안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Detext: A Deep Text Ranking Framework with BERT’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Detext' 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/tE_1uiaUf1k)
오늘 발표할 논문은 ‘A Deep Text Ranking Framework with BERT’입니다. 2020년 LinkedIn에서 DeText라는 오픈 소스를 발표를 했습니다. DeText는 NLP 관련 ranking, classification, language generation task를 위한 framework입니다. 오늘 발표할 논문에서는 Search System의 Ranking에 DeText를 적용한 내용 위주로 설명이 됩니다.

먼저 검색 시스템에 대해서 설명하겠습니다. 우리가 검색 서비스할 문서들이 있고, 이 문서를 Indexing이라는 작업을 거쳐서 Index DB를 생성합니다. 그러고 on the fly로 user query 가 들어오면 미리 생성해 놓은 Index DB로부터 관련 문서 relavance 한 Top-k개를 가져옵니다. 그리고 나서 Top-K 개의 문서들에서 사용자게 좋은 품질의 결과를 제공하기 위해 문서들을 ranking model이라는 걸 통해서 순위를 조절하고 결과를 제공합니다. 여기서 Ranking model에 활용하는 feature는 별도의 learning을 하거나, Top-k retrieval 과정에서 해소를 할 수 있습니다.
이 논문에서 검색 시스템에서는 ranking이라는 component가 중요하다. 그런데 지금까지는 word 또는 phrase exact matching 위주의 ranking approach들이 많았습니다. 그래서 BERT와 같은 contextual embedding을 이용한 modeling를 해서 기존 기술에 대한 개선을 해야 한다고 합니다. 그런데 BERT는 on the fly에서 계산하기에는 비용이 많이 듭니다. 특히 검색과 같이 대량의 트래픽이 발생하고, Response time이 중요한 시스템에서는 latency가 정말 중요합니다. 그리고 query와 document의 interaction이 필요한 시스템에서는 pre-computing 하기 힘든 상황입니다.
그래서 DeText라는 Framework를 제안을 했고, 이 DeText를 이용해서 LinkedIn의 search service인 people search, job search, help cente를 제공하고 있다고 설명합니다.

논문의 background입니다. LinkedIn의 search와 recommendation system입니다. search와 recommendation을 같이 생각을 해볼 수 있는데, search는 사용자가 입력한 query를 가지고 있고, recommendation은 직접적인 query가 있는 게 아니라 user profile이 있습니다.
여기서 spell check, query suggestion, auto complete 등등의 component로부터 도움을 받을 수 있습니다. 그러고 입력된 query와 profile 정보로 기본적인 text processing을 합니다. 예를 들어, language detection을 하고, tokenization 하고, normalization 등을 합니다. 그러고 나서 query 또는 profile에 대한 understating 과정을 거칩니다. 예를 들어, query로 “software engineer” 라는 텀이 포함되어 있으면 이 software engineer가 일종의 직책이나, 기술임을 알아야 하고, query 가 job을 찾는 것인지, people를 찾는 것인지에 대한 파악을 해야 합니다. 그리고 나서 전체 대상 문서로부터 관련성이 있는 문서를 추출하는 retrieval 과정을 거칩니다. 이 과정에서 검색 대상인 문서들 또한 동일한 Text processing을 거치고 문서에 대한 understanding 과정이 필요하고, retrieval 과정에서 사용을 하게 됩니다.
이렇게 retrieval 된 문서들에 대해서 ranking을 하게 됩니다. 이 모든 과정에서 text data가 존재를 하고, 모든 구성 요소에 NLP 처리가 포함이 되어 있습니다. 그리고 상황에 따라서 DeText와 같은 model을 곳곳에서 사용할 수 있습니다.

랭킹 시스템에서의 딥러닝 모델은 접근법에 따라서 두 가지로 나눌 수 있습니다. Representation based과 interaction based입니다.
Representation based는 각 text의 의미를 잘 표현하는 구조에 집중을 해서, query와 검색 결과의 의미를 매칭 하는데 집중합니다. 그래서 input이 query와 검색 결과가 각각의 모델의 입력을 해서 대칭적 구조를 가집니다.
그에 비해 Interaction based는 두 Text의 상호작용을 계층적으로 배워서 관련성을 매칭 시키는데 집중하는 모델입니다. 검색어와 검색 결과의 연산을 거쳐 계층적인 매칭을 파악하는 피라미드형 구조입니다.
두 개의 접근법을 비교해보면 성능은 아무래도 query와 결과의 관련성을 매칭 시키는데 집중하는 interaction based가 좋은 성능을 낼 것입니다. 그런데 pairwise word 비교로 인해 계산 시간이 더 오래 걸려서 속도가 더 오래 걸리는 단점이 있습니다.
여기서 DeText는 BERT의 interaction base라 속도가 느린데 이를 representation based로 가능하게끔 한 Framework라고 소개를 합니다.
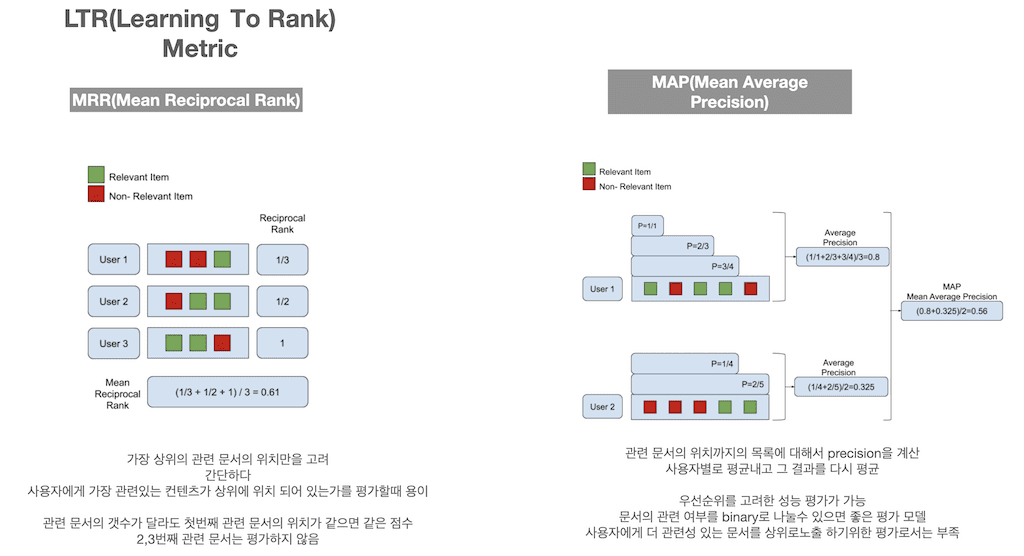
그리고 background로 알면 좋은 건 랭킹에서의 평가 metric입니다. LTR은 ranking 순서를 학습해야 하기 때문에 평가 방식도 다르게 사용해야 합니다. 대표적인 몇 가지 평가 방법이 있는데 MRR, MAP, nDCG입니다. 먼저 MRR은 간단합니다. 가장 상위의 관련 문서의 위치만을 고려한 평가입니다. 단점은 관련 문서의 개수가 달라도 첫 번째 문서의 위치가 같으면 같은 점수를 받고, 2,3번째 문서는 아예 평가하지 않습니다.
MAP는 관련 문서의 위치를 기준으로 precision을 계산하고 결과 별로 평균하고, 그리고 전체 평균을 내는 방식입니다. 간단하게 우선순위까지 고려된 평가가 가능하고, 관련 문서가 binary로 나눌 수만 있으면 간단하고 좋은 지표입니다. 그런데 관련 문서 중 더 관련이 있는 문서가 상위로 노출하게 하기 위한 평가로는 부족합니다.
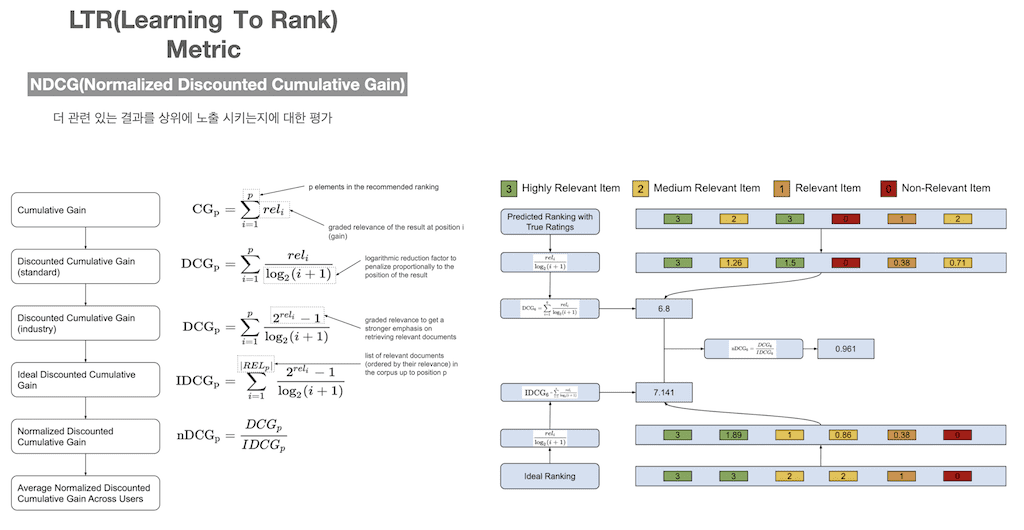
MAP의 한계점을 극복하고자 NDCG가 나왔습니다. NDCG는 좀 더 관련성 있는 문서를 더 상위에 노출시키는지에 대한 평가입니다. 위에서부터 보면 모든 콘텐츠들의 relevance score 합해서 CG를 구합니다. DCG는 각 콘텐츠들의 relevance score를 log 함수로 나눠서 값을 구합니다. i가 문서의 위치인데 i 값이 클수록 DCG 값을 더 작게 만들기 때문에 상위에 위치할수록 점수를 더 반영하게 됩니다.
- DCG가 두 가지 수식이 있는데, 관련성을 더 강조하고 싶을 때 2의 제곱으로 표현해서 관련성의 영향을 더 증가시킬 수 있습니다.
- 각 결과의 DCG 와는 별개로 이상적인 DCG라고 해서 IDCG를 미리 계산해놓습니다.
- 각 결과의 DCG를 IDCG로 나눠서 결과 별 NDCG를 구하고
- 결과 별로 NDCG를 평균을 냅니다.
이 논문에서 주 평가를 NDCG로 평가를 하고 있습니다.

Learning to rank는 구체적인 score보다 list의 order를 학습해야 하는데 3가지의 loss function이 있습니다. point wise, pairwise, listwise입니다.
pointwise는 score를 prediction 하는 것입니다. 개별 문서의 score를 prediction 해서 그 순서를 찾아냅니다. ranking을 prediction 한다는 관점과는 맞지 않습니다.
pairwise는 쌍으로 문서를 활용해서 ground truth와 가장 많은 pair가 일치하는 순서를 찾아냅니다. pair의 조합의 방법이 여러 가지 있는데, 그 조합의 최적화가 중요합니다.
listwise는 반환된 문서 전체를 ground thruth와 비교해서 랭킹 순위가 가장 일치하도록 하는 게 목적이고 복잡도가 제일 높으나 결과는 좋습니다.
DeText에서도 마지막 Layer가 LTR layer인데 상황에 따라 pointwise를 사용하거나 pairwise, listwise를 사용할 수 있습니다.
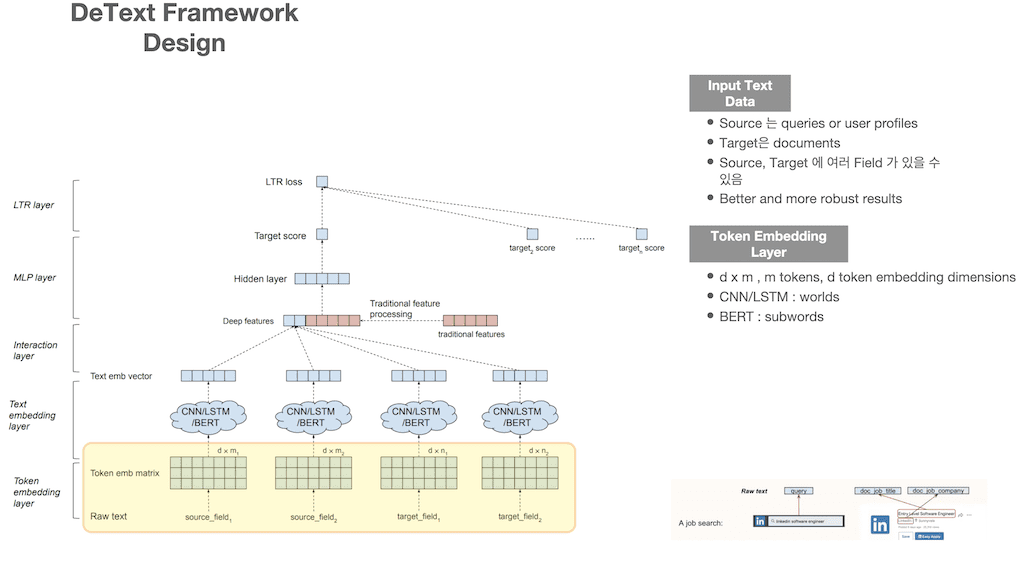
DeText의 구조입니다. DeText는 총 5개의 layer로 구성이 되어 있는데 한 layer씩 알아보도록 하겠습니다. 먼저 Input Text Data입니다. source는 query이고, target은 document입니다. source와 target field는 여러 개가 있을 수 있고, 이 여러 필드를 사용하는 게 더 성능이 좋다고 합니다. LinkedIn의 job search에서는 source가 검색창 입력 query이고, target 필드는 2가지인데 job title과 job company입니다. 첫 번째 Layer가 Toen Embedding Layer입니다. Input Text에 대한 embedding이고 m은 tokens, d는 embedding dimensions인데 d x m metrix로 embedding을 합니다. CNN, LSTM은 개별 워드가 되겠지만 BERT는 subword가 됩니다.
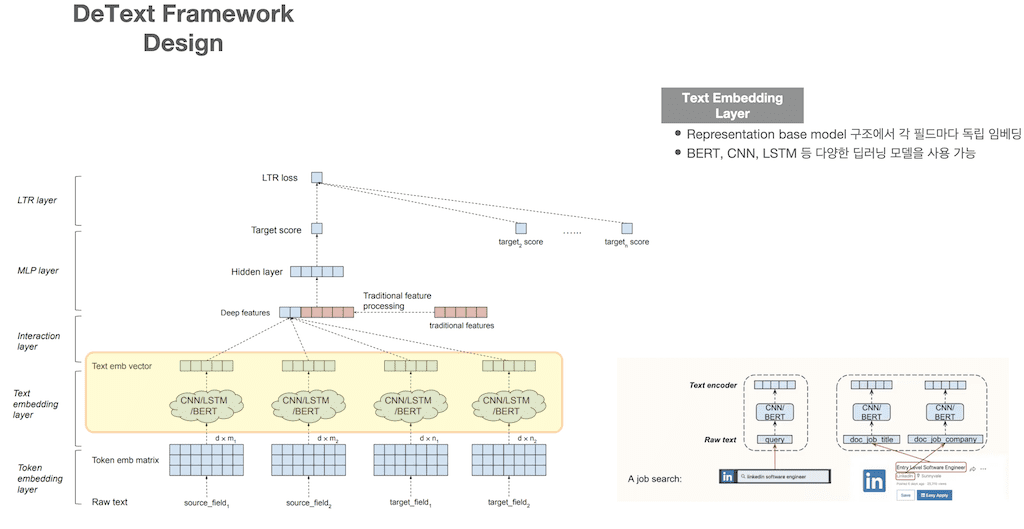
두 번째 Layer는 Text Embedding Layer입니다. 이 layer에서는 다양한 모델을 사용할 수 있습니다. CNN/LSTM/BERT 등 상황에 맞게 사용합니다. 이 구조는 앞서 말씀드린 representation base model 구조이고 각 field마다 독립 embedding이 생성이 됩니다.
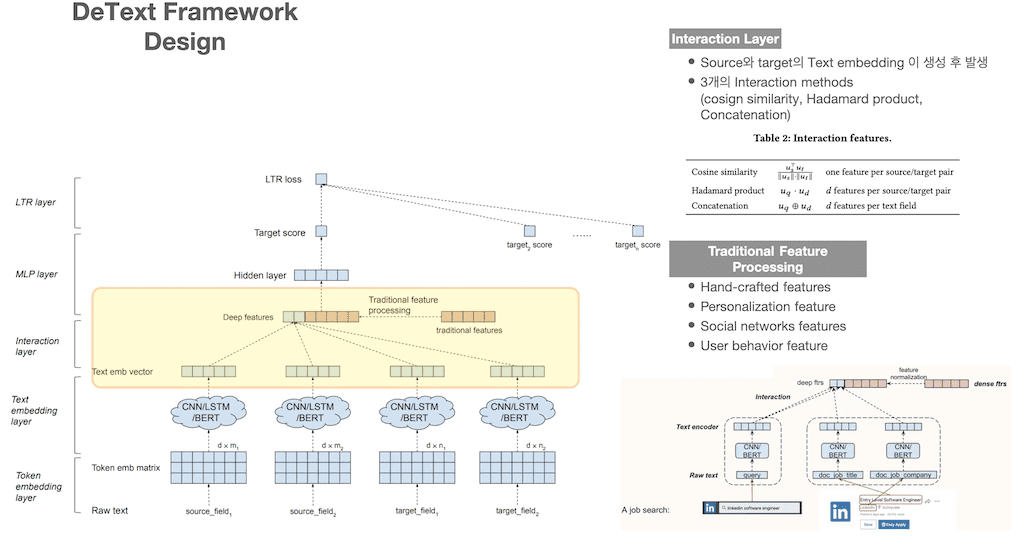
세 번째 Layer는 Interaction Layer입니다. source와 target 개별 Text embedding이 생성 후 진행이 되고 3개의 interaction method를 지원합니다. vector 간의 유사도를 측정하는 cosine similarity, 두 벡터간의 원소의 곱인 hadamard product, vector간의 concatenation을 지원합니다. 그리고 추가적으로 Traditional Feature processing이 있습니다. 학습에 참여하는 Feature들 중에서 Text를 제외하고 특정 도메인에 knowledge가 있습니다. 이런 domain knowledge를 이용해서 다양한 Feature를 만들고 이를 학습에 이용을 합니다. 이 Feature들을 Interaction layer에서 함께 사용할 수 있습니다. Traditional feature의 예로는 Hand-crafted features, Personalization features, Social networks features, User behavior feature가 있습니다.
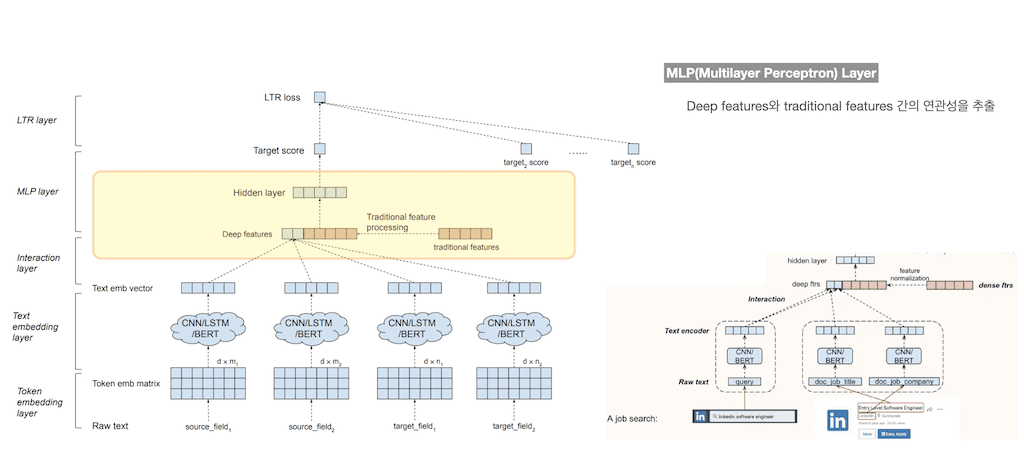
네 번째 Layer는 Multilayer Perception layer입니다. Deep features와 traditional features 간의 연관성을 추출합니다.
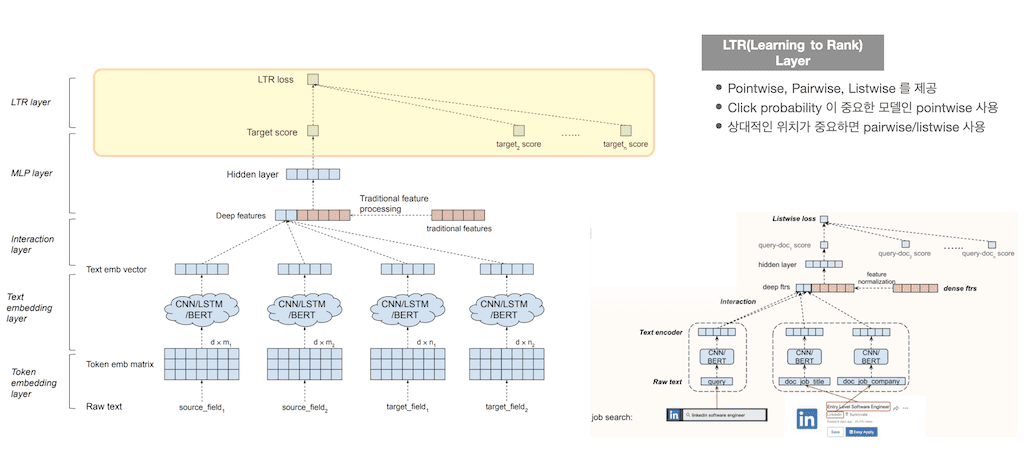
마지막으로 LTR Layer입니다. MLP layer를 통해서 query-doc1 score, query-doc2 score 가 추출이 되면 이를 바탕으로 Learning to rank를 학습합니다. Pointwise, pairwise, listwise는 상황에 맞게 선택을 해서 사용을 하면 됩니다. 상대적인 위치가 중요하면 pairwise, listwise를 사용하고, 그렇지 않으면 pointwise를 사용하게 됩니다.
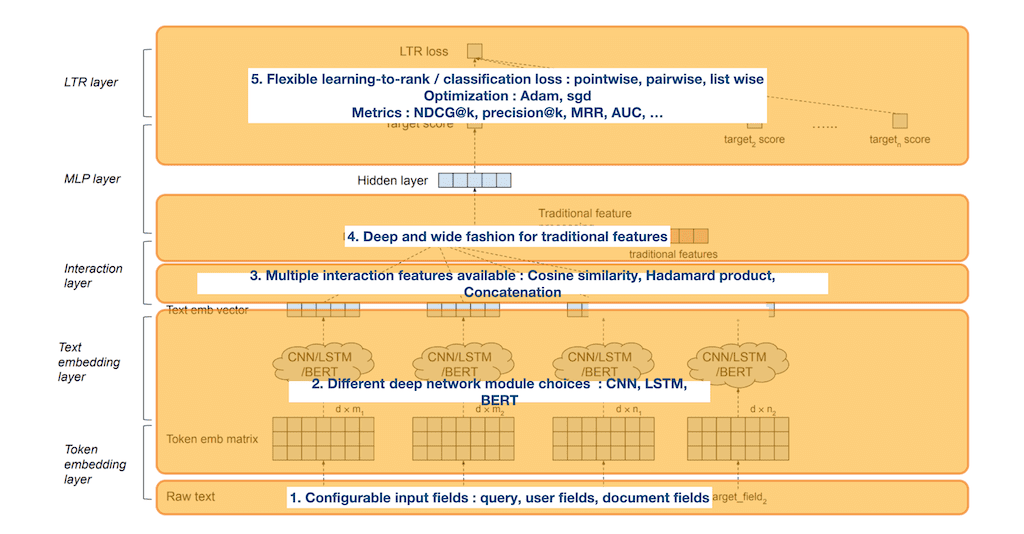
DeText를 레이어 별로 요약하겠습니다. Input은 query, user fields, document fields 가 될 수 있고, Deep network module은 CNN, LSTM, BERT 등을 선택해서 사용할 수 있습니다. Interaction feature는 Cosine similarity, Hadamard product, Concatenation를 사용할수 있고 traditional feature를 함께 사용 할 수 있습니다. 마지막으로 Learning To Rank를 이용해서 최종 학습을 하고, point wise, pairwise, list wise 로스 중 상황에 맞게 선택해서 사용하고, 순위에 대한 다양한 평가 메트릭으로 평가할 수 있습니다.
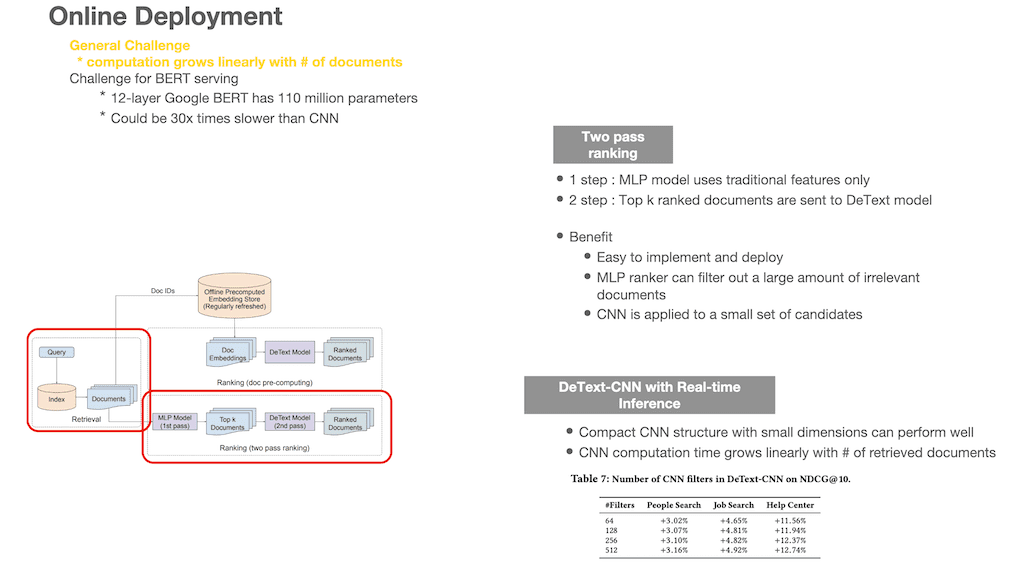
DeText를 검색 시스템에 적용하기 위한 방법입니다. 검색 시스템에서 Deep Model을 적용하기 위해서는 여러 상황에 대한 challenge 크게 두 가지로 받습니다.
하나는 일반적인 challenge인데, 랭킹을 할 문서가 많으면 많을수록 계산 비용이 linear 하게 증가를 하는 문제입니다. 두 번째는 BERT로 serving을 하기 위한 challenge입니다. BERT는 파라미터도 많고, on the fly로 serving 하기에는 부담이 되는 모델입니다.
그래서 2가지 온라인 배포 전략을 제안합니다. 먼저 문서가 증가하면 할수록 계산 비용이 증가되는 문제에 대한 전략입니다. 위 그림에서 왼쪽 붉은색 테두리는 일반적인 retrieval 과정을 그대로 묘사한 것입니다. Retrieval 과정까지는 기존대로 진행을 하게 됩니다. 그러고 나서 ranking 부분에서 two pass ranking 전략을 사용하게 됩니다. 첫 번째 step으로는 traditional features만을 이용해서 MLP를 수행합니다. 그러고 나서 Top-k 개의 문서를 추출을 하고, 두 번째 step으로
DeText Model을 통과해서 최종 ranking 된 문서를 얻을 수 있습니다.
DeText model은 DeText-CNN을 사용하였고, filter의 수에 따른 각 컬렉션별 NDCG@10을 살펴봤을 때 필터의 사이즈가 크게 영향을 받지 않아서 64 filter를 사용하게 됩니다. 이렇게 two pass ranking으로 진행을 하게 되면 좋은 점이 적용과 배포가 쉽고, MLP model을 통해서 많은 문서 중 관련성이 적은 문서들은 filter out 할 수 있어서 성능에 많은 도움을 줄 수 있습니다.
DeText-CNN Model로 유입되는 문서는 Top-k 개 정도니까 많은 성능적 효과를 볼 수 있습니다.

다음은 BERT를 serving을 하기 위한 challenge입니다. BERT를 서빙하기 위해서 두 가지를 제안합니다.
첫 번째는 LinkedIn 데이터를 기반으로 pretrained BERT 모델인 LiBERT를 만들었습니다. Corpus는 BERT가 위키피디아 + book corpus인 반면, LiBERT는 search query, member profile, job docs, help center 데이터를 이용해 학습합니다. Layer도 BERT는 12, LiBERT는 6 layer이고, Hidden layer dimension은 BERT는 768, Libert는 512. 총 parameter 개수가 110M에 비하여 34M으로 1/3 감소되었습니다. 실제로 latency도 30%가 감소가 되었습니다.
두 번째는 offline으로 미리 계산된 embedding을 사용하는 것입니다. Offline으로 미리 임베딩을 만들어서 key, value 쌍으로 store에 저장을 합니다. 여기서 key는 document id이고, value는 embedding vector입니다. 이 store는 daily로 갱신이 됩니다. 이렇게 embedding store가 있고, on the fly에서는 query가 유입이 되면 retrieval 과정을 거치고, Embedding store에서 retrival 된 doc id를 기준으로 fetch 합니다. 그러면 doc id에 해당하는 vector이 나오고 그 embedding vector을 DeText Model로 보내서 최종 랭킹을 만듭니다.
이 과정에서 추가적인 computation cost는 network communication cost만 들게 됩니다. Online에서 많은 문서를 빠르게 modelling 하는 것과 BERT를 serving 하기 위한 방법에 대해서 알아보았습니다.

학습에 사용한 데이터는 LinkedIn에서 2개월간의 트래픽에서 샘플링된 clickthrough data입니다. People Search는 500만 쿼리와 문서들, Job search는 150만 쿼리와 문서들, Help center는 34만 쿼리와 문서들, 그리고 평가 관련해서는 offline, online 평가 지표는 회사 기밀이라서 baseline 기준으로 상대 값만 표기합니다. baseline은 트리 기반 앙상블 모델인 XGBOOST 모델을 사용하였고, LinedIn Search Engine에서 최적화가 되었습니다.
사용하는 Feature는 Text matching Features로 cosine similarity, jacquard similarity, semantic matching feature를 사용하였고, Personalization feature는 검색하는 사람과 개별 profile 과의 소셜 네트워크 간의 거리 등을 사용하였고, Document popularity feature는 개별 profile의 static 한 rank feature와 clickthroughs rate 등을 사용하였습니다.

Search ranking에 대한 실험 결과를 공유했습니다. 전반적 결과표는 Table 5에 있습니다. DeText-MLP는 오직 traditional feature 기반의 MLP, LTR layer가 존재하는 모델입니다. 기본적으로 DeText-MLP 보다는 DeText-CNN, LiBERT가 훨씬 좋은 성능을 내고 있으며, 그중에서도 DeText-LiBERT model이 각 컬렉션에서 가장 좋은 성능을 내고 있는 걸 볼 수 있습니다. 그리고 컬렉션마다 다 성능이 개선되긴 했지만 Help Center에서 가장 큰 개선이 이뤄졌는데, 이는 컬렉션의 특징 때문으로 파악을 합니다.
예를 들어 Help Center는 유사 내용을 포함하지만 다양한 시나리오로 표현이 되는 문서가 많습니다. 예를 들면, “how to hide my profile updates” 와 “sharing profile changes with your networks” 는 의미론적으로는 유사한 내용이나 표현을 다르게 한 문서입니다. 이런 컬렉션의 경우 좀 더 큰 개선을 가지고 왔습니다.
People Search 경우는 exact matching이 중요한 컬렉션입니다. 예를 들어 Twitter과 facebook은 워드 임베딩은 비슷하지만 정확하게 결과를 찾아 줘야 하는 문제가 있습니다.
Job Search의 경우 Help Center Search와 People Search의 중간입니다.
그리고 LiBERT와 BERTbase 간의 비교 실험도 하였습니다. People Search, Job search는 DeText-LiBERT가 상당히 개선이 되었지만 Help Center는 결과가 거의 유사한 것으로 알 수 있습니다.
이는 help center 또한 어휘 구성이 위키피디아랑 유사하기 때문에 LiBERT를 사용하나, BERTbase를 사용하나 비슷한 결과를 얻을 수 있습니다. 그러나, Libert가 BERTbase보다 1/3 파라미터만 사용함으로써 가치가 있다고 판단합니다.
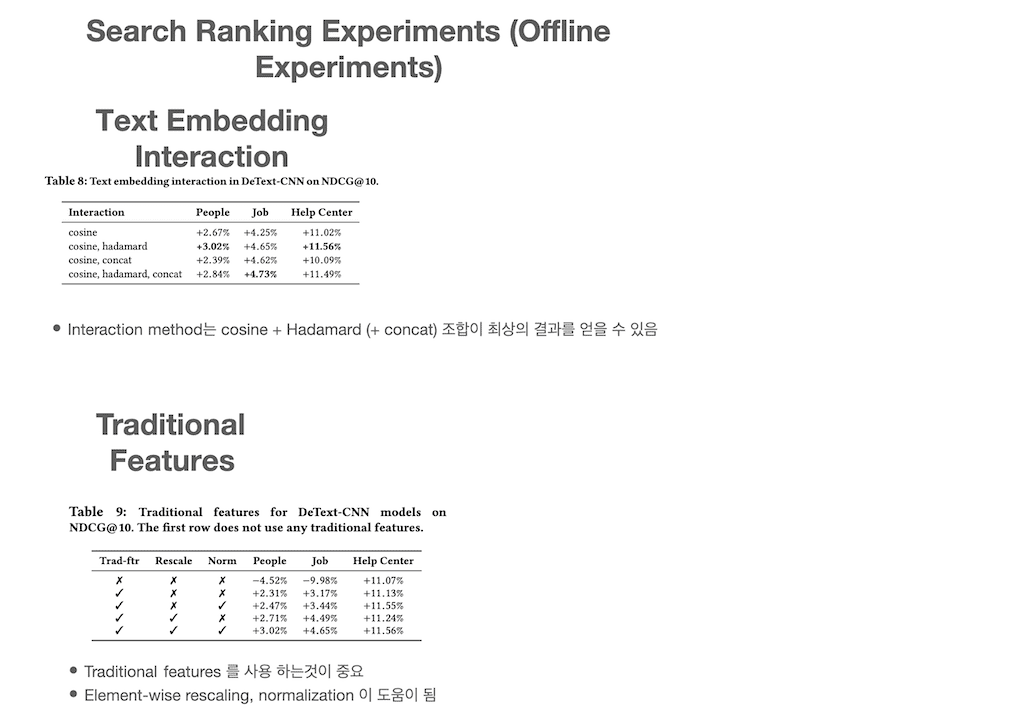
다음은 DeText의 Interaction layer에서 사용하는 interaction method를 어떠한 조합을 사용하는 게 가장 최상의 결과를 얻는 것인가에 대한 실험입니다. Cosine similarity와 Hadamard product를 함께 사용하는 것이 가장 좋은 성능을 냈고, Job Search에서는 Cosine similarity와 Hadamard product, concatenation을 함께 사용하는 것이 가장 좋은 결과를 냈습니다.
다음 실험은 Traditional features를 사용하는 것이 얼마나 중요한지를 알아보는 실험입니다. 첫 번째 결과인 아무것도 사용하지 않았을 때는 base model 보다 한참 떨어진 성능을 보입니다. 그 외 element-wise rescaling, normalization도 도움이 됩니다. 그러나 Help Center 컬렉션은 traditional feature 사용 여부에 크게 영향을 받지 않은 건 특정 domain knowledge가 있는 컬렉션이 아니라서 생기는 현상입니다.

다음은 Multiple field 사용에 대한 실험입니다. 이 실험에서는 traditional features를 제외하였기 때문에 기본적으로 baseline 보다 -로 됩니다. Single Field로 실험할 때는 문서에서 가장 중요한 field를 1개 선정해서 사용했습니다. 실험 결과에서 보는 것과 같이 Multiple Fields를 사용하는 게 결과적으로 더 나은 성능을 보입니다.

Online 환경에서 실험한 결과입니다. 온라인 실험은 2주 이상 20% 이하의 트래픽으로 각 모델을 적용시켜본 결과입니다. LiBERT 모델은 daily로 embedding store를 새로 생성하였습니다. Job Search 같은 경우는 새로운 Job posting이 너무 빈번하기 때문에 daily embedding store를 생성하는 것이 맞지 않아서 제외하였고, 향후 과제로 남겨 두었습니다. People search, help center search에서 DeText-LiBERT가 일괄되게 우수한 결과를 보입니다.

마지막으로 people search에서 all-decoding, two pass ranking, pre-coumption에 따른 latency 실험입니다. 먼저 A/B 테스트에서 all-decoding을 하나 two pass ranking을 하나 관련성 차이는 없었고, time은 two pass ranking이 훨씬 빠른 걸 확인할 수 있습니다. DeText-LiBERT와 DeText-BERTbase 비교에서도 DeText-LiBERT가 성능이 빠른 것을 볼 수 있습니다.
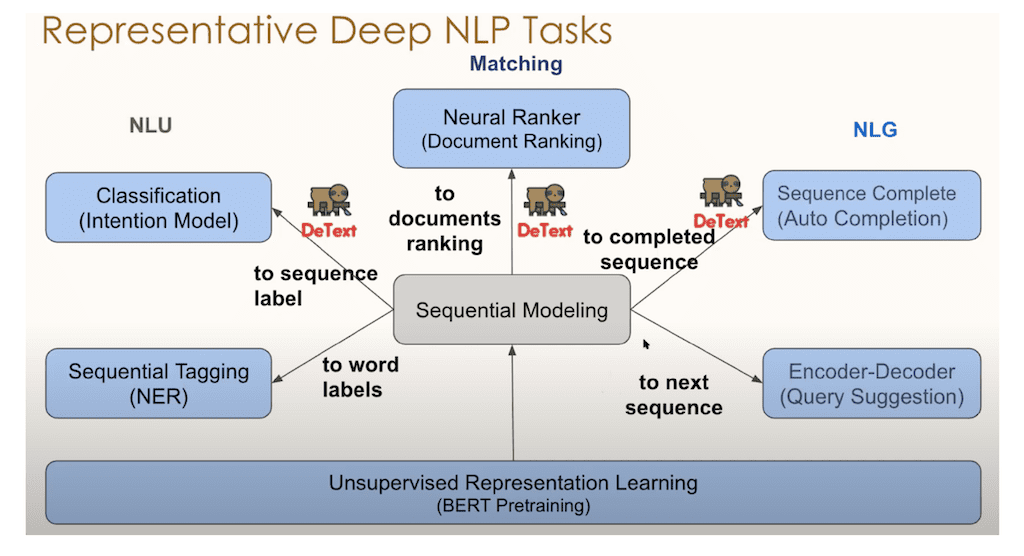
마지막으로 DeText를 이용해서 어떠한 Application으로 확장할 수 있는지에 대해서 말씀드리겠습니다. 위 그림에는 다양한 NLP Task 있습니다. DeText를 이용해서 이 논문에서는 Document Ranking에 대한 적용 내용을 말합니다. 그 외에도 classification 류인 Query Intent 분류를 한다거나, Sequence Complete 인 Query Auto Completion 등 다양한 NLP Task에 적용이 가능합니다.
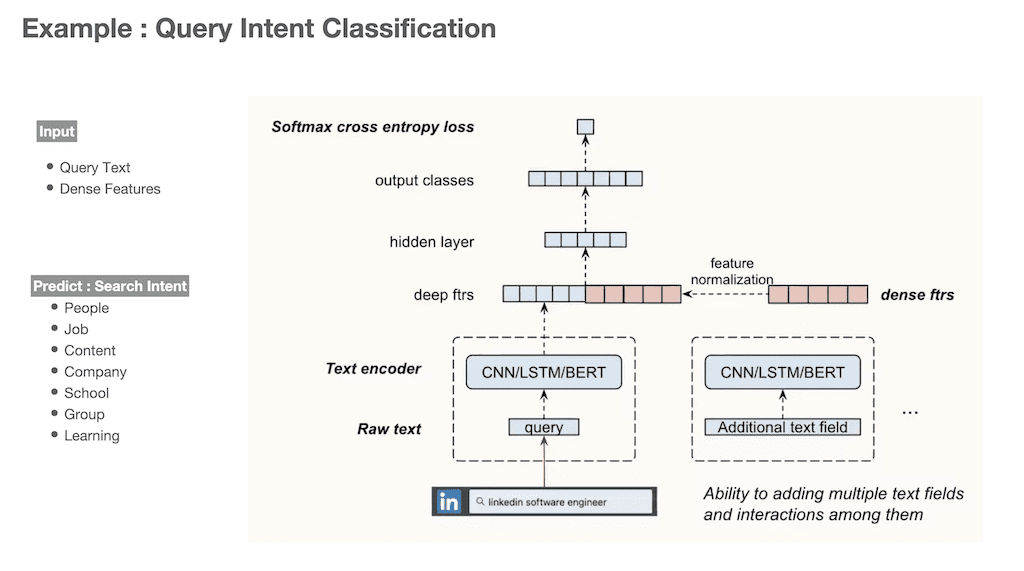
Query Intent classification을 예로 들었습니다. 검색 창에서 Query가 입력이 되면 Query의 needs가 어떤 의도의 검색인지를 파악해야 할 필요가 있습니다. 예를 들면, LinkedIn에서 people search인지, job search 인지 등을 파악해서 해당 intent에 맞게 결과를 제공해주어야 합니다.
DeText를 이용한 query intent에 관한 layer 구조입니다. Input text는 query이고 DeText의 layer 단계를 거치고 마지막으로 LTR이 아닌 softmax cross entropy loss를 통하여 하나의 search inent를 prediction 합니다.

결론입니다. Job Recommendation와 Query Auto Completion 에도 DeText를 적용하여 Baseline 보다 더 좋은 성능을 얻을 수 있었다고 합니다.




댓글