안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘MERL:Multimodal Event Representation Learning in Heterogeneous Embedding Spaces’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘MERL' 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/shnfzksjm1M)

먼저 Event Representation Learning에 대해서 간략하게 설명해 드리고 넘어가겠습니다. Event Representation는 어떤 하나의 사건을 Embedding 공간 안에 표현하는 방법입니다. 예를 들어서 오른쪽 예시를 보시면 Person X threw basketball, Person Y threw bomb, Person Z attacked embassy 세 개 event가 있을 때 Person Y threw bomb과 Person Z attacked embassy는 비슷한 event를 다루고 있는 느낌이고, 그리고 첫 번째에 threw basketball은 위의 두 개 사건과는 다른 종류의 event입니다. 즉, 서로 비슷한 event는 가까운 거리에 Embedding 시키고 그렇지 않은 event에 대해서는 멀리 Embedding을 시키는 딥러닝 기법입니다.
Event Representation Learning이 하나의 sentence를 주어, 동사, 목적어 이렇게 세 개의 triple로 표현하고 학습시켰을 때 굉장히 극적인 발전이 있었다고 합니다. 그래서 주어, 동사, 목적어를 영어로 subject, predicate, object라고 칭하겠습니다.

논문의 Motivation에 대해서 설명을 드리겠습니다. 3개 event의 triple을 표현을 해 놓았습니다.
1번은 (she, attend, baby) 그녀가 아이를 돌보고 있다.
2 번은 (he, take care, kid) 그가 아이를 돌보고 있다.
3 번은 (she, attend, meeting) 그녀가 회의에 참석했다.
3가지 다른 event에 triple입니다. 여기에서 1번과 3번 triple을 보시면 (she, attend) 까지는 같은 단어가 쓰였습니다. 그런데 이 attend라는 단어가 의미하는 게 다르게 됩니다. 첫 번째는 돌보다 라는 의미의 attend고, 세 번째는 참석하다 라는 의미의 attend입니다.
그래서 이렇게 같은 주어와 동사가 있어도 전혀 다른 의미를 포함하고 있는 경우에 Embedding 할 때 굉장히 어려움이 있었고 반대 케이스로는 첫 번째와 두 번째 triple은 같은 의미를 내포하고 있음에도 불구하고 전혀 다른 주어와 동사가 쓰였습니다. 이 경우 역시 Embedding 공간 안에 매핑을 할 때 조금 문제가 있습니다.

Multimodal을 사용을 하는 방식입니다. Multimodal은 triple + event에 관련된 이미지를 같이 Embedding을 하면서 Embedding의 정확도를 높여주는 학습법이 제안이 돼 왔습니다. 위에서 보여드린 세 개의 triple에 대해서 각각 그 사건을 나타내는 이미지를 같이 학습에 사용하게 함으로써 모델의 성능을 높이는 접근법이 발달을 해왔습니다.

논문에서 지적하는 기존 Multimodal 방법의 문제점은 학습을 시킬 때 Embedding을 할 당시에 이미지와 Texture 이미지를 같은 공간 안에 매핑을 시키는 게 부적절하다 라는 그 의의를 제기합니다. 그 이유는 텍스트에 비해서 같은 사건을 다루고 있는 무한개에 가까운 이미지를 매핑을 시킬 수 있다는 게 논문에서 말하는 그 기존 방법의 단점입니다. 예를 들어서 (he, play, soccer)라는 triple에 대해서 거의 무한개의 이미지를 매핑을 시킬 수가 있습니다. 근데 자세도 다르고, 배경도 조금씩 달라집니다. 같은 텍스트에 대해서 상대적으로 매핑될 수 있는 같은 사건을 다루는 사진 이미지가 너무 많다고 설명합니다.

그래서 event triple과 event 이미지는 다른 공간에 매핑이 돼야 되고 text 자체는 하나의 포인트가 아니라 이미지 전체를 다룰 수 있는 하나의 distribution 형태로 나타내야 된다. 즉, point Embedding이 아니라 triple은 density Embedding으로 가야 되고 이미지는 point Embedding으로 가야 된다. 그리고 이 공간은 서로 다른 공간에 매핑이 돼야 된다는 게 논문의 Motivation입니다.
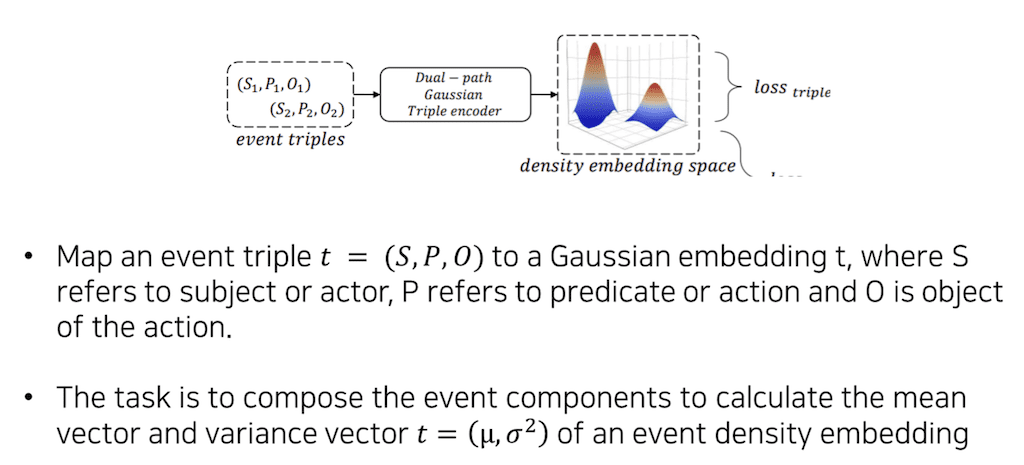
논문의 방법론입니다. 먼저 event triple을 어떻게 Embedding을 하느냐에 대해 설명을 드리도록 하겠습니다. event triple을 매핑하고자 하는 하나의 목적은 input으로 event triple이 주어, 동사, 목적어 세 개의 triple이 들어왔을 때 하나의 Gaussian distribution으로 표현합니다. Gaussian distribution으로 표현하기 위해서는 distribution의 평균과 표준편차를 알아야 합니다. 그래서 input이 triple로 들어오고, input에 대한 output은 하나의 distribution에 대한 평균과 표준편차를 구하는 모델을 학습을 시키게 됩니다.

Encoder 모양은 Dual-path Gaussian Triple Encoder입니다. 먼저 평균의 예측을 하는 모델과 표준편차를 예측을 하는 모델이 병렬적으로 따로 존재하는데, 각각을 예측하는 Encoder가 2개의 Path로 이루어져 있습니다. 먼저 평균을 구하는 mean Encoder 쪽을 보시면, 이 논문에서 가정을 한 거는 평균은 Gaussian Embedding 공간 안에서 위치를 나타내 주는 게 mean Vector입니다. 그래서 mean Vector는 subject와 predicate의 관계 그리고 predicate와 object의 관계. 두 관계에 따라서 Embedding 공간 안에 위치가 바뀐다라고 가정을 합니다.
그래서 이런 관계를 Embedding 할 수 있도록 주어와 동사의 관계를 나타내고 있는 tensor 하나를 학습시키게 됩니다. Tensor는 주어의 Vector를 d차원이라고 했을 때 d x d 매트릭스가 총 k개 있다고 생각하시면 됩니다. 그래서 관계를 K개의 차원으로 표현을 하는 tensor가 됩니다. 주어랑 동사의 관계를 Embedding 해서 계산하고, 동사와 목적어의 관계를 Embedding 해서 계산하고 이렇게 계산한 두 관계를 다시 한번 계산해서 총 mean Vector를 뽑아내는 과정입니다.

이 논문에서는 표준편차는 주어와 목적어는 크게 중요하지 않고 동사가 어떤 것이 쓰였냐에 따라 Gaussian distribution의 범위가 결정된다고 가정합니다. 여기에서 predicate에 따라서 이러한 variance가 결정이 되기 때문에 굳이 관계를 Embedding 할 필요 없이 동사와 주어를 concatnate 해서 한번 NLP layer에 넣어 주고, 동사와 목적어를 concat 해서 NLP layer에 넣어 주고 그 두 개를 다시 concat 해서 분산을 구하도록 모델을 설정을 합니다. 여기까지가 triple Encoder이었습니다.

Visual event를 Embedding 하기 위한 방법입니다. Text는 하나의 distribution과 매핑시키고 이미지는 하나의 포인트와 매핑시켜서 이미지의 distribution이 하나의 triple의 distribution과 같은 사건에 다루는 경우에 2개가 비슷한 분포를 띄도록 학습을 시킵니다.
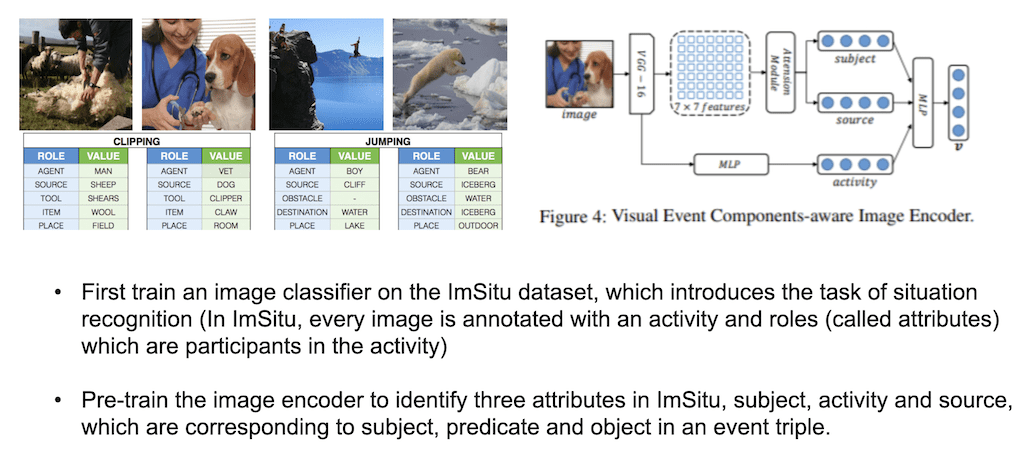
먼저 이미지를 Embedding을 시키고 주어, 목적어, 동사 이 세 개를 뽑아내기 위해서 Pre-training을 시켜주는 과정을 거칩니다. Pre-training에 사용한 데이터셋은 ImSitu 데이터셋을 사용을 해서 Pre-training 시켜줍니다. ImSitu는 사진이 하나 있고, 사진에서 다양한 역할들에 대한 value를 가지고 있습니다. 예를 들어서 첫 번째 사진을 보시면 한 남자가 양의 털을 깎고 있는데 activity 자체는 ‘깎는다’ 동사가 되고, Agent는 man이 되겠고 목적어(source)는 sheep이 되겠고 여러 가지 ROLE에 대한 value를 가지고 있는 데이터셋입니다.
필요한 거는 주체와 객체 그리고 동사 이렇게 세 가지니까 ROLE에 AGENT, SOURCE, 그리고 CLIPPING 세 가지를 뽑아와서 하나의 이미지에서 세 개를 classification 하도록 모델을 짜서 Pre-training 시킵니다.
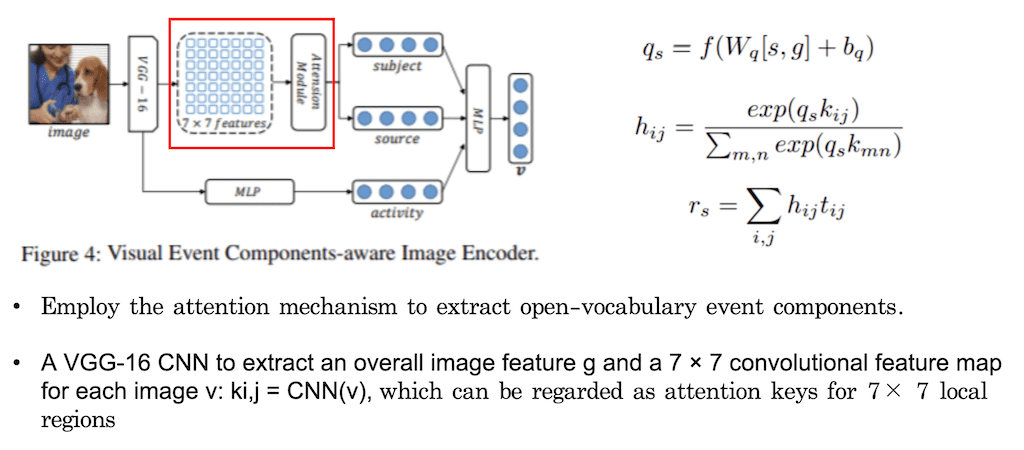
주체가 있고 객체가 있으려면 이미지의 어떤 object들이 존재해야 되기 때문에 주체의 주어와 목적어에 해당하는 것을 추출을 할 때는 이미지의 global Vector를 먼저 한번 추출을 하고 CNN을 통해서 local feature들을 다 뽑은 다음에 attention module을 적용한 다음에 뽑아냅니다. 처음에 이미지를 VGGnet을 사용해서 글로벌 Vector를 하나 뽑아내고 7 x 7 Convolutional feature map을 사용을 해서 local feature들을 뽑아냅니다. 뽑아낸 local feature에 대해서 subject 따로 source 따로 해서 attention module을 적용해서 subject를 찾으려면 이미지에 있는 수의사한테 attention을 줘야 합니다. 그래서 이 attention을 계산을 해서 subject를 뽑아내고 강아지를 뽑아내기 위해서 또 다른 attention moule을 적용해서 source를 뽑아내고 subject와 source를 Embedding을 시켜 줍니다.

그리고 subject와 source와는 다르게 이미지에서 행위하는 activity 즉, 동사에 해당하는 단어는 이미지 전체를 보고 이미지 흐름을 이해해야 알 수 있는 부분이기 때문에 global image Vector 자체를 MLP에 넣어서 activity Vector를 뽑아줍니다. 이렇게 총 세 개를 뽑고 각각을 classification 해주는 Pre-training 단계를 거치게 됩니다. 여기서 subject는 수의사이고, source는 강아지, activity는 CLIPPING. classification 과정을 통해서 모델을 학습시킵니다.
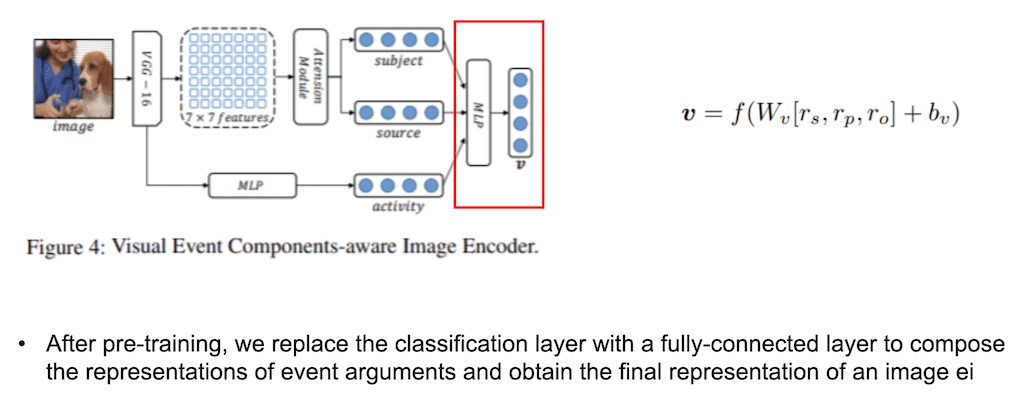
MLP의 layer는 Pre-training 모델로 뽑아낸 subject, source, activity Embedding을 Concatnate 한 후에 MLP layer를 적용시켜서 point Vector 하나로 표현합니다.

Training 과정입니다. 첫 번째는 triple을 encoding 하는 loss를 적용해주고, 이미지를 Embedding 하는 loss를 적용을 해 주고, 그리고 최종적으로 이 두 개의 다른 공간을 매핑하는 loss. 총 3가지 loss가 적용이 됩니다. triple에 대한 loss로는 max-margin loss를 사용합니다. 비슷한 event인 것과 similarity를 계산했을 때 높아야 되는걸 positive sample이라고 하고, 전혀 다른 event의 Embedding Vector와 similarity를 계산을 했을 때 similarity는 작으니까 비슷한 event끼리 similarity는 높고, 다른 event끼리 similarity는 낮게 max-margin loss를 줘서 학습시키는데 이때 triple은 event 하나를 distribution에 매핑하기 때문에 앞서 구한 Gaussian distribution의 평균과 표준편차를 이용해서 두 개 distribution 간의 유사도를 구해주게 됩니다. loss를 낮추는 방식으로 학습이 진행이 되게 됩니다.

두 번째입니다. 마찬가지로 max-margin loss를 적용을 하는데 point Vector이기 때문에 Euclidean distance 즉, 두 개 이미지, 비슷한 이미지 positive sample과 target 간의 이미지, negative와 target 간의 distance를 이용해서 로스를 계산을 합니다.
마지막 세 번째 loss는 triple의 Gaussian distribution과 그리고 triple에 해당하는 여러 개 이미지가 있을 텐데 이미지가 띄고 있는 distribution의 kl divergence loss를 구해서, 두 개 distribution이 유사하도록 학습을 시켜줍니다. 그래서 총 3개의 loss가 적용이 됐습니다.

Pseudo code입니다. 처음에 triple loss를 구하고 다음에 이미지에 대한 loss를 구해 주고 이 두 개의 distribution이 유사하도록 kl divergence를 주는 세 번째 loss를 업데이트해서 학습을 시켜줍니다.

데이터셋입니다. 학습을 시킬 때는 주로 많이 사용되는 데이터셋을 가져와서 천 개의 event triple이 있는 데이터셋이 있는데 positive sample 같은 경우에는 같은 사건을 전혀 다른 단어로 사용해서 표현한 경우. police catch robber와 authorities apprehend suspect가 같은 사건인데 용의자를 체포한 사건은 positive sample로 묶여 있습니다.
그리고 같은 문장에서 주체와 동사는 같은데 전혀 다른 event인 경우를 negative sample로 가지고 있는 데이터셋을 가져와서 확장시켜 줍니다. 이 query를 google 이미지 검색에다가 넣어서 결과로 나오는 20개 이미지를 가지고 annotator가 직접 걸러서 하나의 triple에 대해서 10개 이미지를 매핑시켜 주도록 이미지를 찾아 줍니다.
여기에서는 문장도 확장을 더해줍니다. 원래는 1000개의 event triple을 가지고 있는데 3,000개 event triple로 문장을 확장을 시켜주고 각각의 event triple에 대해서 10개 이미지가 매핑이 되기 때문에 총 30,000개 event 이미지를 가진 데이터셋을 사용해서 학습을 시켜 주게 됩니다.

실험에 대해서 설명을 드리도록 하겠습니다. 총 세 가지 task 실험을 진행을 했는데요. 먼저 학습은 3,000개 event triple과 30,000개 이미지 셋을 가지고 학습을 시켰습니다. 여기에 새로운 데이터셋을 사용해서 추가로 테스트만 진행을 했습니다.
그래서 첫 번째 Multimodal event similarity는 같은 event를 다루고 있는 다른 이미지를 가지고 같은 event 인지를 찾는 task입니다. 두 번째는 이미지와 그리고 sentence에 대해서 비슷한 event인지 아닌지를 scoring 하는 task입니다.
두 가지 데이터셋을 사용을 해서 테스트를 합니다. 첫 번째 데이터셋은 원래는 230개 event를 가지고 있는 triple이었는데 구글의 이미지를 얻어오는 방법을 사용을 해서 확장시켜서 690개 event triple과 거기에 각각의 10개에 해당하는 이미지를 매핑시켜서 6900개 이미지로 이루어진 데이터셋을 사용했습니다.
두 번째 데이터셋은 이미지가 아니라 text만 이루어지고 108개의 triple로 이루어진 데이터셋입니다.
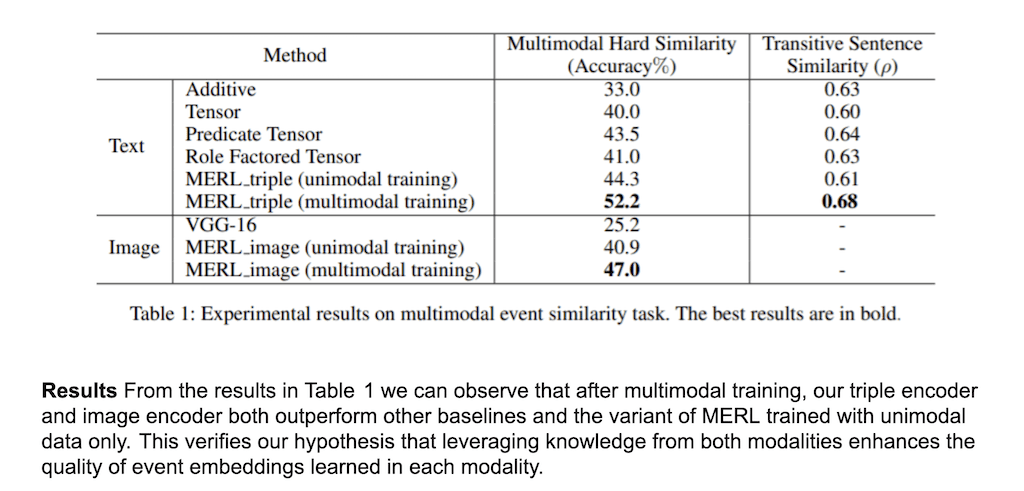
실험을 진행을 했을 때 여기서 제안한 MERL 모델이 가장 좋은 성능을 보이는 거를 확인을 할 수가 있습니다. 그리고 이미지와 text로만 해 봤을 때도 Multimodal로 했을 때가 성능이 훨씬 좋아지는 걸 확인을 할 수가 있습니다. 특히 이미지 같은 경우에도 정확도가 7% 나 오른 것을 확인을 할 수가 있고, text도 8% 정도 오르는 걸 확인을 할 수 있습니다.

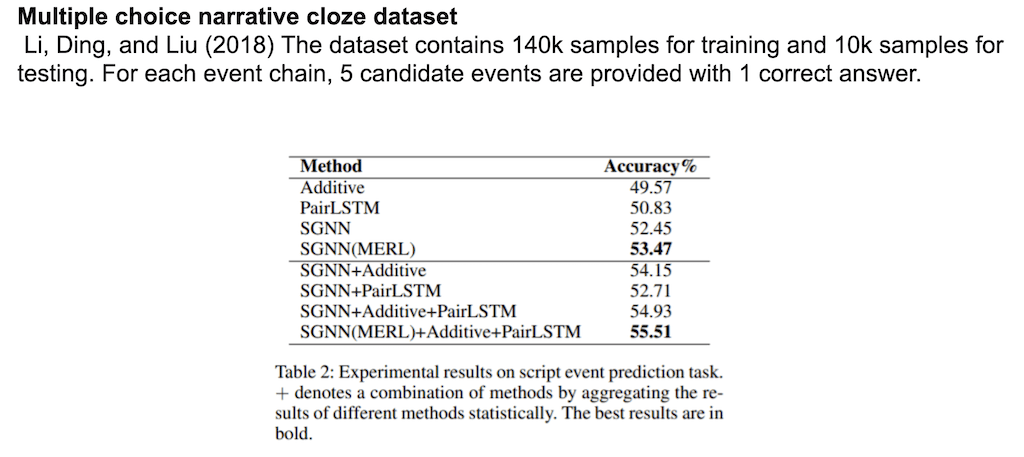
두 번째 task는 Script evenct prediction입니다. Script evenct prediction는 하나의 대본에서 다음 장면이 뭔지를 예측하는 task입니다. 예를 들어서 레스토랑에 가서 앉아서 직원을 호출하고 먹고 그리고 마지막에 돈을 지불 한 다음에 레스토랑을 나갑니다. 그리고 이어질 event가 무엇이냐를 예측하는 task입니다. Script evenct prediction는 기존에 task에 최적화된 classification 모델을 사용해서 Embedding만 MERL로 대체해서 Embedding이 얼마나 성능을 높일 수 있는지를 체크한 실험입니다.
SGNN(Scaled Graph Neural Network) 모델을 사용을 해서 Embedding만 논문에서 제안한 embedding으로 교체를 한 다음에 성능 테스트를 했는데 MERL을 사용한 게 정확도가 높은 걸 확인할 수 있습니다.

마지막 실험입니다. 이 실험은 event, triple이 주어지면 가장 유사한 이미지를 찾아 주는 task입니다. 일종의 구글 이미지 검색 이랑 비슷하다고 보시면 됩니다. 여기서는 recall@10 결과를 사용을 해서 스코어를 측정했습니다. 그리고 비교한 대상들은 텍스트와 이미지의 선후관계를 사용을 해서 Embedding을 시키는 모델들이라고 설명합니다. 그래서 하나는 triple을 넣고 비슷한 triple을 retrieval 하는 것, 그리고 triple을 넣고 비슷한 이미지를 retrieval 하는 것. 이 두 가지 task를 봤을 때 이미지 retrieval에서 압도적인 성능을 보인 걸 확인할 수가 있지만 triple retrieval에서는 다소 떨어지는 성능을 보였습니다.




댓글