안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/tdB0Y6hMtcg)
간단하게 Few shot에 대해서 살펴보고 Natural Language Inference가 무엇인지에 대해서 설명을 드리면서 시작하도록 하겠습니다.

Natural Language Inference는 자연어 추론이라는 한국말로 알려져 있는데 Input으로 두 개의 문장이 주어집니다. 첫 번째 문장을 Premise로 전제 그리고 두 번째 문장은 Hypothesis로 가설로 주어지는데, 전제가 주어지면 가설이 전제에 따라서 참인지 중립인지 혹은 모순이 있는지를 맞추는 task로 이해하시면 됩니다.
Few shot learning은 총 세 가지 경우로 나눌 수 있는데 첫번째 Zero-shot입니다. Zero-shot 같은 경우에는 task description이 주어지고 바로 예측이 수행되는 형식인데 만약에 Translate English to French, 영어에서 프랑스어로 번역을 하는 학습에 대한 설명이 주어지고 cheese는 mask에서 이 token이 무엇인지 예측하는 방식으로 주어집니다.
두 번째 One-shot는 똑같이 task description이 주어지는데 한 가지 예시를 추가적으로 주고 그다음 예측이 진행되는 방식입니다.
Few-shot은 다수의 예시가 주어진 다음에 예측이 수행이 됩니다.

기존 NLP task들은 Labeled examples를 가지고 학습을 하는데 Labeled examples을 구축하는 데에는 매우 많은 코스트가 소모가 되고 이에 따라 Labeled examples이라고 하더라도 소규모로 구축이 될 경우에는 이 Supervised learning이 적용이 되더라도 성능이 떨어지는 문제가 존재한다고 설명합니다.
예를 들어 T1, T2가 Input으로 주어지고 해당하는 문장에 대한 label이 각각 주어졌을 때 과연 T3를 이 두 문장만 보고 예측을 할 수 있냐라면 솔직히 이것에 대한 정확도는 상당히 떨어진다고 말합니다.
그래서 이 논문 저자들은 이러한 두 문장에 대해서 단순히 label이 아니라 어떤 문제를 풀어야 되는지 description을 제공을 하게 되면 이 적은 수의 example로도 좀 더 나은 성능의 예측을 할 수 있다는 것을 설명을 하고 있습니다.
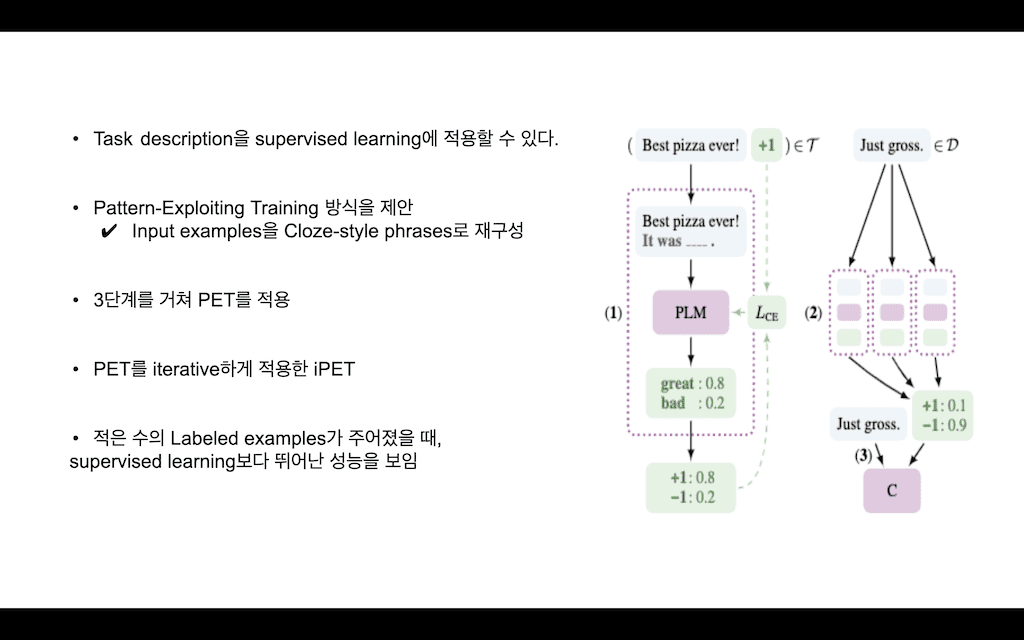
task description을 Supervised learning에 적용할 수 있다고 말을 하는데 이 방법이 Pattern Exploiting Training 방식입니다. 간단하게 설명을 드리면 input examples를 Cloze style phrases로 재구성을 합니다. 그래서 3단계를 거쳐 PET가 적용이 됩니다.
예시를 살펴보면 만약에 Best pizza ever!이라는 문장이 주어지고 이에 대한 label이 트레이닝 데이터셋에 포함이 됩니다. 그러면 Best pizza ever!이라는 문장이 PET에서 Best pizza ever! It was ____라는 패턴을 가지는 문장으로 변형이 되어서 PLM(Pretraining Language Model)에 Input으로 들어가고 PLM은 Mask token을 예측하는 방식으로 학습 방법이 변경이 됩니다. 그렇게 돼서 예측하는 이 결괏값을 가지고 실제 label과 crossentropy Loss를 계산해서 학습을 하게 됩니다.
두 번째 단계는 실제로 패턴들이 다수 존재할 수가 있는데, 다수의 패턴들을 가진 모델들이 존재한 다음에 unlabeled 된 데이터에 대해서 추론을 진행합니다. 다음에 추론 결과들을 ensemble 해서 이 소프트 label을 적용해서 Unlabeld 데이터를 labelIng을 한 다음에 데이터셋을 가지고 최종 Classifier가 부착된 모델을 학습하는 방식이 PET 방식이라고 할 수 있습니다.
저자들은 PET 방식을 제안함과 동시에 PET를 여러 번 적용하게 되면 또 성능이 더 오르게 된다는 것을 말하고 있고, 그래서 적은 수의 labeled example이 주어졌을 때 Supervised learning보다 더 뛰어난 성능을 보여주는 것을 설명하고 있습니다.

Pattern Exploiting Training에 대해서 설명을 드리도록 하겠습니다.
이 논문에서 말하는 Notation이 몇 가지 있는데 M은 Masked Language Model 그리고 V는 Vocabulary, 이 빈칸은 Mask Token, 그다음에 L은 Labels, A는 Target classification task를 의미합니다.
Input은 여러 개의 문장으로 줄 수가 있는데 여러 개의 문장이 하나의 x로 치환이 되고, P는 Pattern 그리고 v는 verbalizer로 이 label이 특정 Vocabulary로 매핑이 되는 함수입니다. 그래서 이런 패턴과 verbalizer가 pair를 이루게 되어서 Pattern verbalizer pair라고 명명을 하고 있습니다.
예시입니다. P(a, b) 문장 a, b에 대해서 패턴이 주어지면 패턴은 a? ___, b. 형태로 주어지게 되고
실제 이런 문장에 대해 label이 y0, y1이 있다고 생각하면 y0는 vocab내에 Yes라는 token으로 치환이 되고, y1은 vocab내에 No라는 token으로 치환이 됩니다. 그래서 실제 x가 문장 x1(Mia likes pie), x2(Mia hates pie)으로 Input이 주어지게 되면, Input이 패턴에 적용이 되어서 Mia likes pie?_____, Mia hated pie로 변경이 됩니다.
그래서 Mask token에 들어갈 label이 실제 Verbalizer로 변형이 된 vocabulary고, 모델은 Mask token을 예측하는 방식으로 학습을 하게 됩니다.
두 번째 예시입니다.
문장 1: 빠른 답장과 간편한 체크인, 깨끗한 집 좋았어요.라는 문장과
문장 2: 체크인이 복잡했어요.
라는 문장이 주어졌을 때, 정답은 실제 서로 모순이 있다는 것을 저희는 알 수 있습니다. 그래서 문장 1,2가 실제 x가 되고 이 x가 패턴을 형성할 수 있습니다. '문장 1' 그래서 '문장 2'. 이 문장은 거짓(verbalizer)입니다.라는 패턴이 만들어지게 됩니다.
그래서 verbalizer가 실제 label이 세 가지가 존재하는데 각 세 가지에 대해서 Entailment는 참으로 바꿔주고, Contradiction은 거짓으로 바꿔주고 neutral은 중립으로 바꿔주면서 해당 Mask token의 참, 거짓 중립을 예측하도록 수행할 수 있게 바꿔 줍니다.

PVP가 실제 학습이 되고 어떻게 추론이 진행되는 것을 살펴보겠습니다. Input에 대한 패턴이 주어지면, 그 패턴은 Mask token에 대한 verbalizer가 모델을 예측하게 됩니다. 그러면 해당 Mask token에 대한 logit값이 나타나게 되는데 그 값을 스코어라고 말하고 있습니다. 그러면 해당 스코어의 logit값을 Softmax를 하게 되면 확률분포 값으로 바뀌게 됩니다. 이 확률분포 값을 실제 crossentropy Loss를 통해 학습이 진행되게 됩니다.

crossentropy Loss로만 학습을 하게 되면 논문에서 말하기를, 적은 수의 Training examples로 학습을 하게 되면 망각이 발생할 수 있다고 설명하고 있습니다. 그래서 Auxiliary Language Modeling이라고 해서 실제 crossentropy Loss에 기존에 알았던 MLM Loss를 추가하여 최종 Loss function을 구성하였습니다. 보통 crossentropy Loss보다 Mask Language Modeling Loss가 값이 더 크기 때문에 α값을 10^-4 정도 값으로 하이퍼 파라미터로 지정을 하여서 학습을 진행했다고 합니다.

다양한 Combining PVPs라고 Pattern Verbalizer Pair가 다양하게 존재하는데, 다양한 패턴을 가지는 이 모델들이 서로 Fine-Tuning이 되고, 이 Fine-Tuning이 된 모델들을 ensemble 하여서 Unlabeled examples에 대해서 Soft labeling을 진행하게 됩니다. 스코어 값이 모델별로 나타나게 되고, 해당 모델을 어떤 가중치에 따라서 평균을 내게 되면 ensemble된 스코어값이 나오게 됩니다.
저자들은 이 가중치에 대해서 총 두 가지 방법을 제안했는데, 가중치를 1로 두었을 때를 말하고 있습니다. 가중치를 1로 두었으면 단순 평균을 의미하는 것이고, 두 번째 제안하는 방법인 accuracy를 이용하는 방법인데 PVP가 주어졌을 때, Fine-Tuning 하기 이전에 한번 트레이닝 셋에 대해서 accuracy를 뽑아냅니다. 그럼 각 모델별로 accuracy가 나오는데, accuracy를 비율에 따라 가중치를 주는 방식을 채택하고 있습니다.
그래서 마찬가지로 logit값을 통해 Softmax를 통해 확률 분포로 변환해서 Unlabeld 데이터를 Soft labeled 된 데이터로 변경을 하고, 새로운 학습 데이터 Tc를 생성하고 활용해 새로운 PLM C를 학습하게 됩니다.

iPET와 PET를 같이 설명한 부분입니다.
PET를 먼저 살펴보시면 트레이닝 셋이 주어지면 각 트레이닝 셋 별로 네 가지 PVP가 존재하는 것으로 확인이 되는데, 각 PVP별로 모델 4개가 Fine-Tuning이 됩니다. 그러면 PVP는 Unlabeld 데이터에 대해서 그 추론이 진행되게 되고, 이 추론 값을 합쳐서 커다란 Unlabeld 데이터와 기존 데이터와 합쳐져 가지고 새로운 데이터셋을 만들어내게 됩니다.
저자들은 PET가 진행되면서 단순히 한 번만 진행했을 때는 각각의 PVP에 대해서 서로 상호 간에 연결이 별로 없다고 말하고 있어서 PVP를 여러 번 진행하는 iPET 방법을 진행하게 됐습니다.
그림을 보시면 똑같은 PVP가 여러 번 반복이 됩니다. 그래도 PET랑 조금 다르게 적용이 되는 건 실제 이런 모델들이 다 적용이 되는 게 아니라, 랜덤 하게 선택되어서 학습 데이터셋이 새로 만들어지게 됩니다. 그래서 학습 데이터셋으로 다시 모델이 생성이 되고 랜덤하게 선택되어서 또 학습 데이터를 구축하게 됩니다.
그림에서 보시는 것처럼 T가 그림에서 원모 양 크기로 나타내는데 점점 커지는 것을 확인할 수 있습니다. 논문에서도 Unlabeld 데이터에서 Soft labeling 데이터를 뽑아낼 때, 일정 비율을 가지고 특정 크기만큼 만 선택해서 여러 번 진행하는 게 더 성능이 좋다고 말하고 있습니다.

Experiment 부분을 설명드리기 전에 어떤 패턴들이 있는지 설명을 드리도록 하겠습니다. 문장 간 구별은 “||”를 활용해서 진행이 됩니다. Yelp이라고 하는 데이터셋은 Review's text를 통해 1점부터 5점까지 별점을 부여한 데이터셋입니다.
그래서 논문 저자들은 총 4 개의 형식들의 패턴을 제공했습니다. 1번 같은 경우에는 verbalizer를 통해 terrible이라는 단어를 바꾸고, 2번은 bad, 3번은 okay, 4번은 good, 5번은 great. 이런 식으로 특정 label에 대해 vocabulary로 매핑하는 것을 확인할 수 있습니다.

실제로 AG's News 같은 뉴스 토픽 분류 데이터셋 같은 경우에는 총 6가지의 패턴을 활용하였고, 각 뉴스 토픽에 따라서도 똑같이 verbalizer를 활용해 이러한 단어로 매핑을 시켜주었습니다.
Yahoo 같은 경우에도 똑같은 패턴을 활용했다고 하였고, 10 개의 카테고리가 존재합니다.
MNLI 데이터셋으로 두 가지 패턴을 활용하였고, 이 경우 첫 번째 verbalizer는 Wrong, Right, Maybe이고, 두 번째 verbalizer는 No, Yes, Maybe로 총 두 개의 경우로 나누어서 학습이 진행되었다고 합니다.
마지막 X-Stance라는 데이터셋은 Multilingual stance detection 데이터셋으로 사회적 이슈에 관한 질문이 주어지고, 그에 대한 답변이 주어질 때 이 답변이 질문에 찬성인지 반대인지 분류하는 문제입니다. 이 형태로 패턴을 나누게 되고 실제 이 verbalizer 같은 경우에는 영어로 Yes or No, 그리고 Multilingual이기 때문에 프랑스어로 Yes or No가 있고, 다음에 독일어로 Yes or No 이렇게 총 세 개 verbalizer로 구성이 됐습니다.

결과입니다. 트레이닝 데이터셋이 없을 때 10개 50개 100개 1000개로 실험이 진행이 됐는데, 0개일 때 UnSupervised 같은 경우에는 PVP가 하나만 적용이 됐을 때를 말하고 있습니다.
PVP가 여러 개가 있는데 추가 학습 없이 바로 Inference가 진행이 됐다고 보시면 될 것 같고 실제 avg보다 max가 좀 더 값이 높은 것을 확인할 수 있고 iPET가 적용이 됐을 때, 더 많은 성능 향상이 있었다고 말을 하고 있습니다. 똑같이 example이 10개나 50,100개 정도 될 때는 각각 Supervised learning과 비교를 했는데 PET나 iPET가 Supervised보다 확실히 성능이 더 높은 것을 실제 확인할 수 있습니다.
그리고 트레이닝 셋이 1000개 정도까지 되면 AG's 같은 경우는 Supervised랑 PET가 거의 같은 성능을 보이는데, 결국 이 트레인 데이터셋이 너무 많아지면 Supervised도 어느 정도 성능 향상이 따라오게 된다라는 것을 설명을 하고 있습니다.
오른쪽 결과는 트레인 데이터셋이 적을 때, UDA와 MixText랑 비교하는 결과인데 UDA와 MixText는 semi Supervised learning방식으로 back Translation을 이용해서 Data Augmentation을 한 방식입니다. 그래서 비슷한 Semi Supervised learning인데 PET가 이 두 가지 방식보다 더 높은 성능을 보인 것을 확인할 수 있습니다.

다음은 x-stance에 대한 실험 결과입니다. x-stance의 결과를 가지고 논문 저자들은 PET가 데이터셋이 많은 경우에도 잘 작동이 된다라는 것을 보여준다고 합니다.
그래서 독일어 데이터셋, 프랑스 데이터셋인데 이 데이터셋이 각각 11,000개, 33,000개인데 이런 데이터셋을 가지고 학습했을 때도 Supervised보다 PET가 좀 더 나은 성능을 보였다라고 설명하고 있습니다.
그래서 Multilingual task에서도 PET가 성능 향상을 가지고 있다고 설명을 하고 있습니다.

실험 결과를 가지고 몇 가지 분석을 진행을 했습니다.
첫 번째 Combininb PVPs에 대해서 분석을 진행하였습니다. 한 가지에 여러 개 PVP가 있는데 각각의 PVP에 대해서 최솟값에 대한 값 그리고 가장 큰 값 그리고 no distillation, uniform, weighted라는 방식의 PET를 비교를 했습니다.
no distillation는 그 스코어 값이 모델별로 계산이 되는 게 아니라, logit값을 단순히 뽑아내서 그 하드 보팅 한 걸로 파악이 되는데, 결국 no distillation 하는 것보다 uniform이나 weight 같은 가중치 평균을 냈을 때 좀 더 좋은 효과가 있다고 설명을 하고 있습니다.
물론 이때는 다 test 데이터셋이 10개 정도의 굉장히 적은 수에서도 이 정도 성능을 보이고 있다라고 설명을 하고 있습니다.
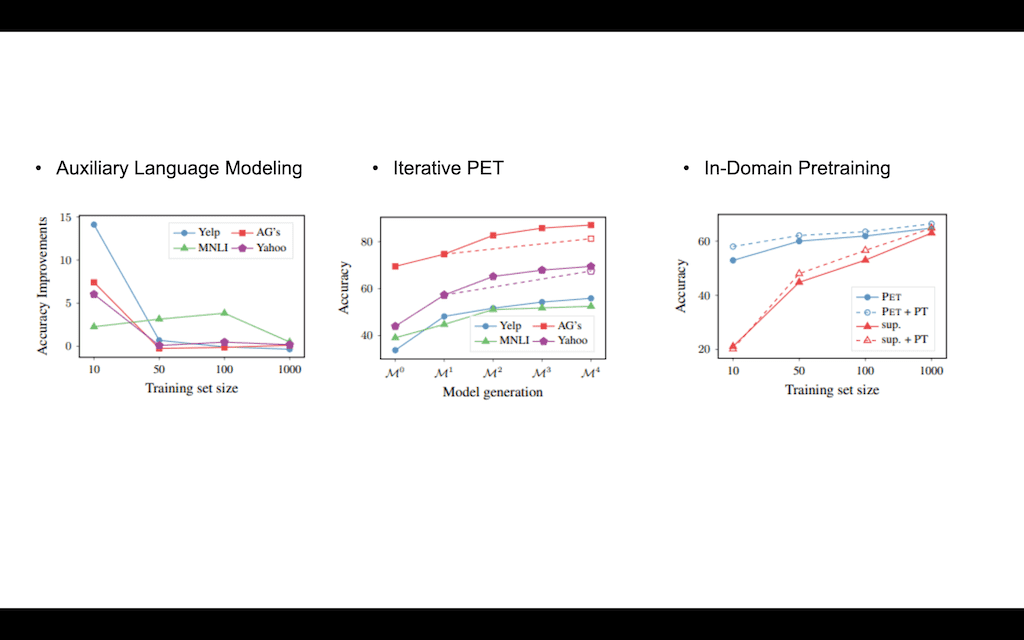
Auxiliary Language Modeling에 대해서 분석을 한 결과입니다. Auxiliary Language Modeling은 MLM Loss를 추가한 방식입니다. 그래서 테스트 셋 사이즈가 10개인 경우에는 accuracy Improvement가 상당히 좀 유의미한 결과를 가지고 있는 것을 볼 수가 있는데, 트레이닝 셋 사이즈가 커질수록 MLM Loss를 추가하는 게 큰 효과는 없다라고 설명을 하고 있습니다.
Iterative PET에 대해서 실험을 한 결과인데 각각 총 다섯 번의 PET가 진행이 되었고, 첫 번째 PET에서의 그것보다 진행이 될수록 accuracy가 증가하는 것을 확인할 수 있습니다. M1에서 일정 비율만큼 데이터셋을 추출해서 다음 데이터셋을 만드는데 이 점선에는 M1에서 한 번에 M4 사이즈만큼의 데이터셋을 추출해서 나온 결과입니다.
실제 이 결과를 토대로 저자들은 점진적으로 데이터셋을 늘리는 게 학습에 도움이 된다라고 설명을 하고 있고, 이렇게 한 번에 추출하게 되면 이 모델에 대해 no label 된 데이터가 좀 더 많아질 확률이 높아진다라고 설명을 하고 있습니다.
그다음에 In-Domain Pre-training은 해당 도메인에 대해서 Pre-training을 좀 더 진행한 것입니다 이 저자들은 PET가 Unlabel 데이터에 대해서 학습이 되어서 오로지 그 이유 때문에 성능이 향상이 된 것은 아니다는 것을 증명하기 위해서 이 실험을 진행했다고 합니다.
보시면 Supervised learning이 적용됐을 때랑 Supervised learning이 적용되기 전 Pre-training이 한 번 적용이 됐을 때 성능 향상이 있는 것을 확인할 수 있고, 그런 성능 향상이 있었어도 PET가 기본 Supervised learning의 Pre-training이 섞였을 때보다 성능이 더 높은 것을 확인할 수 있습니다.
논문 저자들은 PET가 단순히 In-Domain Pretraining 방식보다 더 좋은 방식이라고 말을 하고 있습니다.

결론입니다. PET 방식은 Cloze question pattern과 verbalizers pair를 활용해서 Pattern Exploiting Training 방식을 제안하였고, 초기 주어진 트레이닝 셋이 적을 경우 PET방식으로 semi Supervised learning을 활용해 큰 성능 향상을 이끌어 낼 수 있습니다.




댓글