오늘 소개해 드릴 논문은 ‘Training Data-Efficient Image Transformer & Distillation through Attention’입니다.
콥스랩(COBS LAB)에서는 주요 논문 및 최신 논문을 지속적으로 소개해드리고 있습니다.
해당 내용은 유튜브 ‘딥러닝 논문읽기 모임' 중 ‘Training Data-Efficient Image Transformer & Distillation through Attention’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크: https://youtu.be/LYYxv9mv5qw)
이 논문은 흔히 DeiT라고 불리며 발표된 지 얼마 되지 않은 논문임에도 불구하고 큰 인기를 끌고 있는 논문입니다. 순서는 간단한 요약, 사전 지식, Method, Experiment, 그리고 끝으로 Discussion 순으로 진행하겠습니다. 이해를 돕기 위해서 실제 논문 순서와 다르게 내용이 배치되어 있습니다.
먼저 Summary Part입니다. 이 논문은 2020년 12월에 Facebook AI에서 발표된 논문으로, 논문 발표 이후 인터넷 신문 기사도 뜰 정도로 큰 인기를 끌었습니다. 이 논문은 기존에 google에서 발표된 논문인 Vision Transformer 또는 ViT라고 불리는 모델을 기반으로 실험을 실시하였으며, ViT를 일부 발전시키고 Knowledge Distillation 개념을 도입하는 연구를 진행하였습니다. 이 논문의 Contribution은 CNN을 사용하지 않은 Image Classification Task를 수행하는 모델이라는 점입니다. 사실 이 Contribution은 본 논문의 Contribution이 아닌 ViT의 Contribution이라는 점 짚고 넘어가시면 좋을 것 같습니다. 또한 ImageNet으로만 학습을 진행하였고, Single 8-GPU Node로 2~3일 정도만 학습을 하였습니다. 이것이 왜 Contribution이 되는지는, 추후 ViT에 대해 설명드리는 과정에서 이해할 수 있습니다. 다음으로는 SOTA를 달성한 CNN기반의 Model과 유사한 성능을 확인했고, 마지막으로 ViT에 Knowledge Distillation 개념을 간단한 방식으로 도입함으로써 성능을 향상시켰습니다. 이 논문의 결론으로는 CNN 계열의 Architecture들은 다년간 연구가 진행되어 현재의 높은 수준의 성능을 보여주고 있지만, Transformer가 이미지 분야에서 연구되기 시작한 지 불과 1~2년밖에 되지 않았음에도 불구하고 CNN과 유사한 성능을 보여주었기 때문에 Transformer가 기대가 된다는 것입니다.

위 그래프에서 확인하실 수 있듯이, 노란색의 CNN 계열의 EfficientNet보다 본 논문 방식인 DeiT가 성능이 더 높은 것을 확인할 수 있습니다. 이 표시는 Distillation을 사용한 것이고, Ours는 Distillation을 사용하지 않은 DeiT입니다. Distillation을 사용하지 않은 Model도 기존 ViT보다 더 성능이 향상된 것을 볼 수 있습니다. 하지만 실제로 DeiT는 ViT와 완전하게 동일한 구조를 가지고 있습니다. 이 부분에 대해서는 추후 설명드리도록 하겠습니다.
다음은 Prerequistes입니다.
여기서는 ViT와 Knowledge Distillation 개념을 간단하게 설명드리겠습니다.
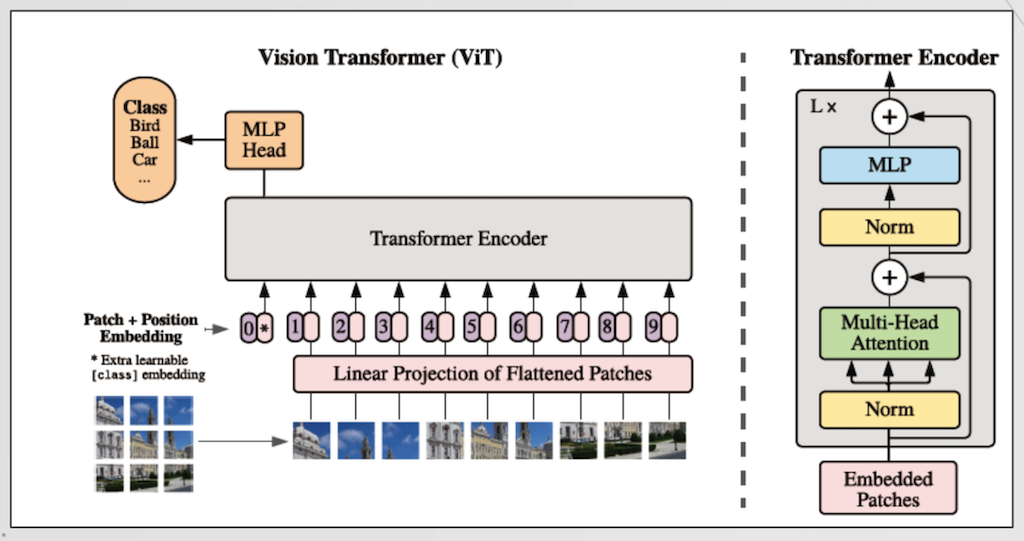
먼저 ViT입니다. ViT는 An Image is Worth 16x16 words : Transformers for Image Recognition at Scale라는 구글에서 발표된 논문으로서, CNN을 사용하지 않고 Transformer만 사용하여 Image Classification을 수행하였습니다. 원래 Transformer는 Encoder-Decoder 구조로 이루어져 있는데, Decoder는 보통 특정 Task를 수행하는데 이용됩니다. 일반적인 CNN Base를 생각해보면 Trunk와 Head가 각각 Encoder와 Decoder와 매칭이 된다고 생각할 수 있습니다. 보통 Image Classification은 Feature Extraction을 수행하는 Trunk가 CNN구조로 이루어져 있고, 실제 Classifier인 Head는 간단한 몇 개의 Linear Layer로 이루어져 있습니다. 따라서, ViT에서는 굳이 Transformer에서 Decoder의 복잡한 구조를 사용하는 것이 아닌 MLP Head라고 불리는 몇 개의 Linear Layer를 사용함으로써 Classifier를 구성하였습니다. Transformer의 Input값으로는 먼저 Image를 일정 크기의 패치로 잘라 해당 Patch를 Linear Projection 하여 Input Value로 만듭니다. 단순하게 생각하시면 2차원 이미지를, 1차원 Image로 변환하는 과정이라고 생각하시면 되고, 그 후 Position Embedding값을 더해주어 Transformer의 Input값으로 활용합니다. Position Embedding은 Mutli Head Attention에 위치 정보를 포함시켜 입력할 수 있도록 사용하는 위치 정보를 담은 Vector라고 생각하시면 되고 일반적으로 Cos과 Sin의 조합으로 이루어지지만, ViT에서는 학습 가능한 Embedding 값을 Position Embedding 값으로 사용하였습니다. 이렇게 만든 Input값에 추가적으로 Class Token을 더해주어 최종 Input값을 생성합니다. 이 Class Token은 Image Token처럼 Image정보를 가지고 있는 Embedding이 아니라, 단순히 Class를 분류하기 위한 Token으로 활용되는 부분입니다. 단순하게 생각해서, 빈 Patch를 하나 만들어 입력하게 되고, Encoder를 통해 해당 빈 Patch의 값 채워 넣은 다음 MLP Head에 입력하여 Classification을 수행하는 방법이라고 생각하실 수 있습니다.

ViT는 Pre train에 JFT-300M 데이터셋을 활용합니다. 이 데이터셋은 일반인들에게 공개되지 않은 Google의 Dataset으로 3억 개의 이미지로 구성되어 있는 매우 큰 데이터셋입니다. 이때, Pretrain은 작은 Resolution으로, Fine Tuning은 큰 Resolution으로 진행함으로써 성능을 올렸다고 합니다. 이때, Input Image의 크기가 달라질 때, 보통의 CNN은 Input 이미지 크기가 고정되어 있으므로 불가능한 방법이지만, Transformer는 Input 이미지의 크기에 구애받지 않아 가능한 방법입니다. Input은 특정 크기의 Patch가 Input이 되고, Image Resolution이 달라질 경우, Input의 개수만 바뀌면 되므로 이러한 방법이 가능하고, 모델의 다른 부분의 수정이 필요 없습니다. 다만, Position Embedding의 경우에는 Position값이 달라지기 때문에 Bicubic Interpolation을 사용하여 간단하게 보간하는 방식을 사용하게 됩니다. 표는 ViT의 성능에 대해서 나타낸 표인데, 여기서 주목하실 점은 학습에 걸린 시간입니다. TPUv3 Single Core로 학습하였을 때 2500일, 680일 등 엄청나게 긴 시간이 Training에 필요합니다.
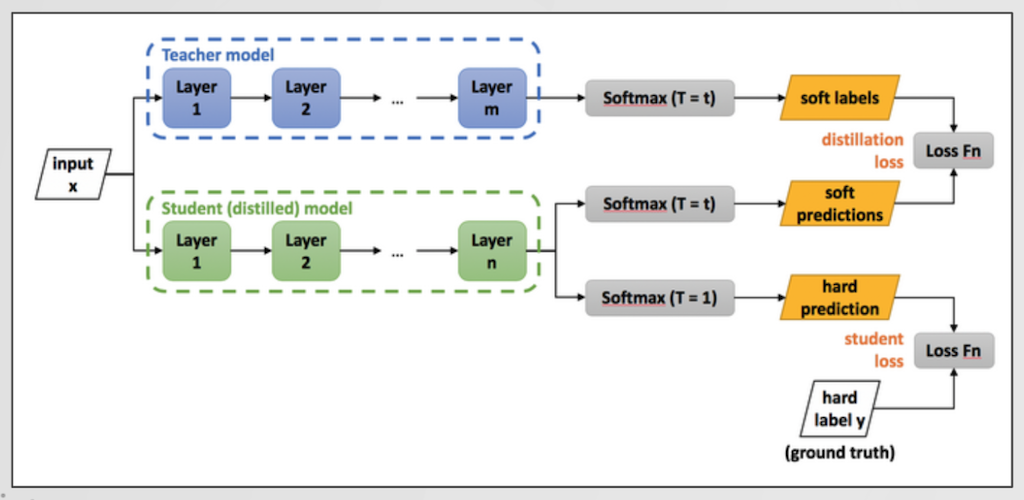
다음은 Knowledge Distillation 개념입니다. Knowldege Distillation은 일반적으로 잘 학습된 Teacher Model의 성능을, 작은 아키텍처를 갖는 Student Model로 지식을 전달한다는 개념으로 사용되고 있습니다. 예를 들어 Resnet108로 학습된 모델을 임베디드 시스템에 사용할 수 없기 때문에, 이를 위해 resnet8이라는 매우 작은 모델을 Knowledege Distillation을 사용하여 최소한의 성능 손실로 지식을 전달하는 것입니다. 보통 Teacher Model과 Student Model은 Soft Label을 사용한 Loss를 계산하고, GT와는 Hard Label을 사용한 Loss Function을 사용합니다.
다음은 Architecture 부분입니다. DeiT는 ViT구조에서 Class Token과 완전히 같은 형태의 Distillation Token을 추가함으로써 Knowledge Distillation을 구현하였습니다. Class Token은 Classification을 위한 Token이고, Distillation Token은 Teacher Model과 비교하기 위한 Token입니다. 따라서 이 전에 보셨던 Distillation 개념에서, Distillation Token은 Teacher Model과 Loss를 계산하는 부분, Class Token은 GT와 비교하여 Loss를 계산하는 형태라고 생각하시면 됩니다.

이때, 논문의 저자는 Soft Distillation과 hard Distillation을 위와 같이 정의하였습니다. Hard Distillation은 One-Hot Encoding같이 Class인 것은 1, Class가 아닌 것은 0으로 계산하여 Loss를 계산하게 되고, 일반적으로 Classification에서 Metric으로 사용하는 것 중에 하나인 Top-1 Acc만 가지고 Loss를 계산한다고 생각하시면 됩니다. 여기서 위 기호는 Softmax 기호이고, Hard Distillation의 수식을 보시면 Teacher Model과의 loss, GT와의 Loss를 같은 가중치로 ½로 최종 loss를 계산하는 것을 알 수 있습니다.

반면 Soft Distillation은 람다의 가중치를 두어 Teacher Model과 GT 간의 가중치를 다르게 두게 됩니다. 또한 수식상에 있는 T(타우)는 Soft Distillation에서 사용되는 Distillation Temperature라는 Hyper Parameter입니다. Soft Distillation은 하나의 Prediction을 사용하는 것이 아니라 여러 개의 Prediction에 대한 정보를 전달하는 개념입니다. 예를 들어 개라고 판단될 확률이 0.9라면, 개와 고양이의 공통된 특징 때문에 고양이일 확률 또한 0.4로 0이 아닌 확률 값을 얻을 수 있게 됩니다. Soft Distillation을 사용하면 개라는 정보만 얻는 것이 아니라 고양이일 확률 또한 계승된다고 생각하실 수 있습니다. 수식에서 보시다시피 Hard Distillation은 Hyper Parameter가 없다는 장점이 있고, Soft Distillation은 Hyper parameter를 설정해야 하지만 전에 설명드린, 다른 Class의 확률 또한 계승할 수 있다는 장점이 있습니다.

Distillation을 활용한 학습에는 Random Crop으로 인한 잘못된 학습을 최소화할 수 있다는 장점이 있습니다. Random Crop이 객체가 존재하는 Box로 잘 Crop 되었다면 GT와 Prediction 모두 Cat으로 잘 학습될 수 있습니다. 하지만 객체가 존재하지 않는 곳으로 Random Crop 된다면 GT는 Cat인데 Prediction은 다른 것이 나타나므로 학습이 잘못될 수 있습니다. 하지만 Teacher Model도 잘못 Crop 된 부분으로 Prediction 할 것이므로 GT와는 다른 Prediction 결과가 나타날 것이고, 이는 GT가 Crop으로 인해 틀릴 수 있는 부분을 완화해주는 효과를 얻을 수 있습니다.

본 논문에서는 ViT와 완전히 동일한 구조를 사용하였지만, Tunning을 통해 성능 향상을 이끌어내었습니다. 기본 Base Model인 DeiT-B는 ViT-B와 동일한 구조와 학습방법을 사용하였지만, Hyper Parameter를 Ablation Study를 통해 최적화를 진행하였고 그때 사용된 방법은 위와 같습니다. 특별한 학습방법은 사용되지 않았고, 단순 Hyper Parameter 튜닝을 통해 성능 향상을 이끌어 내었다고 이해하시면 되겠습니다.
다음은 Experiments Part입니다.

먼저, Distillation 관련 실험입니다. 논문에서는 실험을 통해서 Teacher Model이 Convnet일 때 가장 효과가 좋았다고 하였는데요, 그 이유를 ‘아마도’ Inductive Bias 때문이다라고 설명하였습니다. 제가 아마도라는 말을 강조한 이유는 실제로 Probably라는 단어를 사용하여 논문에서 정확한 이유를 분석하지는 못하였기 때문입니다.
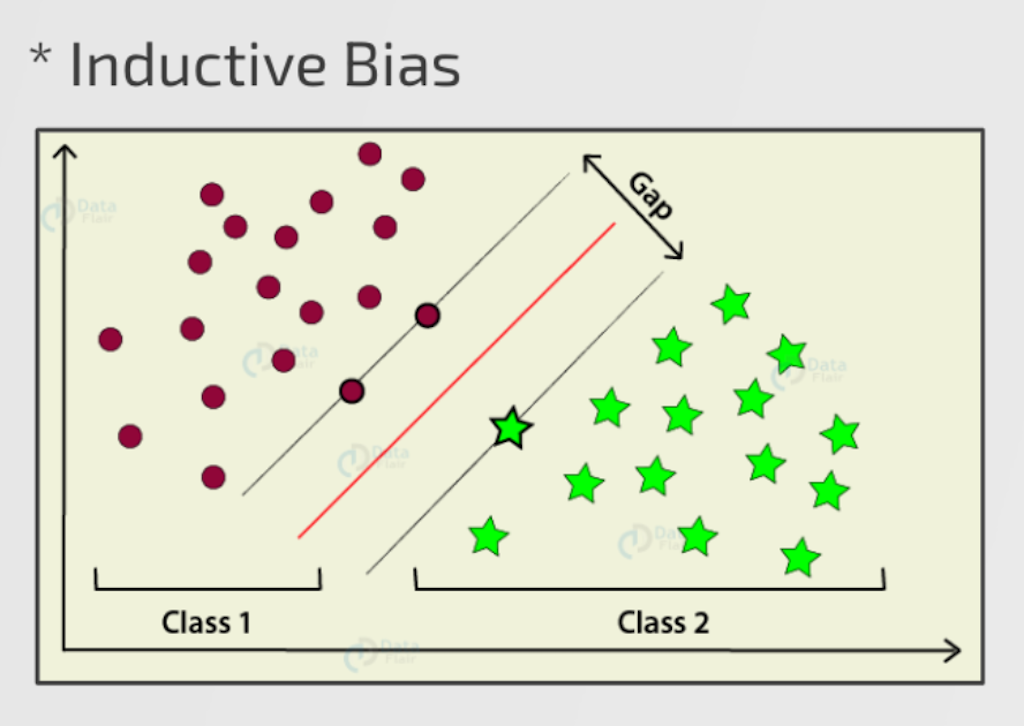
Inductive Bias를 SVM의 예로 설명드리자면, SVM에서 Binary Classification이라고 할 때, 두 데이터 집단을 가장 잘 나누는 선은 빨간색 선이 될 것입니다. 이때, 빨간색 선을 선정하는 기준들이 Inductive Bias가 되고, SVM에서는 이 GAP이 최대화되는 방향으로 선을 선정한다 라는 조건이 있으므로 이 조건이 Inductive Bias라고 합니다.
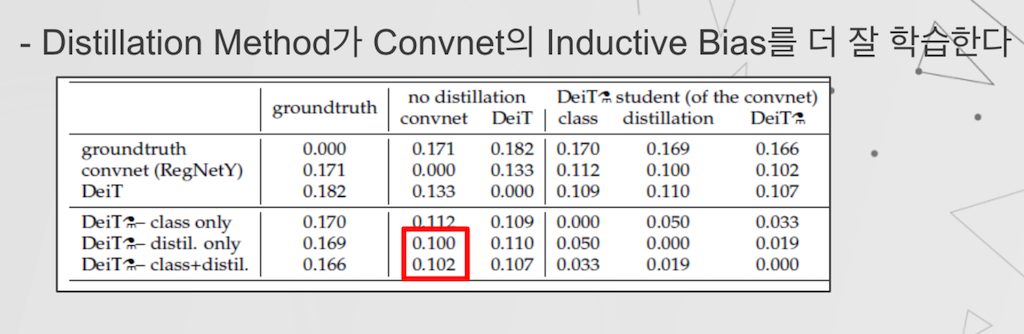
저자는 실험을 통해서 Teacher Model을 다른 Transformer Model이 아니라 Convnet으로 선정하였을 때, Model의 Prediction 간의 차이가 가장 적었다고 하였습니다. 때문에 Convnet의 Inductive Bias를 Transformer가 가장 잘 가져온다라고 이해할 수 있습니다. 또한 전에 설명드린 Hard, Soft Distillation 중에서 Hard Distillation이 더 효과가 좋았다고 실험 결과에서 알 수 있었습니다.

Hard Distillation이 왜 더 좋은지에 대해서는 저자가 서술하지는 않았으나, 개인적인 생각으로는 Hyper Parameter 튜닝이 필요한 Soft Distillation보다는, 튜닝이 필요 없는 Hard Distillation이 이 실험에 더 효과적으로 작용한 것이 원인이지 않을까 싶습니다.
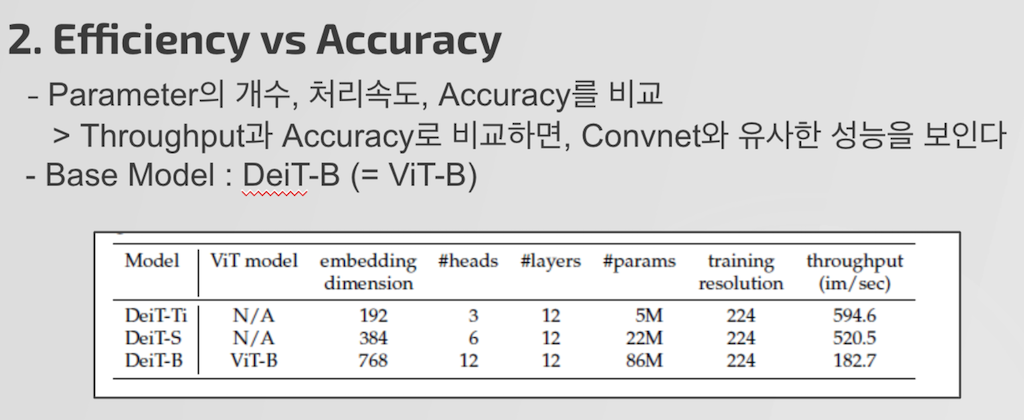
다음 실험은 Model의 Input Embedding Dimension의 개수를 바꾸고, Head의 개수를 바꿔 처리 속도와 정확도 간의 관계를 실험하였습니다.

실험 결과는 보이시는 테이블과 같으며, 빨간 박스를 보시면 유사한 처리속도와 같은 이미지 사이즈, 같은 Parmeter 조건에서 Convnet과 Transformer가 유사한 성능을 나타내는 것을 알 수 있으며 파란 박스를 보시면 같은 조건에서 Transformer기반의 Model이 더 좋은 성능을 보임을 알 수 있습니다.

또한 저자는 ImageNet으로 학습한 데이터를 바탕으로 다른 Dataset에 적용하는 실험도 진행했습니다. 다른 데이터 셋에도 Convnet과 큰 차이 없이 괜찮은 성능을 내는 것을 확인할 수 있었습니다.
마지막으로 Discussion Part입니다.
일단 Contribution으로는 ViT Model을 별다른 구조적인 변화 없이 성능을 향상시켰다는 점입니다. ViT보다 더 적은 Dataset으로 학습 속도를 향상시켰고 정확도 또한 더 향상시켰습니다. 또한 SOTA의 Convnet과 유사한 성능을 보임으로서 Transformer의 가능성을 보여주었고 간단한 방식의 Knowledge Distillation 방법을 제안했다는 점이 있습니다.
Opinion Part는 개인적인 의견으로, 저자와 생각이 다를 수 있다는 점 참고 부탁드립니다. DeiT는 Transformer의 문제인 많은 에폭이 필요로 하다는 점은 해결되지 못하였습니다. 또한 본 논문에서 설명하진 않았지만 은연중에 Transformer의 단점이 드러나는 것을 알 수 있습니다. Hyper Parameter 튜닝만으로 성능이 많이 향상되었다는 것은 그만큼 Hyper Parameter에 민감하다는 것이고, 또한 Convnet 대비 많은 Dataset과 training시간이 필요하다는 점도 단점입니다. 이러한 점을 비추어 볼 때 아직 연구자들에게 연구 기회가 있다는 것은 좋은 일이지만, 실제 현업에 적용하기에는 어려운 단계이지 않을까 싶습니다. 또한 논문 자체가 Deep Learning 초기 연구 시의 방법과 유사하게 흘러가는 느낌을 받았습니다. 초기에는 Quantitative Reearch 방식으로 실험을 통해 좋은 결과가 나오면 좋다! 라는 방식의 연구가 많이 진행되었고, 이 실험을 이론적으로 해석하는 방향으로 연구가 진행되었습니다. 하지만 본 논문에서는 실험도 성공적으로 끝내고, 좋은 결과도 얻었지만은 납득할만한 충분한 이론으로 해석하지 못했다는 점은 아쉬운 부분이었습니다. 마지막 Conclusion입니다. 이 내용은 논문의 Conclusion으로, Transformer가 아직 연구가 많이 필요한 분야라고 인정하였습니다. 하지만 Image 분야에 적용된 지 얼마 되지 않았음에도 불구하고 다년간의 연구가 진행된 CNN과 유사한 성능을 보인다는 것은 매우 고무적인 일입니다. 이 논문은 NLP에서 RNN을 대체한 Trasnformer가 CNN을 대체할 수 있다는 가능성을 보여주었다는 것을 마지막으로 본 논문 리뷰를 마치겠습니다.




댓글