안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Perceiver IO : A GENERAL ARCHITECTURE FOR STRUCTURED INPUTS & OUTPUTS’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Perceiver IO’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/rRQ5uBWB9EQ)

Perceiver IO는 Perceiver라는 기존에 있던 모델에서 General 하게 확장한 모델입니다. 그래서 이 모델을 알기 위해서 Perceiver에 대한 이해가 있어야 합니다. Perceiver 모델은 원래 Transformer 모델의 General 한 버전이라고 보시면 됩니다. 논문 제목에 나와 있듯이 General Perception with Iterative Attention이라고 되어 있는데 Attention 모델을 통해서 Input의 Modality를 확장을 시킨 논문이라고 보시면 됩니다.
기존에 Transformer 모델이 원래 자연어 처리 쪽에서 번역 모델로 처음에 제안이 되었고 성능이 워낙 좋게 나오다 보니까 비전쪽에서도 Transformer 모델을 많이 적용을 시키려고 시도를 해왔었는데 문제가 됐던 게 Input의 형태가 자연어 처리와 많이 다르고 pixel, channel까지 고려를 해서 Input에 넣어줘야 되기 때문에 Input이 커질수록 기존의 Transformer 모델이 기하급수적으로 커지는 단점이 있었습니다.
그래서 Perceiver 모델은 Input의 이미지, 비디오, 오디오, 3D point clouds 형태의 Input까지 모두 수용할 수 있는 모델입니다. 이 모델은 Attention 메커니즘을 통해서 latent 크기가 너무 커져서 쿼드라틱하게 computation 수치가 높아지는 기존의 bottleneck을 해결한 논문입니다.

기존에 Transformer 모델은 바로 Input을 key, query, value에 그대로 사용을 했었습니다. 그러다 보니까 Input이 사이즈가 커지면 Transformer 모델의 사이즈도 커지게 되는 단점이 있었습니다.
근데 이때 Input의 key, query, value 세 가지 매트릭스가 각각 계산이 되는데, 그러다 보면 Input 사이즈가 커지면 key에 대한 매트릭스, value에 대한 매트릭스, query에 대한 매트릭스 이 세 가지가 모두 커지게 되고, Transformer가 하나의 레이어로만 이루어진 게 아니고 depth도 크기 때문에 Input 사이즈가 커지면 Transformer 모델의 사이즈가 어마어마하게 커지는 단점이 있습니다. 그래서 Input의 max length도 한정이 되는 단점이 있는데,
Cross Attention 모델을 따로 떨어뜨려놔서 처음에 Transformer 모델에 넣어주기 전에 내가 원하는 latent 사이즈만큼으로 Input을 한번 줄여주는 부분이 있습니다. 다음으로는 Transformer 모델이 Self attention 구조로 sequential 하게, Iterative 하게 Input과 Output 사이즈는 똑같고 latent vector만 가지고 depth를 늘리는 부분이 있습니다.
그래서 depth를 좀 더 자유자재로 늘릴 수 있게 되었고, Perceiver 모델의 큰 contribution입니다. Perceiver 모델은 latent Transformer와 Cross Attention 메커니즘을 분리를 하게 되고, 이러한 구조가 Input이 아무리 길어도 latent 사이즈를 조절함으로써 기하급수적으로 모델의 사이즈가 커지는 걸 막을 수 있게 되는 모델입니다.
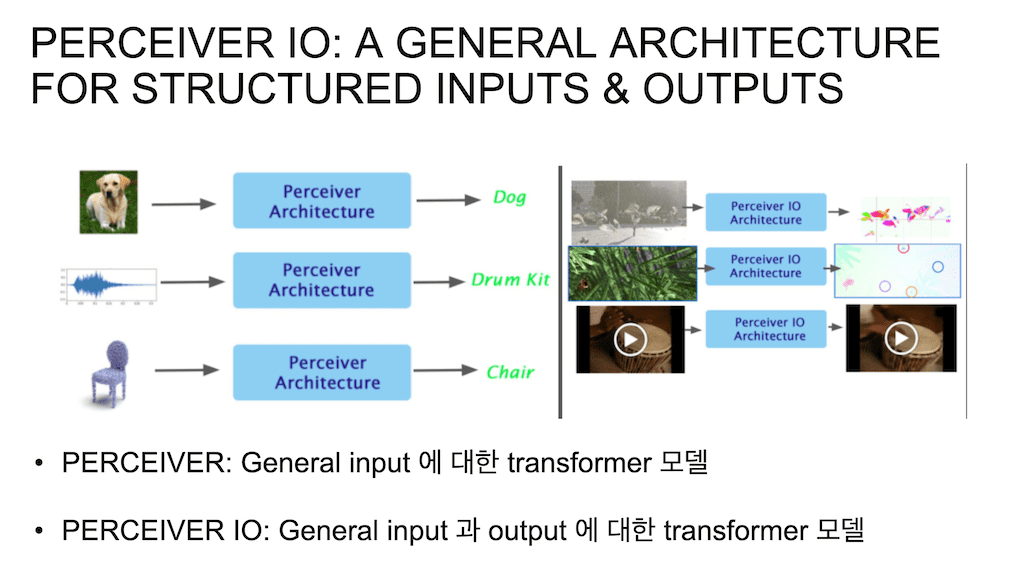
Perceiver IO가 Input을 General 하게 받고, Logits을 Output으로 출력을 시켜서 모델 자체는 classification 모델에만 적용을 할 수 있는 모델이었습니다. 그거에 관해서 새로 딥마인드에서 낸 논문은 General 한 Input을 받아서 또 General 한 Output을 출력을 하는 모델입니다.
왼쪽이 사진, 오디오, 3D 포인트를 받아서 Logit을 뱉어냈다면, classification을 수행을 했다면 Perceiver IO를 통해서는 영상을 받아서 Optical Flow를 낼 수도 있고, Auto encoder 형태로 사진이나 오디오나, 비디오나 다 압축시켰다가 다시 복원을 할 수 있습니다.
그 영상을 압축시켰다 복원을 시킬 때 영상만 복원시키는 게 아니고 영상에 해당하는 오디오, 영상이 어떤 영상인지에 대한 classification까지 동시에 수행할 수 있는, 자유자재로 Output의 형태를 바꿀 수가 있는 모델입니다.
Perceiver는 General Input에 대한 Transformer 모델이고, 그리고 Perceiver IO는 General한 Input과 Output에 대한 Transformer 모델이라고 보시면 됩니다.
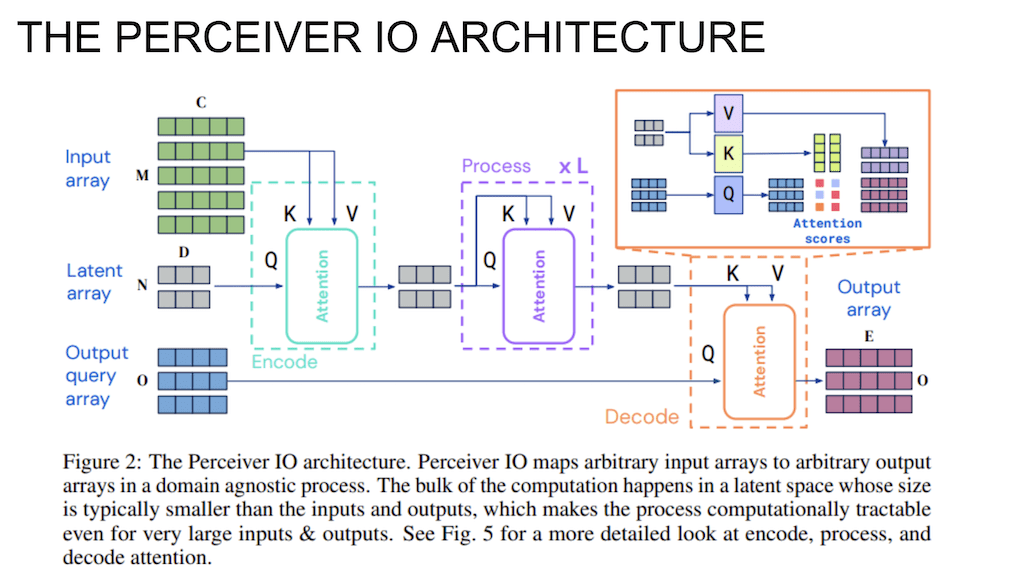
전체적인 구조입니다. Perceiver 모델과 유사합니다.
그래서 Input을 array로 크게 받고, 사이즈를 한번 조절을 해주고 이 latent vector를 Iterative 하게 Self Attention 구조를 통해서 계산을 시켜주고 Perceiver IO에서 유일하게 추가가 된 부분은 decoding 파트입니다. decoding파트에서는 Output query array를 통해서 내가 원하는 형태의 Output array를 출력을 시켜줄 수 있습니다.
그래서 이 부분을 하나하나 보도록 하겠습니다.

먼저 encoding 부분입니다. 예를 들어서 Input array를 비디오라고 하면 vector 하나하나가 이미지 프레임이라고 생각을 하고 이미지 프레임 하나하나를 vector의 형태로 쭉 2D array로 이어 붙이게 됩니다. 그래서 frame의 채널 정보도 vector의 형태로 이어 붙이게 됩니다. 그래서 픽셀 정보, 채널 정보 쭉 이어서 vector 하나로 이미지 프레임 하나를 표현을 하게 됩니다.
그래서 이거를 Sequential 하게 이어 붙여서 2D array로 표현을 합니다. key와 value 매트릭스와 연산을 해서 계산을 하게 되고 key와 value의 Input으로 넣게 되고, 각각 계산이 된 원하는 사이즈의 latent array로 압축을 시키게 되면 latent array 형태 사이즈만큼의 Output이 나오게 됩니다.
latent array를 query 매트릭스에 projection을 시켜서 query 매트릭스랑 계산을 하고 key를 사용해서 Attention 스코어를 계산을 했으면, Attention 스코어의 value를 통과한 매트릭스를 적용을 시켜서 마지막에 latent array를 뽑아내게 되는데 latent array 사이즈와 똑같은 Output 형태가 나오게 됩니다.

그리고 이어지는 부분은 기존의 Transformer encoder랑 똑같이 생긴 형태입니다. 이 부분은 Self Attention 구조의 Transformer encoder랑 똑같다고 보시면 됩니다.
그래서 Input이랑 Output 사이즈가 똑같은 latent array가 Input으로 key, query value에 똑같이 들어가면, 똑같은 형태의 Output이 되고 그러다 보니까 이 depth는 자유자재로 늘려 줄 수가 있게 됩니다.
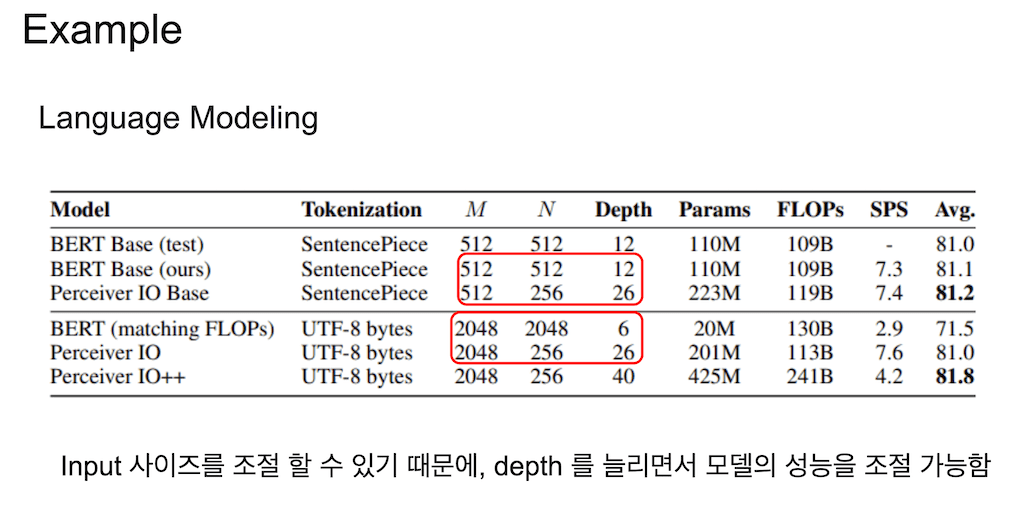
실험 부분에 나오는 표입니다. 기존에 BERT 같은 경우에는 512개의 토큰 개수를 사용을 한다고 하면 latent 안에서 계산되는 Sequence에 array의 개수도 똑같이 512로 계속 매핑이 되고, 그러다 보니까 depth를 키우면 모델 사이즈가 커지기 때문에 함부로 depth를 늘릴 수가 없는 단점이 있습니다.
Perceiver에서는 처음에 512개의 토큰이 들어와도 자유자재로 latent 사이즈를 줄여줄 수가 있게 되고 다시 Output에서 똑같은 사이즈로 키워줄 수가 있기 때문에 안에서 계산을 할 때 depth를 더 늘려가지고 그 모델의 성능을 더 높일 수가 있게 됩니다. 그래서 depth를 늘려주면 계산 능력이 커진다고 하기 때문에 성능도 더 높일 수 있는 장점이 있게 됩니다.
그래서 512개 length라서 와닿지 않는데, BERT의 Max length를 2048개로 한다면 기존의 BERT 모델을 계속 안쪽에 Self Attention이 248개 Sequence를 가지고 올라가야 되기 때문에 depth를 6개밖에 못 주는 한계가 있는데, Perceiver는 length 자체를 확 줄여준 다음에 계산을 할 수가 있기 때문에 depth를 더 크게 늘려줄 수 있는 장점이 있게 됩니다.

Perceiver IO에서 추가되는 부분은 Output query array를 decoding에 넣어주는 Contribution입니다. decoding Attention에서는 원하는 Output 형태를 query의 형태로 만들어서 query 매트릭스에 넣어줍니다. 여기에서 query는 여러 가지가 될 수 있습니다. Output query array 자체가 학습된다고 해서 이것을 계속 학습을 시켜줄 수도 있고, 아니면 사람이 수작업으로 vector를 조정을 해서 넣어 줄 수도 있고 그래서 Output query array의 형태는 하이퍼 파라미터라서 모델러가 알아서 결정을 하게 되고, 마지막에 원하는 세 개의 Output이 나와야 된다라고 하면 Output array 길이를 3개로 주어서 마지막에 원하는 개수의 형태로 매트릭스를 뽑아내게 됩니다.

예를 들어서 Masked language 모델 같은 경우에는 Input이 2048개가 들어가면 Output도 2048개가 나와야 되는데 그러면 각각 하나의 토큰에 해당하는 position vector라고 하면, 2048개를 concatenate 시켜가지고 Output query로 넣어주게 됩니다. 그러면 dimension이 5라고 하면 2048 x 5 Output query 매트릭스가 마지막에 Cross Attention에 query로 들어가게 됩니다.
그리고 classification 같은 경우에는 Input이 하나가 들어가면 거기에 대응되는 Output도 무조건 하나가 되기 때문에 더 concatenate를 시키지 않고 task id 어떤 classification인지 알려주는 또는 임의의 학습되는 vector 하나를 넣어주면 classification 모델로 학습이 될 수 있게 됩니다.
Multi-task classification 같은 경우 이미지 하나가 들어가면 여러 개의 task를 동시에 적용을 할 수 있게 됩니다. 예를 들어서 이미지 하나에서 동물은 강아지고, 풍경은 잔디밭이고, 이런 식으로 하나의 이미지에서 여러 개의 task를 classification 하는 경우에는 여덟 개의 task를 동시에 수행을 하고 싶다면 각각의 task id, 첫 번째 vector에서는 강아지가 나와야 되고, 두 번째 vector에서는 풍경에 대한 것이 나와야 되고 각각 태스크에 해당하는 8개를 concatenate를 시키는 경우에 8 x 4 가 되면, 8 x 4 형태의 query가 들어가게 되면 Output도 똑같이 여덟 개의 형태의 classification 결과가 나오도록 진행이 됩니다.
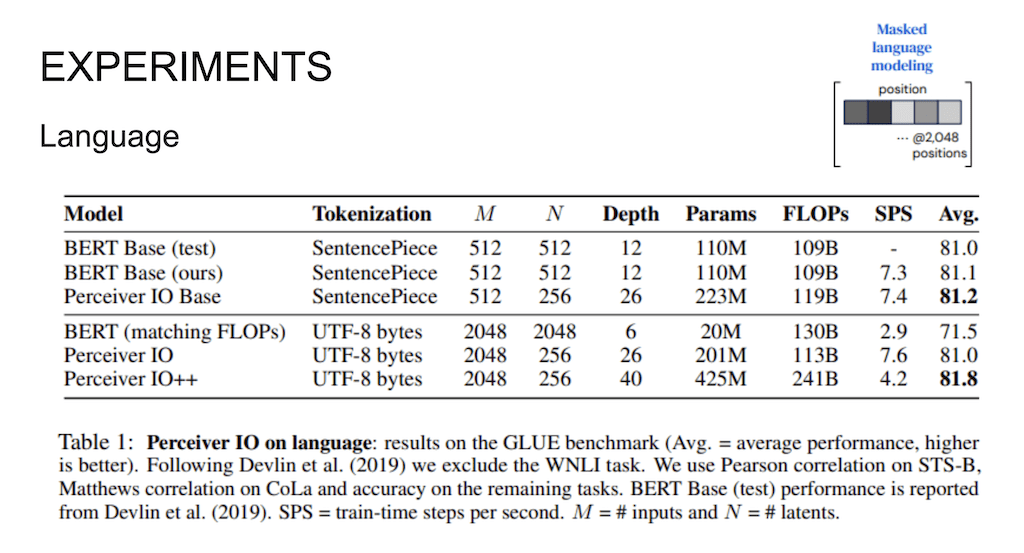
Language 모델링에 Perceiver IO를 적용한 부분입니다. tokenization에 따라서 실험이 나뉘는데, 기존에 SentencePiece 모델로 보통 문장을 tokenizing을 시키고 그다음에 모델을 학습을 시키는 게 자연어 처리 쪽에서는 일반적이었습니다.
이 모델 자체가 tokenizing의 제약을 받지 않고 되게 sequential 하게 받는 모델이다 보니까 여기에서는 SentencePiece를 사용을 안 한 버전도 실험 결과로 보여줍니다.
여기에서 지적을 하는 부분은 SentencePiece를 적용을 하는 거는 영어 task에서만 유용하게 적용이 되고, 중국이나 캐릭터 형태의 언어 쪽에서는 SentencePiece 모델로 tokenizing을 하는 게 그다지 효과적이지 않다고 얘기를 해서 여기서는 그 문자 하나하나를 UTF-8 bytes로 매핑을 시키고 학습을 시킨 걸 같이 비교를 해서 보여주고 있습니다.
Perceiver IO는 Sequence 자체를 엄청 줄인 다음에 계산을 수행을 할 수 있기 때문에 기존의 BERT는 12 개의 depth를 가지고 있는데 Input 길이 자체를 줄여서 depth 자체를 늘려가지고 계산능력을 늘려주는 부분이 있습니다.
그리고 UTF-8 bytes로 encoding을 한 경우에도 역시 2048개의 Sequence를 가지고 BERT를 구성을 하면 depth를 매우 짧게 줄 수밖에 없는 한계가 있는데 여기에서도 Input 길이를 조절할 수 있기 때문에 depth를 엄청 크게 줘서 성능을 높인 걸 볼 수 있고, depth를 더 크게 늘렸을 때 역시 그 성능이 더 좋았다고 얘기를 하고 있습니다.

Language에서 Multi-task learning을 진행을 했는데 먼저 여러 가지 형태로 Multi-task learning을 같이 비교해서 수행을 했습니다.
BERT 같은 경우에는 Pre training 시킬 때 CLS 토큰에 classification 결과를 뽑을 수 있도록 Pre training을 시키는데, 이 Pre training을 시킬 때는 next sentence classification 형태로 Pre training을 시키게 됩니다.
그래서 첫 번째 문장이랑 두 번째 문장이 이어지는 문장인지를 CLS 토큰에서 나온 Output을 가지고 classification을 진행을 하게 되는데, CLS 토큰을 파인 튜닝할 때도 모두 똑같은 토큰에 대해서 활용을 하는데 그것도 Input이 share 토큰을 사용한다. 그래서 task specific 하게 CLS 토큰을 따로 두어야 된다라고 얘기를 하고 있어서 기존의 방법대로 BERT를 Pre training 할 때 썼던 CLS 토큰을 사용해서 Fine tuning 할 때, 전체 여러 가지 task를 진행을 했을 때 average 한 성능이 81.5 accuracy가 나왔다고 얘기를 하고 있습니다.
그리고 CLS 토큰은 shared 하게 사용하지 않고 Multi-task를 각각 task마다 CLS 토큰을 새로 만들어서 task specific 하게 진행을 했을 때 성능이 좀 더 올라갔습니다.
task specific 같은 경우에 모델을 따로따로 학습을 시켜야 되는데 Multi-task query 같은 경우에는 한 번에 학습이 되도록 해가지고 Input을 바꾸지 않고 Output query만 조절을 해서 뽑았을 때 거의 똑같은 성능이 나왔다고 합니다.

비전 분야에 적용을 한 Experiments입니다.
여기에서 실험한 방법 자체는 Optical flow를 구할 때 연속되는 두 개의 프레임을 concatenating을 시켰다고 합니다. 그때 하나의 픽셀에 대한 값은 주변에 3 by 3 패치로 추출을 하고, Input feature에다가 픽셀의 Positional encoding을 추가를 합니다.
하나의 Input을 구성하는 게 하나의 픽셀이라고 보시면 되고 이 픽셀이 한번 Input으로 들어갈 때, 11408개 픽셀을 concatenate를 시켜서 매트릭스 형태로 Input을 넣어줬습니다. Input feature는 positional encoding 없이 Input feature들을 concatenate 시켜서 넣게 되고, vector는 Output 매트릭스에서 query의 매트릭스로 들어가게 되는 부분입니다.
그래서 Input은 패치 54개를 11408개를 이어 붙여서 Input으로 넣어주고 마지막에 Output decoding을 할 때 뒤에 다가 Positional encoding을 추가를 한 다음에 Output의 query 매트릭스로 넣어주게 되고 거기에 각각 해당하는 Output이 있게 되었다고 설명합니다.
Optical flow 대한 성능입니다.
Sintel는 Perceiver IO가 성능이 가장 좋다고 하고 final에 대해서는 SOTA를 달성을 했습니다. KITTI라는 데이터에 대해서는 기존에 비해서 좋은 성능을 보이지 못했습니다.

Auto encoder로 Perceiver IO를 적용을 한 부분입니다. 비디오 자체를 encoding을 시킨 다음에 encoding 시킨 걸 다시 복원을 하는 작업입니다. 이때 오디오도 복원을 해야 되고, 비디오도 복원을 해야 되고 동시에 이 비디오가 어떤 비디오 인지 classification까지 하는 모델로 학습을 시켰습니다. 이때 Input은 비디오 Sequence를 concatenate를 시켜서 이어 붙이고, 그다음에 오디오를 이어붙이고 그 다음에 마지막에 하나, 비디오가 어떤 비디오인지 레이블 하나를 concatenate 시켜서 Input으로 이어붙여서 Input으로 넣어주게 됩니다.
그래서 각각에 해당하는 것들을 복원을 해줘야 되니까 Input이랑 Output의 사이즈가 똑같게 될 텐데 그때 Output query 매트릭스에 똑같이 비디오 Input이랑 오디오 Input이랑 옆에다가 그 비디오 각각 프레임의 position encoding, 그리고 얘가 비디오인지 아닌지 확인할 수 있는 부분도 하나 추가를 하고 그 다음에 이어서 오디오를 이어 붙이고, 그 오디오에 positional encoding을 이어붙이고 마지막에 레이블 query에 해당하는 걸 하나 붙여 똑같은 형태의 Output이 나오도록 Auto encoder를 구성을 하게 됩니다.
성능을 보시면 PSNR이라는 게 최대 신호 대 잡음비입니다. 복원된 것의 잡음이 얼마나 섞여있는지를 수치로 나타내는데 높을수록 좋은 성능입니다. 그래서 이 표가 잡음을 최대한 없앨 때 accuracy는 떨어지는 형태를 볼 수 있었다고 합니다.
accuracy는 마지막에 이 영상이 어떤 영상인지에 대한 classification에 대한 accuracy입니다. 그리고 compression ratio는 처음에 Input으로 들어갈 때 Input Sequence를 확 줄여준 다음에 계산을 하는 부분을 말하고 있습니다. 88배 줄이고, 176배 줄이고, 352배 줄이는데 줄일 때마다 잡음이 많아지는 것을 볼 수 있는데, 그 대신에 classification accuracy는 오히려 compression 비율이 높을수록 올라가는 것을 볼 수 있습니다.

여러 가지 실험을 진행을 했는데 ImageNet이랑 스타크래프트 2, 오디오 등 다양한 데이터셋에 대해서 다 좋은 성능을 보였다고 하고 있습니다.




댓글