안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/NjJXGRDzsYk)

Paper with Cdoe에 리더보드를 보면 최근 detection task에서 Transformer 기반의 모델들이 SOTA를 달성하고 있는 것을 알 수 있습니다. 이러한 수많은 Transformer 구조를 가진 vision task의 모델들은 vision Transformer 해당 논문이 시작점인 것을 말씀드릴 수 있습니다.
그만큼 논문에서는 Image classification 문제를 풀고 있는데 Image classification 문제뿐만 아니라 다른 task에서도 Transformer의 기반의 Architecture를 적용하게 된 수많은 논문에 많은 영향을 끼친 매우 중요한 논문입니다.

먼저 ViT에 대해 설명을 드리기 전에 Attention과 Transformer의 기본 개념인 Self-Attention 개념에 대해서 설명해 드리도록 하겠습니다. Attention을 encoder와 decoder 사이에 correlation을 바탕으로 특징을 추출해 나가는 과정을 의미합니다.
NLP task에서는 attention 같은 경우에는 해당 이미지의 연관성 있는 단어를 좀 더 집중하게 하는 것이 목적이라고 할 수 있습니다. Self-Attention 같은 경우에는 입력 데이터로부터 key, query, value를 모두 계산하고 데이터 간의 관계성 연산 결과를 활용해서 연관성이 높은 단어끼리 연결해 주기 위해서 활용하는 것입니다.
그래서 데이터 간의 얼마나 서로 attention을 하는지 이런 것이 주요한 목적입니다. ViT는 encoder만 사용했는데 Transformer encoder에는 Self-Attention 메커니즘을 사용하였습니다.

CNN과 Transformer의 차이에 대해서 설명을 드리기 위해 inductive bias에 대해서 먼저 이해를 해야 됩니다.
inductive bias란 새로운 데이터에 대해 좋은 성능을 내기 위해 모델에게 사전으로 주어지는 가정을 의미합니다. 일반적으로 머신 러닝에서 특정 데이터셋의 좋은 성능을 얻고자 inductive bias를 의도적으로 강제합니다. 예를 들어서 CNN 같은 경우에는 지역적인 정보를 추출하는 것이 중요하다는 가정을 반영하기 때문에 CNN 모델의 Convolution이라는 방법을 사용하게 되고 RNN는 현재 타임 데이터는 이전 데이터에 강하게 Correlated 되어 있고 데이터에 순차적인 정보가 중요하다는 정보를 RNN 모델 설계 시 반영되어 있습니다.
그러나 Transformer 같은 경우에는 Self-Attention 즉, 각 데이터에 대해서만 Correlated 되어 있기 때문에 CNN과 RNN에 비해 상대적으로 inductive bias가 낮다는 것을 말씀드릴 수 있습니다.

CNN과 Transformer의 가장 큰 차이점은 지역적인 정보를 유지하느냐, 얼마나 유지하느냐를 큰 차이점이라고 말씀드릴 수 있습니다. CNN은 여러 개의 layer를 거치며 2차원의 지역적인 특성을 유지하기 때문에 학습 후 웨이트를 고정한다고 합니다.
반면에 Transformer 같은 경우에는 Self-Attention layer 하나만 거쳐도 멀리 떨어진 정보들을 교환할 수 있고 Transformer는 데이터를 1차원으로 만들고 Self-Attention을 통해 layer를 통과하게 되고 이 과정에서 2차원의 지역적인 정보를 유지하지 않는다고 합니다.
그래서 웨이트 같은 경우에는 인풋에 따라 유동적으로 변화합니다. 그래서 CNN에 비해 inductive bias가 적은 모델이라고 말씀드릴 수 있습니다. 그래서 ViT 저자들은 데이터가 많은 상황에서는 inductive bias가 오히려 방해물이 된다고 주장을 하고 있습니다. Transformer 기반의 모델은 inductive bias가 적기 때문에 데이터가 많은 상황에서 CNN보다 좋은 성능을 낼 수 있다고 주장을 하고 있습니다.

Transformer 구조가 자연어처리 부분에서는 거의 표준이 되고 있습니다. 그래서 vision task에서도 ViT 이전에는 다양한 적용 사례가 있었습니다.
그러나 vision 분야에서 attention은 Convolution 네트워크와 함께 적용이 되거나 Convolution 네트워크에 특정 요소만 대체하기 위해서 사용이 되었습니다. 이 논문은 이러한 CNN에 의존을 좀 버리고 순수하게 Transformer를 곧바로 Image patch들을 사용하여 적용을 하자 이러한 목적으로 만들어졌고 그런 게 잘 작동됨을 증명한 모델입니다.

저자들이 제안한 ViT Architecture에 대해 오피셜 코드는 아니지만 이해가 쉽게 풀어놓은 파이토치 코드와 함께 ViT 구조에 대해 설명하겠습니다.
ViT 주요 특징은 이미지를 patch로 분할 후 sequence 입력하는 구조를 가지고 있다는 것입니다. NLP의 단어가 Transformer에 입력되는 범주와 동일한데 논문의 제목이 Image is Worth 16x16 Words인 이유이기도 합니다.
ViT Architecture에 대해 단계별로 간략하게 설명드리면 이미지를 먼저 16x16 patch로 분할하고 linear projection을 통해 Flatten 한 vector를 디차원으로 변환하고 patch embedding을 사용하게 되고, class embedding과 patch embedding의 position embedding을 더하게 되고 이 아웃풋의 Transformer encoder에도 class embedding에 대한 아웃풋인 Image representation을 도출을 하고 이것을 MLP Head에 넣어서 클래스를 분류하게 됩니다.
이 patch를 나눠서 embedding 되는 부분부터 설명을 드리도록 하겠습니다

고양이 사진으로 한번 구현을 해봤습니다. Transformer 인풋값은 1차원 Sequence이고, 따라서 고정된 크기의 patch로 나눠준 뒤에 1차원의 sequence로 Flatten 해야 된다고 합니다. 그래서 수식을 표현하면 채널의 형식을 n 즉, patch 크기 x 채널로 변환하게 됩니다.
그래서 16픽셀로 patch 사이즈를 정의를 하고 다음에 n은 이미지 크기인 224 x 224를 16 x 16으로 나눠준 196이 patch 수가 됩니다.

이 부분이 linear projection과 클래스 토큰에 대해서 설명을 드리겠습니다. 이렇게 1 dim vector로 만들어진 patch들의 linear projection을 통해서 16 x 16 768차원의 각 patch들의 embedding vector로 표현하고 각 patch embedding의 클래스 토큰, position embedding을 추가하게 됩니다.
그래서 Flatten 한 patch를 학습 가능한 linear prediction을 사용해서 모든 linear에서 동일한 data to vector사이즈인 차원으로 맵핑을 하게 됩니다. 보시면 클래스 토큰은 classification을 사용하기 위해서 사용되는 토큰입니다.
BERT의 클래스 토큰처럼 학습가능한 embedding patch로서 layer 0 번째 토큰이고 맨 앞에 붙는다고 합니다. 그래서 이거를 add 하고 나면 196개 patch였는데 197로 바뀌는 것을 볼 수 있습니다.

position embedding 모듈입니다.
각 patch의 위치 정보를 제공하기 위해 추가적으로 각 위치별로 학습가능한 positional embedding을 적용하게 되고 positional embedding을 197 x 766 크기로 각 patch의 순서를 모델에게 알려주는 역할을 합니다.
그래서 NM 파라미터로 정의 가능하고 그래서 클래스 토큰과 position embedding 모두 학습가능한 파라미터다라는 것을 말씀드릴 수 있습니다.

여기까지가 patch embedding 클래스에 대해서 설명을 드렸습니다.

Transformer encoder입니다.
Transformer encoder는 모든 블록 전에 이렇게 LayerNorm이 적용이 되고 그다음에 MultiHead로 구성이 되어 있고 다음에 MLP block, 모든 블록 끝에 이렇게 residual connection을 적용하게 됩니다.
기존 Transformer와 다른 점은 기존 Vanilla Transformer 같은 경우에는 attention과 MLP이후에 LayerNorm이 들어갔는데 ViT 같은 경우는 attention과 MLP 이전의 LayerNorm을 수행하게 되고 깊은 layer에서도 학습이 잘되게 하였다고 저자들은 주장을 하고 있습니다.

Multi head attention 부분입니다.
Multi head attention은 attention 메커니즘을 병렬로 처리할 수 있게 한 모듈입니다. ViT에서 Multi head attention을 key, query, value가 같은 텐서로 입력이 되고 embedding 된 입력 데이터를 받아서 다시 embedding 사이즈로 linear prediction 하는 layer를 세 개를 만들게 되고 그다음에 입력 텐서를 query, value로 만드는 각 layer는 훈련 과정에서 학습이 됩니다.
그래서 각 linear prediction을 거친 key, query, value를 re-arrange를 통해서 여덟 개의 Multi head로 나눠주게 됩니다.

그리고 query와 key를 dot PRODUCT 하고 softmax를 취함으로써 둘의 연관성을 구하고 softmax를 취하기 전에 attention score를 scaling factor로 나눠주게 되는데 attention score값이 커지게 되면 기울기 변화가 없게 되는 gradient vanishing을 막기 위해서 나눠주게 되고 scaling을 해준 뒤에는 attention score와 value를 내적을 하게 되고 embedding 사이즈와 re-arrange를 통해서 Multi head attention 아웃풋이 나오게 됩니다.

Multi layer Perceptron 부분입니다. MLP 같은 경우는 linear, GELU, Dropout, linear순으로 진행이 되게 됩니다. 이렇게 두 개의 linear layer가 있는 것을 보실 수 있고 첫 번째 layer에서 expansion을 곱해준 만큼 embedding 사이즈를 확장하게 되고 GELU와 Dropout의 두 번째 linear layer에서 다시 embedding 사이즈로 축소를 하게 됩니다.
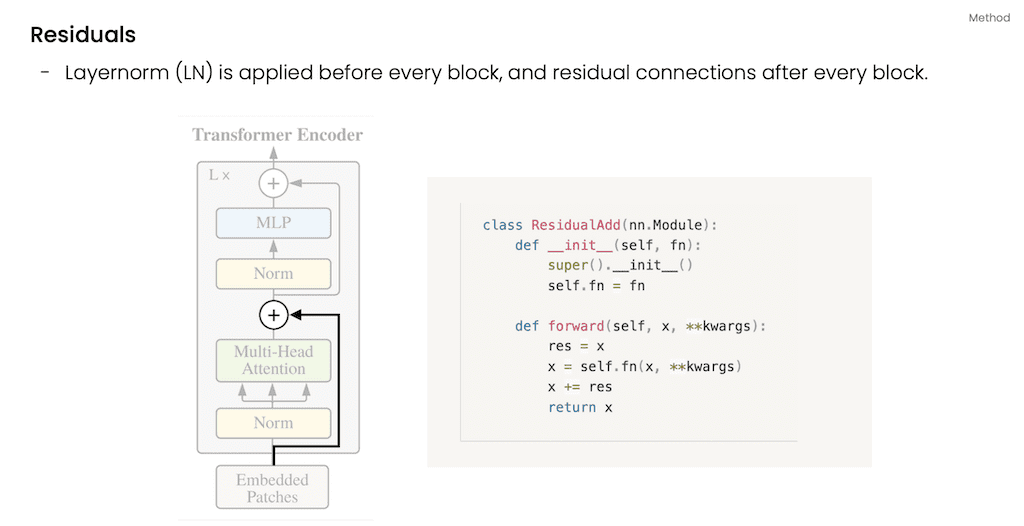
그리고 attention과 MLP 앞에 Normalization을 먼저 수행하게 되고, 그리고 Skip connection을 각각 들어가게 됐다고 설명합니다.

마지막으로 head layer는 classification을 위한 layer이고 전체 sequence에 대해 평균을 낸 후 embedding 사이즈에 1차원 vector로 projection 후 LayerNorm과 linear를 거치게 됩니다.

그래서 앞서 말씀드린 patch embedding , Transformer encoder 그다음에 classification를 적용을 해서 ViT 전체 Architecture를 만들 수 있습니다.
위 그림은 코드를 model summary 한 것입니다.

실험입니다.
ViT 모델은 이렇게 크게 세 가지로 구성이 되어 있고 이렇게 Base, Large, Huge 세 가지로 구성이 되어 있고 실험을 위해 비교한 대상은 BiT입니다.
그리고 Noisy student를 비교를 하였고 다른 논문과 같이 가장 좋은 성능을 냈다고 주장을 하고 있습니다. 그래서 큰 데이터셋에 대해서 pre train 한 vision Transformer는 ResNet의 다른 베이스라인보다 좋은 성능을 내었다고 주장을 하고 있습니다.
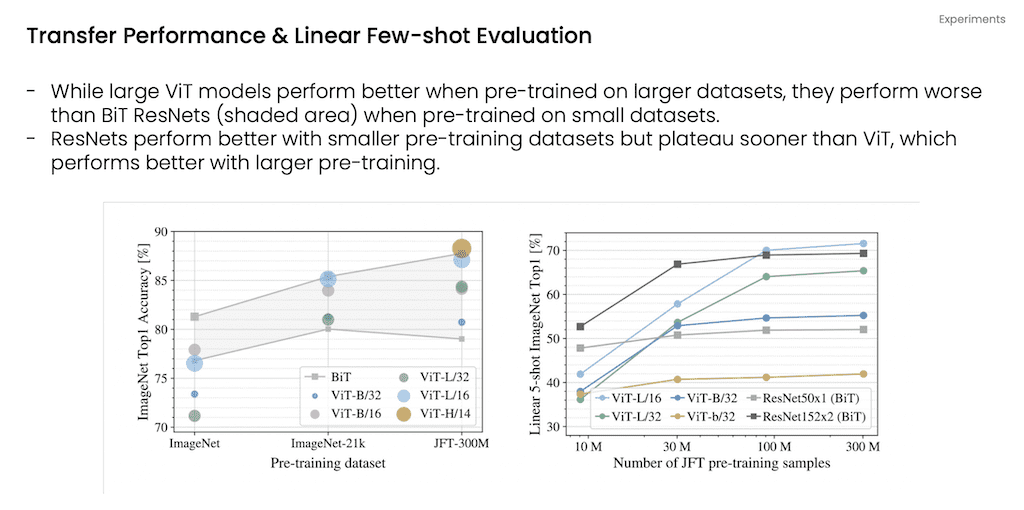
그리고 이 그래프는 Transfer learning 설정의 결과와 Few shot 설정의 정확도라고 말씀을 드릴 수 있습니다.
왼쪽 그래프는 작은 모델이 아까 말씀드린 모델 중에 B는 작은 모델인데 이것보다 살짝 큰 모델인 L이랑 비교를 하자면 작은 데이터셋에서는 작은 모델이 더 높은 성능을 내다가 데이터셋이 커질수록 점점 L모델이 B모델보다 좋은 성능을 내고 있다는 것을 보여주고 있습니다.
오른쪽에 그래프는 Few shot 설정의 정확도입니다. 비슷한 경향성을 보여주는데 데이터셋이 적은 경우에는 기존 모델인 BiT가 성능이 좋았지만 데이터 양이 많아지면 ViT가 성능이 우세한 것을 볼 수 있습니다. 그래서 작은 데이터 셋의 경우에는 BiT가 Resnet 기반의 모델들보다 빨리 overfit 되는 경향이 있는 것을 보여주는 그래프입니다.

추가적으로 vision Transformer의 데이터 처리 방법을 이해하기 위해 internal representation 논문에서는 확인을 했는데 학습이 끝난 position embedding의 경향성을 보여주고 있습니다.
각 patch의 위치에 해당하는 position embedding을 다른 position embedding의 유사도를 구해봤을 때 가까운 위치일수록 유사도가 높은 경향을 나타난다는 것을 visualization 하였습니다.
다음에 오른쪽 그래프는 Self-Attention을 활용한 전체 이미지 정보의 통합 가능성을 확인한 거라고 말씀을 드릴 수 있습니다. 그래서 attention에 가중치 기반으로 이미지 스페이스의 평균 거리를 계산을 했고 attention distance 같은 경우는 receptive field를 의미를 합니다. 이는 낮은 layer의 Self-Attention head는 CNN처럼 Localization 효과를 보인다는 것을 나타내고 있습니다.

결론입니다.
ViT는 기존 Transformer 기반의 모델처럼 파라미터 한계가 아직 없다는 것을 말씀드릴 수 있고 더 많은 데이터와 더 많은 파라미터로 더 좋은 성능을 보여줄 수 있습니다.
그리고 ViT는 CNN, RNN과 다르게 공간에 대한 bias가 비교적 적고 그로 인해서 사전 데이터 학습이 많이 필요합니다. 그래서 많은 데이터를 사전적으로 학습해야 되고 더 적은 데이터로 학습 시에는 성능이 나빠지는 특징을 가지고 있습니다.
그래서 아직 vision task에 Transformer에 대한 효용성에 여러 가지 의견이 많이 나오고 있습니다.
그리고 Transformer 기반에 더 좋은 성능의 모델들이 많이 나오고 있지만 그 시초가 되는 ViT를 공부하는 것은 다른 모델들을 이해하는데 많은 도움이 되었다는 개인적인 의견이 있습니다.




댓글