안녕하세요 콥스랩(COBSLAB) 입니다.
오늘 소개해 드릴 논문은 ‘Competition-Level Code Generation with AlphaCode’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘AlphaCode’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상 링크: https://youtu.be/c7jCWU_ChjE)

코딩을 작성해주는 인공지능 모델을 개발하려는 목적은 개발자들이 더 생산적인 프로그래밍을 할 수 있도록 하고, 일반인들이 코딩 교육을 받을 때 접근하기 쉽게 하도록 하기 위함입니다. 하지만 기존에 자동 코딩을 위한 인공지능 모델은 단순한 코드를 작성하는 정도에 불과한 수준이라서, 실제 알고리즘 이해를 기반으로 사람처럼 복잡한 코드를 작성할 수 있는 인공지능 모델을 만들고자 했습니다.

모델이 얼마나 잘 맞추는지는 직접적으로 측정할 수 없어서 간접적으로 측정하는 방법을 사용했는데, n@k는 총 K개의 후보군들 중에 n개의 알고리즘을 제출하는 것을 의미합니다. 예를 들면, 한 문제당 n번 정도 제출할 수 있도록 limit을 두고 총 K개 후보군들 중에서 일부를 골라서 제출하는 방식입니다. 그래서 n번 제출했는데 최소 한 번 이상 통과가 되면 해당 문제는 맞혔다고 인정하는 방식으로 이 모델 정확도를 측정합니다.

해당 방식에서는 transformer 모델을 가지고 Pre-training 하고 Fine-tuning 하는 방식을 사용하였습니다. Pre-training의 경우 대중적인 다양한 프로그래밍 언어들로 작성된 모든 코드 파일들을 포함하였고, 다만 1MB 보다 크거나 1000자 이상의 코드가 적혀 있는 파일은 자동으로 생성된 코드일 것이라고 추측하여 필터링하기 위해서 제외하였다고 합니다.
이 모델 자체가 알고리즘 문제를 풀 수 있도록 설계하려고 해서 Fine-tuning의 경우는 알고리즘 문제 관련 데이터들로 사용하였습니다. 그래서 기존 Descrioption2 Code, CodeNet같이 알고리즘 문제를 풀 수 있는 모델 관련해서 해당 기존 연구에서 사용한 데이터 + Codeforces 사이트에서 스크랩한 데이터를 추가하였습니다. Codeforces 데이터의 경우 Problems, Solutions, test cases로 구성되었습니다. meta data는 완전히 삭제하지는 않고 포함하는 데이터가 있습니다.
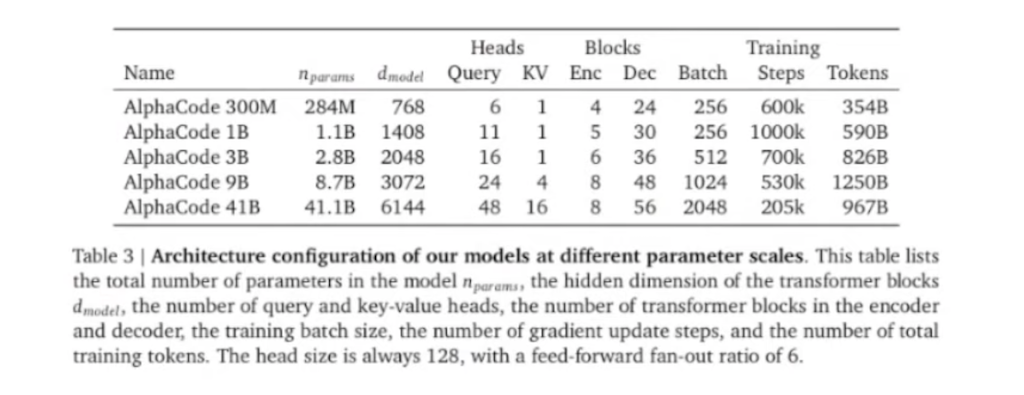
모델을 학습시키고 샘플을 생성하고 최종 알고리즘 대회에 제출하는 과정을 설명하겠습니다. 모델 Architecture는 (encoder-decoder) 구조를 갖춘 transformer를 사용하였습니다. 문제 설명 부분을 encoder에 넣어서 decoder에서는 솔루션이 나오는 방식으로 사용해서, attention이 양방향으로 가서 description을 이해합니다. encoder 레이어가 decoder 레이어에 비해 수가 적은 것은 decoder는 직접적으로 솔루션 아웃풋이 나와서 줄이기가 어려운데, 그래도 학습이 빠른 프로세스로 효율적으로 동작할 수 있도록 하기 위해서 shallow encoder를 사용한 것을 확인할 수 있습니다.

그리고 Multi-query attention을 사용했는데, 이 부분은 attention head별 query는 다른데 key, value는 동일하게 사용한 방식입니다. tokenizer는 SentencePiece tokenizer를 사용하였습니다. 그래서 Multi query attention의 경우 head별로 각 query는 다르지만 key와 value는 공통으로 사용하는 방식입니다.

Pre-train의 encoder에서는 MLM task를 사용하였고, decoder에서는 다음 토큰을 예측하는 과제를 사용하였습니다. 1B parameter 모델의 경우 배치 사이즈는 256, 스텝 수는 10^6을 가졌습니다. Optimizer는 Adam 계열의 Optimizer를 사용하였습니다.

Fine-tuning도 마찬가지로 encoder에서는 MLM task를 decoder에서는 next-token prediction task를 사용하였습니다. Fine-tuning 단계에서는 학습이 잘 되게 하기 위해서 다양한 테크닉들을 사용했습니다.
- Tempering : regularization 할 때 사용합니다. 최종 아웃풋이 나온 확률 값에 0.2 정도로 나눠서 아웃풋 값들을 튀지 않게 해서 Overfitting을 방지하였습니다.
- Value conditioning & prediction: 학습에 성공한 코드와 실패한 코드를 모두 넣다 보니, 그 모델이 헷갈릴 수도 있어서, 각 제출 코드에 성공, 실패 정보를 encoder에 인풋, 즉 설명 부분에 같이 넣어서 제출 결과를 맞추도록 하였습니다.
- Gold: 학습에서는 next-token prediction을 잘하는 게 목표지만 Evaluation에서는 실제로 정답이 되는 코드를 생성해내는 게 목적이므로, 이러한 목적 차이에 따라서 높은 확률 값을 가진 토큰에 더 집중하도록 하는 방식입니다.

Fine-tuning 시킨 다음에는 솔루션으로 제출하기 위한 샘플들을 많이 생성하였습니다. 절반은 파이썬으로 된 샘플을 생성하였고 절반은 C++로 작성된 샘플을 아웃풋으로 받았습니다.

다음으로는 Filter & Cluster입니다. 실제 알고리즘 문제에서도 example 케이스는 실제 테스트해볼 수 있는데, 거기서 통과하지 못한 코드들은 모두 제거하면 99퍼센트가 이 단계에서 제거되었습니다. 그리고 Clustering은 기존 알고리즘을 제출하는 데 사용하는 모델이 아닌 Test input generation 모델을 별도로 만들었습니다. Test input generation 모델을 통해서 어떤 인풋 값을 생성해서 이 값들을 각 코드에 넣어보면, 아웃풋 값이 동일한 코드들이 서로 비슷한 알고리즘이나 비슷한 Clustering을 하였습니다. 그 후 개수가 많은 순으로 Large 사이즈부터 small 사이즈까지 각 Cluster에서 1 개씩 뽑아서 10개가 될 때까지 선정해서 10개의 코드를 최종 제출했습니다.
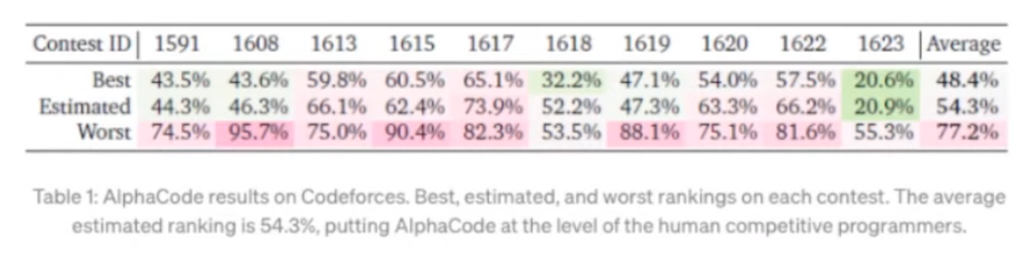
다음은 결과입니다. 해당 사이즈를 가진 AlphaCode 모델이 성능이 제일 좋았기 때문에, 41B개 parameter를 가진 AlphaCode 모델과 9B parameter를 가진 AlphaCode 모델을 앙상블 한 것을 기준으로 하였습니다. 이 결과는 10 개의 contests의 평균값이고 상위 절반 정도 되는 성적인 것을 확인할 수 있습니다.

확실히 모델 사이즈가 클수록 문제를 많이 맞히고 성능이 점점 좋아진다는 것을 확인할 수 있습니다.
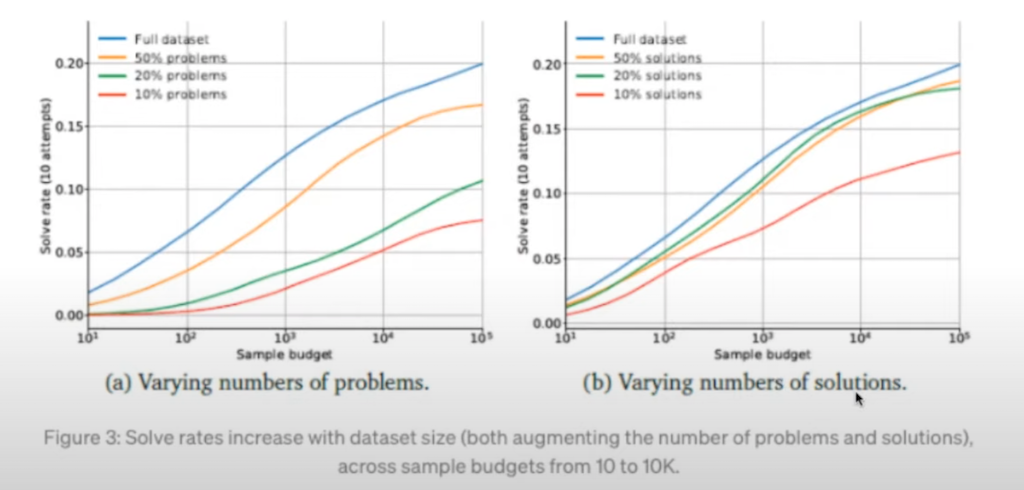
(a) 그래프는 데이터셋에서 학습할 때 문제를 얼마나 다양하게 하는지, (b) 그래프는 솔루션을 얼마나 다양하게 하는지 나타낸 것입니다. 확실히 문제도 다양해지고 솔루션도 다양해졌을 때 실제로 문제를 더 잘 푸는 것을 확인할 수 있습니다. 그리고 pass@k는 10번만 제출한 게 아니라 다 제출해 본 것인데, 샘플로 나온 것들 중 하나 이상은 각 문제마다 맞힐 확률이 높아져서 sampling space가 커짐에 따라 잘 맞추는 것을 확인할 수 있습니다.

다음은 최소한 한 개 이상의 샘플이 example test를 통과하는 실험을 한 것입니다. 모델이 example test에서 테스트를 높게 통과한 것을 확인할 수 있습니다.

Filtering과 Clustering이 solve rate에 미치는 영향 그래프입니다. 빨간 선은 Filtering과 Clustering을 전혀 하지 않은 경우여서, solve rate가 굉장히 낮은데, 모든 것을 무제한으로 할 수 있게 한 파란색이 제일 Solve rate가 높았고, 노란선은 Filtering 하고 Clustering까지 한 다음에 10번 제출한 것입니다.

자동 코딩 생성 AI 들과 AlphaCode를 비교한 지표입니다. 아무래도 모델마다 성능을 측정했던 방식이 다르기 때문에 그대로 성능을 비교할 수는 없겠지만, 그래도 최대한 기존 모델에서 사용한 방식을 맞추어서 성능을 비교하려고 하였습니다. AlphaCode 같은 경우는 기존 모델들보다 Introductory task를 제외하면 Codex 보다도 성능이 우수한 것을 확인할 수 있습니다.
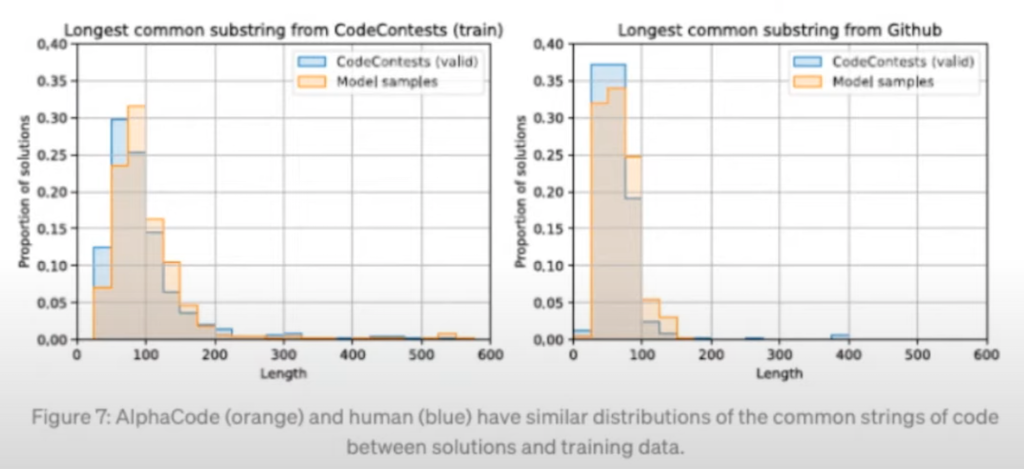
다음은 AlphaCode가 알고리즘을 이해한 것이 아니라, 어떤 것을 암기만 잘해서 베껴서 제출한 것이 아닌지 테스트를 해보기 위해서 각 코드들 중에 제일 긴 문자열을 가지고 문자열이 실제 모델에서 결과로 나온 것과 데이터셋에 있던 것이 얼마나 유사한 지를 분포로 나타내었습니다. 파란색은 사람이고 AlphaCode가 오렌지색입니다. 오렌지색과 파란색이 굉장히 유사한 것을 확인할 수 있고, 솔루션중에서 겹치는 부분이 많지 않다 보니까 AIphaCode가 베껴서 코드를 작성하는 것이 많지 않은 것을 확인할 수 있습니다.

이러한 모델들을 개발했을 때 장점과 단점을 설명드리고 마무리하겠습니다. 해당 논문에서 말하는 것은 기존에 있는 github 등 에서 공개된 데이터를 학습하기 때문에 소유권 문제, 지적 재산권 문제도 있을 수 있고 다른 AI모델과 마찬가지로 계속해서 특정 경향의 코드를 작성하는 과정에서 bias가 생길 수도 있고 학습한 데이터가 옛날에 쓰던 데이터이고 옛날에 작성하던 방식으로 된 코드이기 때문에, 보안에 취약한 코드를 생성하게 될 수도 있다고 합니다.
장점으로는 코드를 작성하는 모델이기 때문에 실제 아웃풋 값을 사람이 다 이해하는 코드 여서 더 잘 해석할 수가 있고, 자동화 부분은 이 논문에서는 자동화 코딩을 만드는 경우에, 사람들의 일자리를 빼앗는 것이 아니라 오히려 리소스를 효율적으로 사용할 수 있어서 도움이 될 수 있다고 주장하고 있습니다.




댓글