안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘NeRF’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/Mk0y1L8TvKE)
이번에 발표드릴 논문은 2020년에 ECCV 베스트 paper로 accept 된 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 논문입니다.

처음으로는 3D Aware 모델입니다. 어떤 StyleGAN 같은 경우에는 어떤 하나의 feature에 대해서 Editing 하고 싶을 때 입에 해당하는 latent vector를 찾아서 수정함으로써 입에 해당하는 feature를 바꿀 수 있었는데 이런 콘셉트를 그대로 착안해서 GAN space 논문에서는 Input이 들어왔을 때 어떤 공간적인 정보까지도 Editing 하려고 시도했습니다.
결과를 봤을 때 로테이션 정보가 어느 정도 잘 학습된 것 같지만 왼쪽 그림과 오른쪽 그림을 따로 보면 같은 사람이 아닌 것 같이 인식되기도 합니다. 이러한 문제를 disentangle 되지 않았다고 하는 게 원하는 feature만 변화시켜야 되는 것과 달리 다른 feature까지도 모두 변했다는 것인데 이를 좀 더 효율적으로 3D를 더 잘 이해시키기 위해서 진행되고 있습니다.
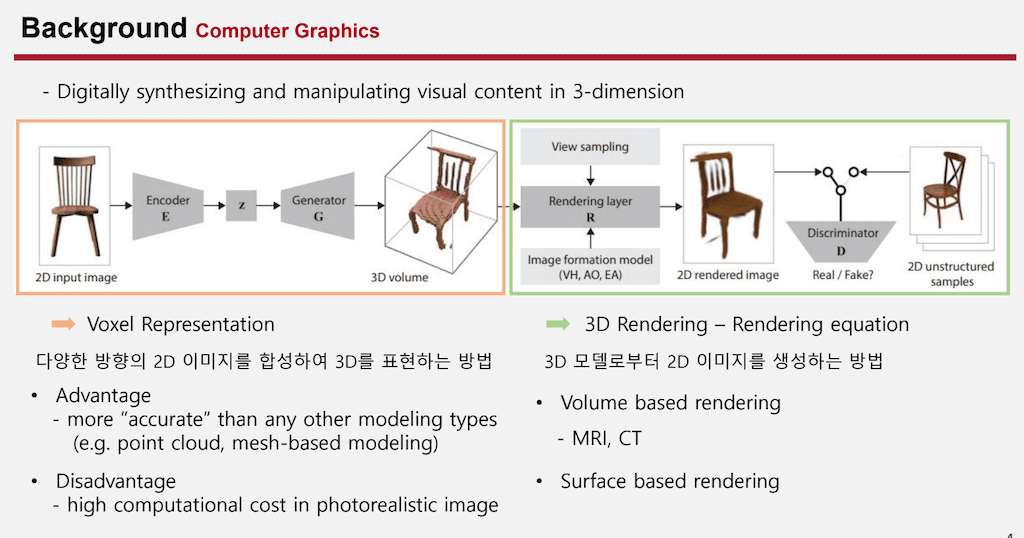
3D에 대해서 더 잘 이해하고 적용하기 위해서 Computer Graphics와 딥러닝이 만나게 됩니다.
Computer Graphics는 3D domain에서 이미지를 합성하거나 아니면 조작하는 연구 분야입니다. 분야를 크게 두 개로 나누면 2D 이미지를 바탕으로 해서 3D 데이터로 만드는 작업과 3D 데이터를 바탕으로 새로운 방향의 Rendering 이미지를 만들어내는 방식이 있습니다.
첫 번째로 Voxel Representation는 다양한 방향에 2D 이미지를 합성해서 3D로 표현하는 방식입니다. 이 장점으로는 점으로 표현하는 point cloud나 면으로 표현하는 mesh based modeling보다 훨씬 더 정확하다는 장점이 있지만 모든 데이터를 큐빅 데이터로 표현하다 보니 high computational cost가 동반되게 됩니다.
두 번째로는 3D Rendering 부분입니다. 3D 모델로부터 2D 이미지를 생성하는 방법인데 여러 가지 방법이 있지만 여기에서 소개해 드리는 것은 하나의 물리적인, 어떤 수학적인 식으로 3D 정보를 2D로 projection 시키는 Rendering equation을 사용합니다. 이 종류로는 Volume을 활용해서 모든 공간적인 정보를 활용해서 Rendering 시키는 Volume base Rendering 방식이 있고 그 예시로는 MRI나 CT가 있습니다. 두 번째로는 surface 정보가 들어왔을 때 그 해당하는 컬러를 2D projection 시키는 base Rendering이 있습니다.
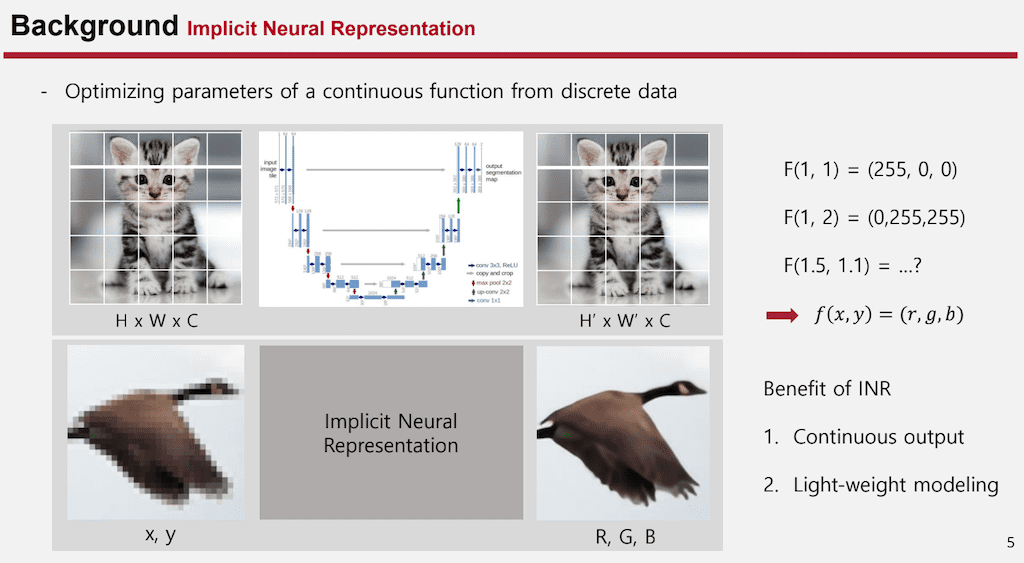
이를 효율적으로 어떤 함수에 최적화시키기 위한 방법이 또 필요하게 됩니다. 이를 해결하기 위해서 사용되는 방법이 Implicit Neural Representation입니다.
INR는 discrete data를 활용해서 어떤 하나의 continuous 한 function에 optimizing 시키는 과정입니다. 예시를 들어서 설명하면 convolution base의 U net구조를 보겠습니다. U net 구조는 Input으로 H x W x C 채널이 들어오고 output으로 H' x W' x C이 나오다 보니까 어떤 discrete한 데이터가 입력으로 들어왔을 때 그에 해당한 RGB 값을 알 수 있지만 continuous 밸류가 들어왔을 때 해당하는 RGB 값을 알 수 없습니다. 이 문제를 해결하기위해서 x,y 좌표가 들어왔을 때 그에 해당하는 RGB값을 출력으로 하는 하나의 함수를 정의하고 그 함수에 최적화시키는 INR 모델을 보면 x y 좌표가 Input으로 들어왔을 때 출력으로 그에 해당하는 RGB값이 나오게 됩니다.
INR의 장점으로는 continuous한 output이 나오는 것인데 이것은 어떻게 보면은 low resolution으로 학습을 시키더라도 출력 부분에서는 더 high resoulution처럼 출력을 할 수가 있고 추가적으로 원래discrete 한 곳에서는 미분값을 계산할 때 근사값을 구할 수밖에 없지만 INR같은 경우에는 output이 continuous하기 때문에 미분값을 바로 직접적으로 구할 수 있게 됩니다.
웨이트 관련해서는 discrete한 모델 같은 경우에는 하나의 픽셀 단위의 probability를 결국 다 구해야 하는 문제이기 때문에 모델의 복잡도는 픽셀 resolution에 비례하게 커지는데 INR는 픽셀에 대한 어떤 학습이 빠졌기 때문에 순전히 데이터 복잡도에만 비례한 웨이트를 가지게 됩니다.
결과적으로 일반적인 discrete 모델보다 훨씬 가벼운 모델이 만들어지게 됩니다.
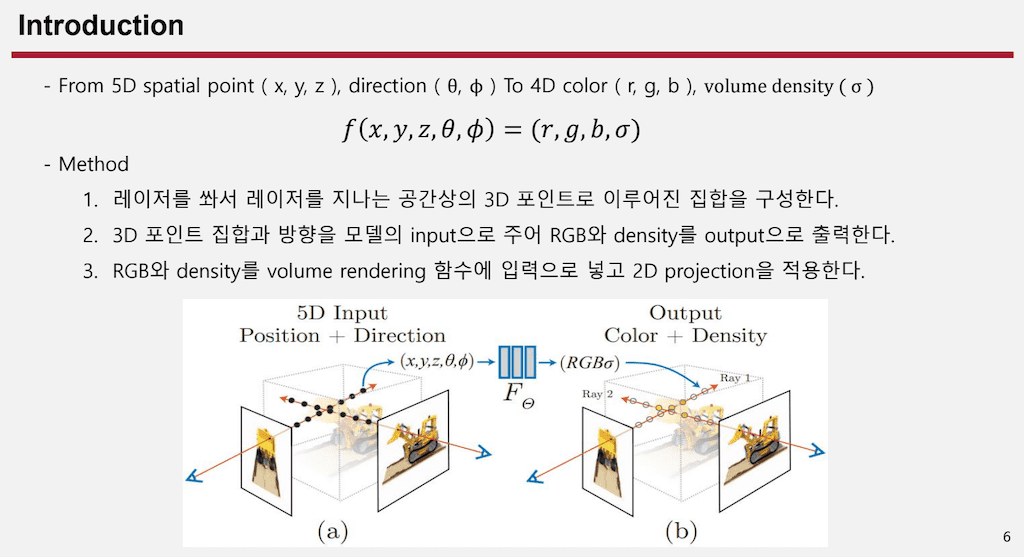
여기까지 INR과 Computer Graphics를 활용해서 NeRF 논문이 진행된다는 걸 말씀드리고 NeRF 모델에 대해서 간단히 설명드리겠습니다.
처음에 5D 정보가 들어옵니다. 공간적인 정보 xyz와 방향 정보 Θ π가 들어왔을 때 4D 정보 컬러 RGB랑 그리고 RGB에 해당하는 밀도 까지도 계산하게 되는 것인데 그 함수를 이렇게 XYZ Θ π 그리고 output이 RGB σ 이렇게 주어지는 함수라고 가정을 하고 INR 모델링을 하는 것입니다.
이 과정을 전체적인 과정을 순서대로 보면 첫 번째로 하나의 카메라 레이저 point에서 레이저를 써서 이에 해당하는 3D 공간상의 point 집합을 구성합니다.
두 번째로 이 모델로 알 수 있는 XYZ Θ π정보를 모델에 전해주게 되고 output으로 그 모든 점들에 해당하는 RGB 값과 Density값이 나오게 됩니다.
결국에 3D에 대한 모든 정보에 대해서 RGB 값과 Density 값을 알 수 있다면 Volume Rendering 함수에 들어가서 2D로 projection 시키게 됩니다.

이 페이퍼에서 말하고자 하는 것은 여태까지 convolution base 모델이 많았지만 MLP 네트워크를 활용해서 적용한다는 점을 이야기하고 있고
두 번째로는 computation cost가 Volume Rendering 같은 방식은 computation cost를 줄이는 것이 중요한 문제인데 그 부분을 효율적으로 해결하기 위해 hierarchical 샘플링 방식을 채택합니다.
세 번째로는 high frequency를 표현하는 게 굉장히 어려운데 INR는 이 부분을 좀 더 해결하기 위해서 positional encoding 방식을 적용했다는 점을 소개합니다.

전체적으로 이야기하기 전에 그 전에는 어떤 문제가 있었길래 이 문제를 해결하려는지 이해를 하기 위해 전에 논문을 보면 맨 처음에 Computer vision 같은 경우에서 논문을 보면 X Y 좌표를 바로 XYZ 좌표로 INR 모델을 통해서 베팅시키는 함수를 적용했습니다.
이런 경우는 문제점이 굉장히 복잡한 지오그래픽이 들어왔을 때 성능이 굉장히 떨어지는 문제가 있었는데 이를 해결하기 위해서 2D 이미지를 3D로 표현하는 Neural 3D shape representation과 3D 정보가 들어왔을 때 3D 정보를 바탕으로 2D로 projection 시키는 View synthesis and image-based rendering 두 가지 방식으로 나눠 설명드리겠습니다.

처음으로 2D 이미지를 바탕으로 3D로 만드는 방식인데 처음에는 XYZ 좌표를 바탕으로 signed distance function을 만들어서 0보다 작을 때는 물체 내부에 있고 0보다 클 때는 물체 외부에 있도록 하는 모델을 만들었습니다. 어느 정도 성능 향상에 효과는 있었지만 이 대입이 모델을 학습시키려면 결국에는 배경화면이 깔끔한 물체만 있는 데이터여야 했기 때문에 합성한 데이터셋을 만들 수밖에 없었고 이는 많은 실험을 다양하게 하기에는 굉장히 큰 단점으로 작용했습니다.
그래서 최근에는 Implicit Neural representation을 통해서 2D 이미지로만 학습을 하는 방식이 채택이 되는데 3D occupancy는 표면에 얼마나 빛이 만났는지를 바탕으로 해서 2D projection 시키는 방식이고 두 번째로는 RNN을 통해서 Rendering함수를 구현하기도 했습니다. 이런 경우에 큰 단점으로는 high resolution이나 굉장히 복잡한 패턴을 표현하는데 단점이 있었습니다.
이에 해당하는 원인은 표면에 대해서 다양한 빛이 들어왔을 때 local minima에 빠질 가능성이 있고, RNN 모델은 over smoothing 문제가 발생했던 것으로 보입니다.

그다음에 3D 정보가 들어왔을 때 2D를 projection 시키는 방법이 있는데 이 부분은 크게 Surface based와 Volume base Rendering 방식이 있습니다.
Surface base Rendering는 Surface에 대한 3D 정보가 들어왔을 때 이 부분을 2D로 projection 하는 방식입니다. 이 방법의 단점으로는 새로운 모델이 제대로 학습을 하더라도 새로운 방향에 대해서 projection 시키고 싶을 때 제대로 안 나오는 문제가 있습니다. 그리고 역시나 마찬가지로 배경을 없애 주고 인위적인 데이터셋을 만드는 것이 하나의 큰 단점으로 작용하고 이를 좀 해결하기 위해서 Volume base Rendering이 사용되게 됩니다.
Volume base Rendering는 성능 향상으로는 많은 효과가 있었지만 모든 픽셀 값을 계산하기 때문에 굉장히 많은 time complexity와 space complexity가 발생하게 된다는 문제가 있습니다.
그래서 정리를 해보면 high frequency나 high resolution을 표현할 수 있는 모델이 필요했고 실제로 배경이 일반적인 real world scenes에서도 학습 가능한 모델 그리고 time complexity나 space complexity가 좀 작은 모델을 해결하고자 이 논문이 쓰였습니다.

Neural Radiance Field의 모델에 대해서 좀 더 자세히 들여다보면 카메라가 들어왔을 때 그에 해당하는 point들이 집합으로 만들어지고 모델에 들어가서 RGB 값과 Density 값으로 나오게 됩니다. 이에 대한 출력으로는 모든 point에 대해서 RGB 값과 Density 값이 위처럼 분포가 나오는 것을 볼 수 있고, 이를 2D projection 시킨 다음에 원래 2D 이미지와 L2 regression을 통해 학습이 진행됩니다.
모델에 대해서 좀 더 자세하게 보면 Input 데이터로 spatial 정보가 들어왔을 때 MLP만을 통해서 모델이 이루어지고 이를 통해서 Density가 만들어집니다. 그리고 Density와 Spatial 정보 그리고 direction 정보 세 가지를 통해서 RGB 값이 만들어지는데 이는 연구를 시작할 때부터 Density 값은 위치에 dependent 한 variable 이라고 가정을 했고 RGB값은 spatial정보, direction 정보, Density 정보의 dependent한 variable이라고 가정했기 때문에 이렇게 모델을 찾습니다.

그리고 다음으로는 3D 정보가 잘 만들어졌을 때 projection 시키는 함수에 대해서 설명드리겠습니다. 처음에 대문자 C(r) 같은 경우에는 3D 정보를 통해서 만들어진 predictive color입니다. 그리고 위치 정보를 나타내는데 discrete 한 데이터가 그대로 사용되면 INR을 사용하는 것이 아니기 때문에 discrete한 정보를 continuous한 정보로 치환을 해야 되는데 이를 위해서 카메라에 원점 o vector와 direction vector d를 활용하고 그의 continuous한 밸류 t를 적용함으로써 discrete한 학습을 continuous 한 학습으로 바꾸게 됩니다.
tn과 tf는 물체가 존재할 것 같은 하이퍼 파라미터로 적분의 처음 부분과 끝부분을 이야기하고 있고,
T 함수는 물체의 Density를 보면은 물체가 있는 곳에서 Density가 높을 텐데 만약에 앞에 장애물이 있어서 Density가 높은 값이 있다면 오히려 높은 값에 대한 projection을 더 많이 해야 합니다. 그래서 T 텀은 앞에 장애물이 들어왔을 때 뒤에 Density가 높더라도 어느 정도 무효화시킬 수 있는 텀입니다.
그리고 이 σ 텀과 color 텀은 모델의 output을 표현한 것입니다. 결국에 전체 함수가 Volume 3D에 대한 컬러와 Density 값을 모두 알고 있다면 2D projection 시킬 수 있는 함수입니다.
Density는 물체가 어느 정도 있을 거냐라고 하는 확률분포라고 이해를 하고 있습니다.
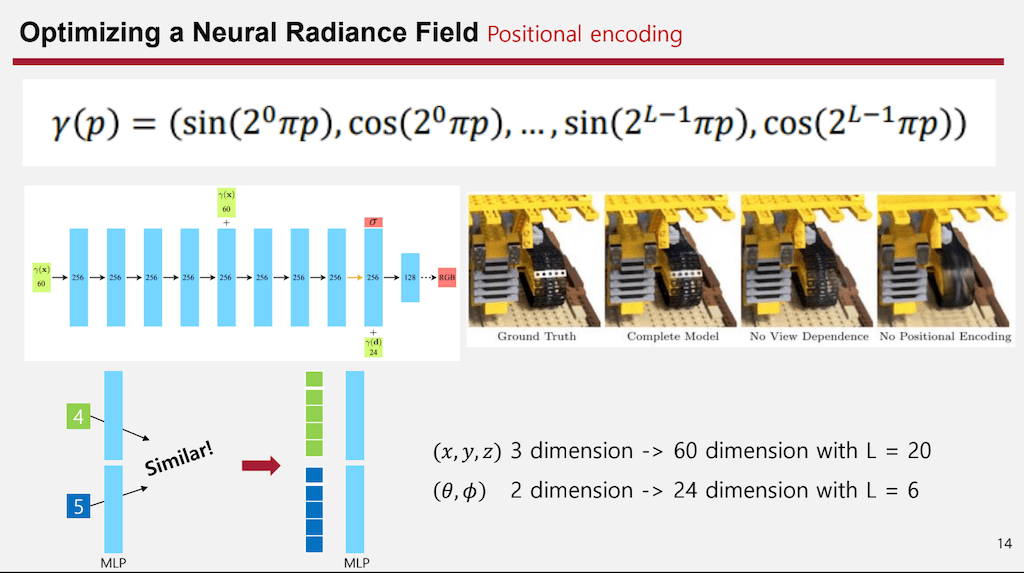
그전에 있던 문제들을 해결했는지에 대해 설명드리겠습니다. 처음으로 positional encoding방법인데 저희가 익숙하게 알고 있는 NLP에서 Positional encoding과 결이 다릅니다. NLP에서 Positional encoding은 히든 vector들의 위치 값을 모두 구분하기 위해서 넣는 값이지만 여기서 의 Positional encoding은 하나의 값을 더 높은 차원으로 바꿔주기 위함입니다.
예시를 들자면 만약에 4라는 값과 5라는 값이 있을 때 MLP layer를 태운다면 layer는 weighted sum이기 때문에 값이 차이가 크지 않다면 굉장히 비슷한 값이 나올 수밖에 없습니다. 이를 해결하기 위해서 가까운 값으로 분포할 때도, 멀리 있더라도 다른 vector로 만들어 줄 필요가 있었는데 이를 해결하기 위해서 low frequency부터 high frequency까지 굉장히 다양한 sin, cos function을 활용해서 높은 dimension으로 바꿔주게 됩니다.
이를 통해서 Positional encoding이 들어가지 않는 경우를 봤을 때 비슷한 공간 좌표에서 보면 굉장히 high resolution을 잘 표현하지 못하는 것을 볼 수 있지만 Positional encoding을 사용한 후에는 high resolution 파트가 잘 살아나는 것을 볼 수 있습니다. 이 dimension은 하이퍼 파라미터인데 논문 내에서는 L을 20으로 줘서 60 dimension 그리고 dimension 정보에서는 L을 6으로 둬서 24 dimension으로 학습을 진행합니다.

두 번째로는 Hierarchical Volume 샘플링입니다. 시간적으로도 효율적인 방법을 고안했는데 처음에 n등분을 해서 유니폼 distribution으로부터 뽑는 것이 가장 기본적인 전제이고 처음에 n을 64 등분해서 한번 학습을 진행하게 됩니다.
그리고 나면 처음에 distribution Density가 이렇게 나오는데 여기에서 높은 Density를 가지는 것을 위주로 해서 다시 128개를 뽑습니다. 그다음에 한 번 더 학습을 진행을 하면은 Coarse 한 어떤 굵직한 feature와 fine 한 feature에 세세한 디테일을 각각을 로스에 넣음으로써 학습이 진행됩니다.

데이터셋에 대해서 설명드리겠습니다. Diffuse Synthetic 360는 512 x 512 2D 이미지고, 479개 Input과 1000개의 테스팅 이미지가 있습니다. 그리고 Real Forward Facing는 1008 x 756 픽셀이고 20개에서 62 개의 이미지가 있고 8분의 1 정도를 테스트 셋으로 설정한 데이터입니다.
위는 인공적으로 배경이 없도록 만든 데이터고 아래 데이터는 실제 이미지를 찍은 데이터입니다.
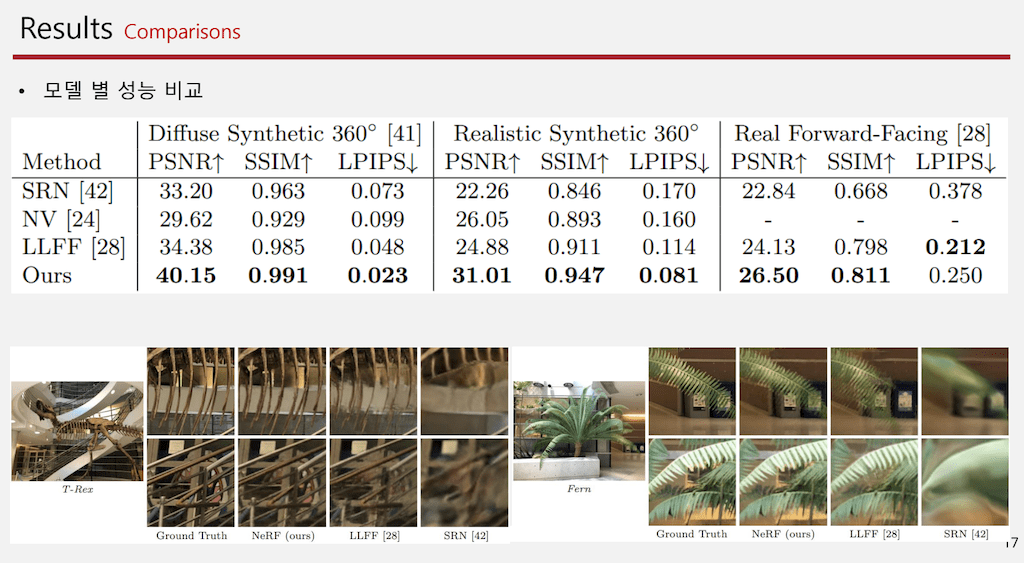
전 모델과 어떻게 성능이 비교되는지 설명드리겠습니다. SRN이나 NV, LLFF 모델 같은 경우보다 모든 영역에서 대부분 성능이 많이 좋아진 것을 확인할 수 있습니다. 그리고 그림에서 보더라도 어떤 댑스도 굉장히 잘 표현하고 high frequency도 잘 표현하는 것을 볼 수 있습니다.

모델에 대해서 간단하게 설명드리면 LIFF는 Local Light Field Fusion으로 Input이 이렇게 들어가 보 면각각을 하나의 Multi plane으로 나눠서 학습하는 과정이 있고 그 과정을 통해서 3D convolution으로 이미지를 만들고 Rendering 방식으로 2D projection 시킵니다.
SRN는 조금 더 단순한 방식인데 INR를 사용하고 XYZ를 넣었을 때 하나의 feature vector를 만드는 형식으로 진행이 되고 만들어진 feature vector로 color 디코딩을 하는 방식입니다.
NV는 여러 개 이미지를 2D convolution에 넣고 concat을 해서 중간 단계에서 어느 정도의 정제 과정을 거친 후에 3D deconvolution을 통해서 128개 형태로 출력을 하게 됩니다.
그 특징들을 보면 NV는 결국에는 하나의 임베딩 vector를 바탕으로 만들어지는 3D 이미지기 때문에 굉장히 작게 만들 수밖에 없습니다. 여기를 보시면 resolution이 낮은 단점을 볼 수 있고 SRN는 굉장히 단순한 모델이다 보니까 전반적으로 high frequency를 표현을 하지 못합니다. 그리고 LIFF는 plane으로 결국에는 3D들을 인식하다 보니까 댑스가 좀 깊은 부분에서 조금 성능이 안 좋고 댑스가 낮은 부분에 대해서는 잘 표현하는 것을 볼 수 있습니다.

다음에 여기에서 관련된 성능 향상 기법을 활용한 Ablation studies입니다.
Positional encoding이나 VD 그다음에 Hierarchical sampling이 있을 때와 없을 때를 관련해서 실험 결과를 쓰고 있고 흥미로운 점은 Hierarchical sampling을 통해서 했을 때 N을 크게 해서 한 것보다 성능이 더 좋았다는 것도 볼 수 있습니다.

결과적으로 이 논문에서 contribution이라고 할 수 있는 부분은 rendering 함수를 더 효율적으로 CNN이 아닌 MLP로 사용함으로써 효율적으로 썼다는 점과 Volume rendering이 굉장히 코스트가 높은 함수임에도 불구하고 샘플을 효율적으로 추출해서 학습을 했다는 점, 그리고 실제 이미지를 가져다가 학습을 진행할 수 있다는 장점이 있습니다.
결과적으로 LLFF는 고화질의 이미지가 들어왔을 때 15GB나 되는 모델이 만들어지지만 NeRF는 이제 5MB 밖에 안 되는 웨이트로 구성을 할 수 있다고 합니다.




댓글