안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘PseCo’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/C-NVH6StFQw)
현재 Semi-Supervised Object Detection on COCO 5%, 10%, 100% label 데이터에서 SOTA를 달성하고 있는 논문입니다.

먼저 Introduction입니다. 기본적인 내용부터 간단하게 짚고 넘어가도록 하겠습니다. label 종류에 따라서 학습 방법으로 Supervised learning, UnSupervised, Semi-Supervised, Weakly-Supervised learning이 있습니다.
Supervised learning 같은 경우에는 이미지와 annotation이 모두 매칭 되어 있고, UnSupervised learning 같은 경우에는 반대로 이미지만 존재하고 있습니다. Semi-Supervised learning 같은 경우에는 소량의 label데이터와 대량의 unlabel 데이터로 학습을 진행을 하게 됩니다. Weakly Supervised learning 같은 경우에는 타깃으로 하는 task의 annotation이 아닌 다른 label을 가지고 학습을 진행하는 방법이라고 생각하시면 되겠습니다.
오늘 발표드릴 논문은 Semi-Supervised learning을 활용한 Object detection 논문입니다.

저자는 기존의 Semi-Supervised learning의 대표적인 방법인 Pseudo labeling과 Consistency 트레이닝 방법에 대해서 얘기를 합니다.
Pseudo labeling 경우에는 label 데이터를 가지고 teacher 모델을 학습을 하게 됩니다. 그리고 unlabel 데이터를 바탕으로 학습된 teacher 모델에 Inference를 진행하게 되고 Inference의 결과를 Pseudo label로 활용을 합니다. 이렇게 생성된 Pseudo label 데이터와 label데이터를 활용해서 student 모델을 최종적으로 학습하여 진행하는 방법입니다.

이러한 Pseudo labeling은 classification이 집중된 방법이라고 얘기를 합니다. Pseudo labeling 기법을 통해 만든 Pseudo label을 분석해서 classification 성능 지표인 precision과 Iou Threshold 관계를 보면 iou가 0.9일 경우에 precision이 31 퍼센트밖에 되지 않습니다. 0.3일 때는 81퍼센트 수준입니다. Iou Threshold가 높아질수록 급격하게 precision은 떨어지게 됩니다.
이러한 지표를 분석했을 때 Pseudo label의 50퍼센트가 0.3에서 0.9 구간에 분포되어 있고 이러한 것은 학습 과정에 좋지 않은 영향을 끼친다고 저자들은 얘기를 하고 있습니다.

이렇게 bounding box 퀄리티가 좋지 않은 Pseudo label의 경우에는 label assignment에서도 문제를 야기시킵니다. 왼쪽 그림을 보면 proposal 박스와 GT를 비교했을 때 iou가 0.39로 낮은 수치이기 때문에 매칭이 되지 않아야 정상이고 그에 따라 백그라운드로 할당이 되어야 하지만 낮은 퀄리티의 Pseudo label과 매칭이 되는 경우에는 IoU가 0.55가 되고 Foreground로 할당이 될 수 있습니다.
이러한 잘못된 할당은 Foreground-Background decision 바운더리 생성을 방해하게 되고 최종적으로 성능에도 영향을 끼치게 됩니다.
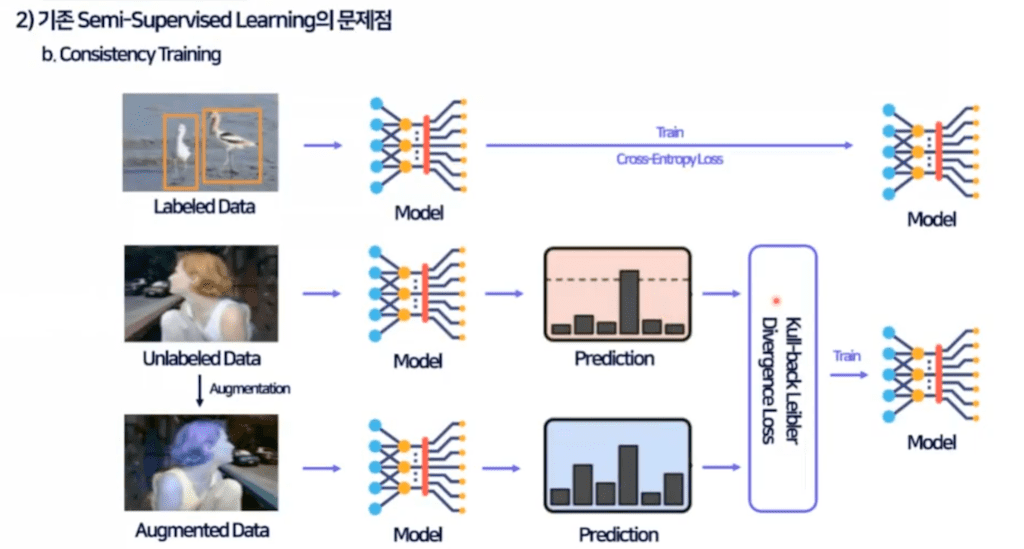
다음은 Pseudo labeling 방법과 더불어 대표적인 Semi-Supervised learning 방식인 Consistency 트레이닝입니다.
label 데이터는 Supervised모델을 학습을 하게 되고 unlabel 데이터는 augmentation을 진행한 뒤 두 개의 이미지 모두 모델의 입력으로 활용을 하게 됩니다.
이렇게 입력된 두 이미지의 classification 결과는 둘 다 person으로 동일해야 되고 이런 동일성을 가지고 kull-back Leibleer Divergence Loss와 같은 Consistency 로스를 계산해서 이를 통해 모델을 학습을 하게 됩니다.

저자는 Consistency 트레이닝 문제를 앞서 설명드린 Pseudo labeling과 같은 맥락으로 detection task의 속성을 고려하지 않았다고 얘기를 합니다.
Object detection 같은 경우에는 scale에 invariant 해야 되고 당연히 small Object의 성능을 높이기 위해서 feature 피라미드를 최근에는 당연시하게 사용하고 있습니다. 이처럼 detection task에서 사용되는 FPN처럼 스케일을 고려한 학습 방법이 기존의 Consistency learning에는 없다는 것이 문제입니다.
오른쪽 이미지를 보시면 네트워크에 prediction 결과만을 이용해서 Consistency loss를 계산을 하게 됩니다. 이를 label level Consistency라고 얘기를 하고 본 논문에서는 이런 문제들을 해결하는 방향으로 논문이 진행이 되게 됩니다.

다음은 Related work 부분입니다. 본 논문의 method을 설명하기에 앞서서 관련 임무들을 좀 설명을 드리자면 먼저 mean teacher를 얘기할 수 있습니다. mean teacher의 경우에는 teacher 모델을 student 모델의 웨이트를 활용하는 방법으로 사용하게 됩니다.
기존에는 teacher 모델과 student 모델이 다르게 학습되거나 다른 웨이트를 가졌지만은 mean teacher에서는 exponential moving average 방법을 사용해서 student 모델의 웨이트를 teacher 모델의 웨이트로 사용을 하게 됩니다. 하이퍼 파라미터 알파를 곱한 값을 이전 student 모델 가중치를 알파를 곱해서 이전 student 모델의 가중치를 teacher 모델로 활용을 하는 방법입니다.

mean teacher와 동일하게 student 모델과 EMA 방법을 사용을 해서 teacher 모델을 생성을 하게 되고 unlabel 데이터는 horizon flip이나 resizing 같은 weak augmentation을 적용한 이미지와 Cut out이나 로테이션 같은 STRONG augmentation을 적용한 이미지를 둘 다 인풋으로 사용을 해서 학습을 진행하게 되고 teacher 모델의 NMS 결과를 Pseudo box로 활용을 해서 student 모델을 학습하게 됩니다.
본 논문에서는 이 Soft teacher의 모델 구조를 그대로 채용을 했습니다.

Method에 대한 설명입니다.
방금 말씀드렸다시피 기본 구조는 Soft teacher와 동일합니다. 다만 unbiased teacher라는 논문에서 Pseudo 박스를 이용한 box regression loss를 삭제를 하게 됩니다. 그 부분을 본 논문에서도 활용을 하게 됩니다. 이런 box regression loss를 삭제하는 이유는 Pseudo label에 의해 생성된 bounding box는 퀄리티 문제로 학습과정에서 unstable을 야기하기 때문에 사용하지 않는다고 저자는 설명을 하고 있습니다.

본격적으로 본 논문에서 제시하는 방법입니다. 총 세 가지 방법을 제시를 합니다.
첫 번째는 prediction guided label Assignment
두 번째는 positive proposal consistency voting,
세 번째는 Multi view scale invariant learning입니다.
PCV 같은 경우는 전체 구조에서 2 부분을 의미하게 되고
MSL 같은 경우에는 3 부분을 의미하게 됩니다.
이 방법들을 좀 자세하게 설명을 드리겠습니다.

먼저 prediction guided label Assignment에 대해 설명을 드리겠습니다.
기본적으로 본 논문의 네트워크는 Faster R-CNN을 사용하게 되고 기존의 방법들은 아까 말씀드렸다시피 teacher 모델의 NMS 결과를 활용을 하게 됩니다. 위에서 언급했듯이 Pseudo label을 이용한 box regression은 학습 과정을 불안하게 해서 해당 loss 텀을 삭제를 했기 때문에 teacher 모델의 bounding box 성능과 관련된 information이 전달이 되지 않습니다. 그래서 이런 문제를 해결하고자 teacher 모델의 RPN 결과를 스튜던트 모델의 RPN 결과와 공유해서 Guidance를 전달할 수 있게 했습니다.
이러한 과정을 통해 생성된 box proposal들을 기존의 GT와 IoU를 이용해서 샘플링하던 방법과 다르게 퀄리티를 계산해서 n개 추출하는 방법을 사용하게 됩니다. 퀄리티 같은 경우는 이 수식과 같으면 S는 confidence score u는 Gt와 IoU 즉, Pseudo label과의 IoU라고 생각하시면 되겠습니다. 이러한 방법으로 샘플링을 하게 되는데 이때 샘플링할 때 N는 하이퍼 파라미터로 결정된 값이 아니라 OTA라는 네트워크에 제안한 dynamic k estintation 통해 선정합니다. 간단하게 말씀드리면 최적의 n을 계산하기 위해서 최적의 n은 regression loss를 잘 계산하는 숫자이다라는 개념을 가지고 n을 다이나믹하게 선정하는 알고리즘이라고 생각하시면 되겠습니다.

두 번째는 positive proposal consistency voting입니다.
기존의 박스 필터링을 진행할 때 probality와 confidence 곱을 통해서 스코어링 하던 것을 벗어나서 Localization 성능 또한 고려하기 위해서 제안한 방법입니다. 저자는 regression consistency를 제안을 했고 수식을 보시다시피 IoU 기반으로 웨이트를 계산하는 방식입니다.
이러한 regression consistency를 regression loss에 반영을 해서 localization 성능을 네트워크에 반영하는 방법으로 이용하게 되고 이렇게 제시하는 regression consistency의 실용성을 보기 위해서 이렇게 scatter 그래프를 제시했습니다.
그래프를 보시면 실제 IoU와 consistency가 비례해서 이렇게 올라가는 것을 확인할 수 있습니다. 왼쪽 아래 보시면 consistency는 높지만은 IoU가 낮은 경우도 확인할 수 있습니다. 이거에 대해서 저자는 annotation 에러라고 설명을 합니다. 실제로 데이터셋이 완벽할 수 없기 때문에 MS COCO에서 annotation이 되지 않은 부분을 지적을 하고 있습니다.
여기서 빨간색과 노란색 박스 들은 전부 다 저자가 제시한 방법으로 학습된 네트워크가 추정한 prediction 결과입니다. 이 빨간색 박스들은 실제로 이렇게 쳐줘야 되지만 데이터셋 자체에서 없는 annotation이라고 설명을 하고 있습니다.
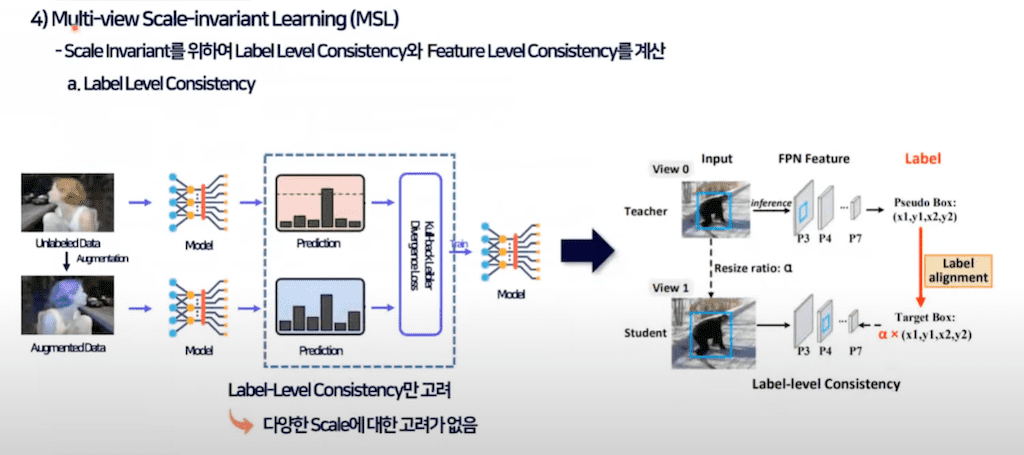
세 번째로는 Multi view scale invariant learning입니다.
설명드렸다시피 label level consistency를 반영하기 위해서 본 논문에서는 랜덤 resize ratio를 결합해 label alignment를 진행합니다. Random resizing을 진행한 이미지와 원본 이미지가 동일한 이미지이므로 동일한 label 결과가 나타나야 되며 이를 통해서 consistency 로스를 계산을 하게 됩니다.

추가적으로 feature level Consistency를 반영하고자 했습니다. Object detection의 scale invariant 해야 하는 속성을 반영하기 위해서 FPN 구조를 활용해 feature level Consistency를 제안을 했습니다.
view 1 이미지와 view 2 이미지를 각각 네트워크에 통과시키고 해당 FPN 구조에서 동일한 resolution을 갖는 FPN의 스테이지의 feature 맵을 feature alignment 시키는 방법입니다. 예를 들어서 640x640 이미지가 들어가게 되면 P3 단계에서는 160 x 160 이 될 텐데 320 x 320 인풋을 가진 FPN에서 보면은 P2 네트워크가 160x160 resolution을 가질 겁니다.
이러한 두 개의 feature가 같은 resolution을 갖는 feature이기 때문에 동일한 이미지가 있는 인풋을 받았을 때 feature 맵이 동일 해져야 된다라고 얘기를 하고 있습니다.

다음은 experiment 부분입니다.
논문에서 제시한 3가지 방법을 바탕으로 실험을 진행했습니다. 먼저 partial labeled 데이터 같은 경우에는 각 n퍼센트만큼 랜덤 샘플링해서 label 데이터를 구성을 하게 되고 랜덤 샘플링이기 때문에 5 Fold 방식을 사용해서 여러 번 학습 및 평가를 진행하게 됩니다. 보시다시피 평균 map와 표준편차를 구해서 이렇게 지표로 활용을 하게 되고 결과는 각각 task에 대해서 제일 좋은 SOTA 성능을 보이고 있습니다.
추가적으로 label 데이터를 활용해 Fully supervised 된 네트워크에서 unlabel 데이터를 활용해 추가적으로 학습한 경우도 제시를 했습니다. map 41이 label 데이터만을 가지고 학습한, 그러니까 Fully supervised로 학습한 방법이고 추가적으로 unlabel데이터로 본 논문에서 제시한 방법으로 학습했을 때 map 5.1 퍼센트 향상을 보인다고 얘기하고 있습니다. 그래서 label 데이터로 학습한 네트워크를 unlabel 데이터로 추가 학습했더니 map가 5.1 퍼센트나 증가한다고 얘기를 하고 있습니다.

위에는 Supervised learning을 통해 학습한 네트워크 결과입니다. 보시다시피 본 논문을 제시한 방법이 좀 더 잘 detection 한 것을 확인할 수 있고 추가적으로 제시하는 방법을 사용했을 때는 기존의 다른 Semi Supervised learning 방식인 Soft teacher보다 빠른 Convergence를 확인할 수 있다고 저자가 설명하고 있습니다.

ablation을 진행한 내용입니다.
보시다시피 각 모듈을 사용해서 성능이 지속적으로 형성되는 것을 확인할 수 있습니다. 최종적으로 모든 모듈을 사용했을 때 제일 높은 성능을 보이더라 하는 부분입니다.
Multi view scale의 경우에는 single scale 트레이닝 같은 경우는 이전에 랜덤 resize ratio를 가지고 학습을 했다 했는데 고정된 ratio를 가지고 학습했을 때 결과입니다. 확실히 랜덤한 ratio를 가지고 학습했을 때 결과가 더 좋은 걸 확인할 수 있습니다.
또한 각기 모듈에 있는 하이퍼 파라미터를 바꿔가면서 ablation을 진행해서 최적의 파라미터들을 찾아 성능을 냈습니다.

결론입니다.
Semi Supervised learning의 문제점을 해결해서 본 논문을 제시한 세 가지 방법을 적용해 SOTA를 달성했다는 부분입니다. 아래는 본 논문을 리뷰하면서 몇 가지 생긴 의문점을 좀 정리를 했습니다.
항상 Semi- Supervised 논문을 보다 보면 정해진 퍼센트만큼의 label 데이터 비율을 평가를 하고 실제 모델의 성능과 labeling cost의 타협점은 몇 퍼센트가 제일 적절한 label 데이터냐라는 것은 고려를 하지 않는 것 같았습니다. 그래서 사실 모델마다 다를 텐데 같이 결과를 내줬으면 실제 사용하는 사람 입장에서 이 방법에 대한 신뢰성이 올라가지 않았을까 생각을 해봤습니다.
두 번째는 성능 부분에 대해서 좀 의문이 좀 들었습니다. 현재 SOTA을 달성하고 있는 detection 리더보드를 보면 다 트랜스포머 기반이고 그리고 본 논문에서 제시한 최대 map 같은 경우는 46.1이고 실제로 보면 최근에 map는 다 60 이상입니다. 최근에 60퍼센트가 넘는 성능을 보유한 것들이 되게 많이 나오고 있는데 성능 적으로 보면 46.1 퍼센트라는 그 수치가 높은 수치가 아닌 것 같다는 느낌이 들었습니다.
게다가 본 논문에서 설명하는 것이 label 데이터를 학습하고 unlabel 데이터를 추가로 학습을 했더니 성능이 올라갔다는 부분도 있었는데 Faster R-CNN으로만 검증을 하고 다른 트랜스포머 기반의 모델에서는 하나도 검증 안 했다는 것은 조금 의문이 들었습니다.
만약에 Faster R-CNN 같은 트랜스포머 이전에 논문에서만 활용이 가능한 방법이라면 실효성이 있을까 혹시 아니면 본 논문에서 제시한 방법 중에 트랜스포머 계열의 논문에 활용할 수 있는 방법도 있을까라고 의문은 좀 들었습니다.
이는 순수하게 궁금증에서 나온 의문점이라는 거를 참고 부탁드리도록 하겠습니다.




댓글