 때마다 어떻게 성능이 바뀌는지 봤을 때 이 회색이 모든 encoder feature들이 query로 들어갔을 때 결과입니다.
Q1이 첫 번째 레이어의 encoder feature만 들어갔을 때, Q12가 첫 번째 두 번째 encoder에 feature만 들어갔을 때입니다.
GlaS 데이터셋은 전체 모든 query를 넣었을 때 보다 2, 3, 4 번째 query만 넣었을 때 약간 더 좋았다고 이야기를 하고 있습니다. 동일하게 key에 대해서도 몇 번째를 넣을까에 대한 데이터입니다.

그리고 CCT 모듈에서 어떻게 similarity가 나오는지에 대한 부분입니다. 이 부분은 다음장에서 Skip connection을 파헤쳤던 것과 비교하면서 보면 좀 더 쉽습니다.
GlaS는 depth가 세 번째에서 가장 유사한 similarity가 나오는 걸 확인할 수 있습니다. 동일하게 GlaS 데이터셋에 대해서 layer 세 번째 거를 뺐을 때 가장 낮은 것을 확인할 수 있습니다. 그리고 가장 similarity가 높은 레이어에서만 Skip connection을 넣었을 때 성능이 가장 좋은 것을 확인할 수 있습니다.
MoNuSeg도 layer depth가 2일 때, layer 두 번째가 빠졌을 때 가장 성능이 떨어지는 것을 확인할 수 있고, layer 2가 들어갔을 때 성능이 이것만 들어갔는데도 성능이 굉장히 높게 나오는 것을 볼 수 있습니다.
Skip connection에 대해서 실험을 할 때 데이터셋마다 combination이 다 다르다, contribution에 대한 combination이 다르다고 했는데 그 부분이 실제로 데이터셋마다 이렇게 시각화하고 해석 가능하게 표현할 수 있는 모델이 되었습니다.

결론입니다.
- Channel Transformer(UCTransNet)을 제안을 했다는 것을 이야기를 하면서 channel-wise 한 perspective를 제안했다.
- SOTA를 달성했다.
- Semantic gap을 정말 효과적으로 줄였다는 점을 장점으로 이야기하고 있습니다.




댓글