안녕하세요 콥스랩(COBS LAB) 입니다.
오늘 소개해 드릴 논문은 ‘Effectively Leveraging Attributes for Visual Similarity’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임’ 중 ‘Effectively Leveraging Attributes for Visual Similarity’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상 링크:https://youtu.be/FrdtIqyVhbc)
오늘 소개해 드릴 논문은 2021년 CVPR에서 발표된 Effectively Leveraging Attributes for Visual Similarity입니다.

이전에는 이미지 유사도 task에 대해서 복잡하지 않는 특징들을 annotation 하는 연구들이 주를 이루어 annotation에 대한 중요한 정보를 놓치고 있었습니다. 하지만 PAN 네트워크를 통해서 similarity condition을 인지하는 방향으로 학습하는 것에서 joint representation을 얻었습니다. 논문에서는 PAN모델을 통해서 최신 연구보다 정확도가 상승함을 볼 수 있었다고 설명하고 있습니다.
이전 연구에 대한 문제점입니다. 일반적으로는 이미지가 다르다, supervised가 아닌 unsupervised로 배우는 것이 더 정확하다고 알려져 있습니다. 특징들을 하나하나 labeling 하는 게 어렵기 때문입니다.
첫 번째는 유사도에 영향을 끼치는 모든 특성들을 annotation 하는 것이 불가능하고, 두 번째는 유사도에 영향을 끼치는 속성을 명확히 하는 것이 힘듭니다. 그리고 세 번째가 각각의 이미지의 속성을 직접 예측함으로써 노란색 음영과 같은 속성의 미묘한 차이에 대한 정보를 잃는 경향이 있습니다. 위 그림으로 예시를 들면, 두 가지 새는 다른 종입니다. 다른 종이기 때문에 낮은 유사도라고 나오는 게 맞지만 Yellow Beast라는 특성을 가지게 되면서 높은 유사도를 갖게 됩니다. 그렇다면 Yellow Beast의 미묘한 차이에 대한 정보도 hidden layer로 추가한다면, 즉 labeling 된 속성이 Sparse 하고, Sparse 하더라도 속성에 대한 차이도 잡을 수 있다는 것이 이 논문의 요지입니다. 세 번째 이유가 논문에서 가장 크게 본 문제이고 이를 해결하기 위해서 새로운 인사이트를 제시했습니다.
PAN network입니다. 이 PAN 모델 아키텍처에서는 속성이 있다 없다에서 끝나는 것이 아니라 속성인 Similarity 스코어와 relevance 스코어를 같이 보는 Joint feature를 만들었습니다. 그래서 같은 특징을 가지고 있지만 finer attribute difference를 찾을 수 있도록 모델을 설계했습니다.
첫 번째로 PAN network입니다. attribute label과 같은 추가 데이터셋이 없거나 attribute가 이렇게 Sparse할 때도 hidden layer를 통해서 자동으로 학습됩니다. 첫번째로 attribute label값들, 즉 속성이외에 미세한 차이를 잡기위해서 PAN network는 image encoder를 사용하게 됩니다. image encoder를 통해서 아웃풋 feature인 h1과 h2의 hidden layer가 나오게 됩니다.
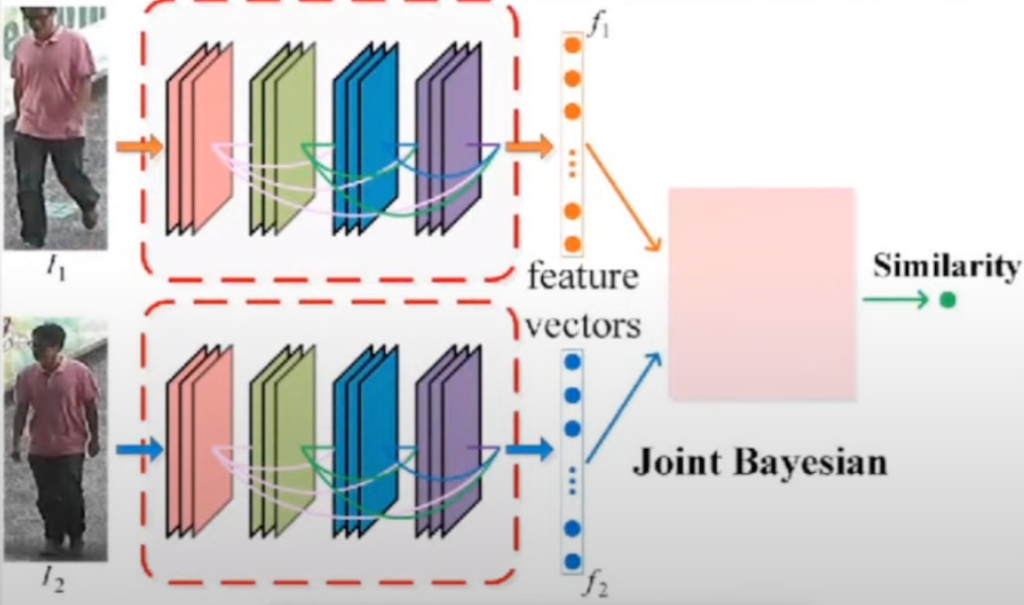
이 image encoder는 총 세 가지가 있는데 이 논문에서 사용한 데이터셋에 맞는 image encoder로 세 가지로 나눠서 사용하였습니다. 첫번째로 단순히 feature 추출해서 두 이미지가 같은 이미지인지 보는 task에서는 ResNet으로 feature representation을 해서 image encoder를 사용했고, 그래서 결괏값으로 hidden layer h1과 h2를 제시하게 됩니다.
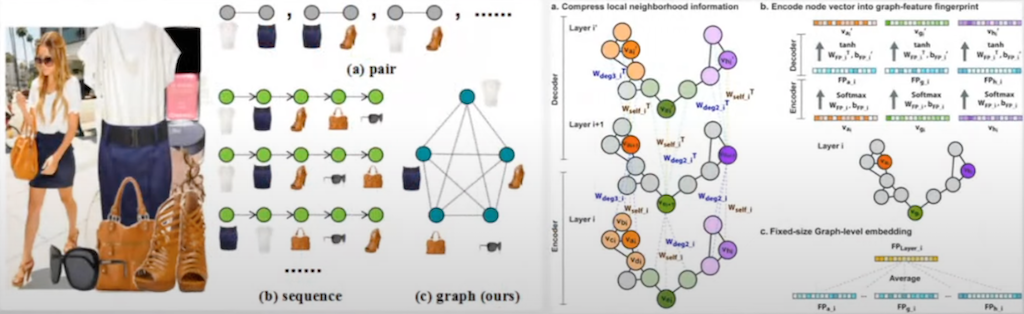
두 번째, Graph encoder는 패션 호환성을 찾는 패션 이미지 쪽에서든 CNN으로 feature를 추출한 후에 Graph encoder를 사용해 feature 추출하는 경우가 많았고, 이를 통해서 h1과 h2를 추출하였습니다.
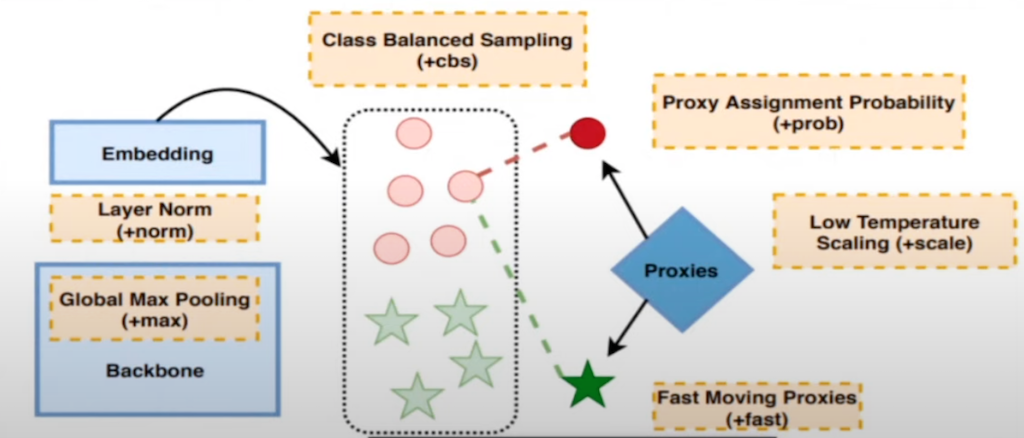
그리고 Graph encoder가 비용 적으로 비쌀 때, 이미지 유사도 추출에 많이 사용되는 ProxyNCA++도 이 논문에서 image encoder로 사용한 것을 확인할 수 있습니다.
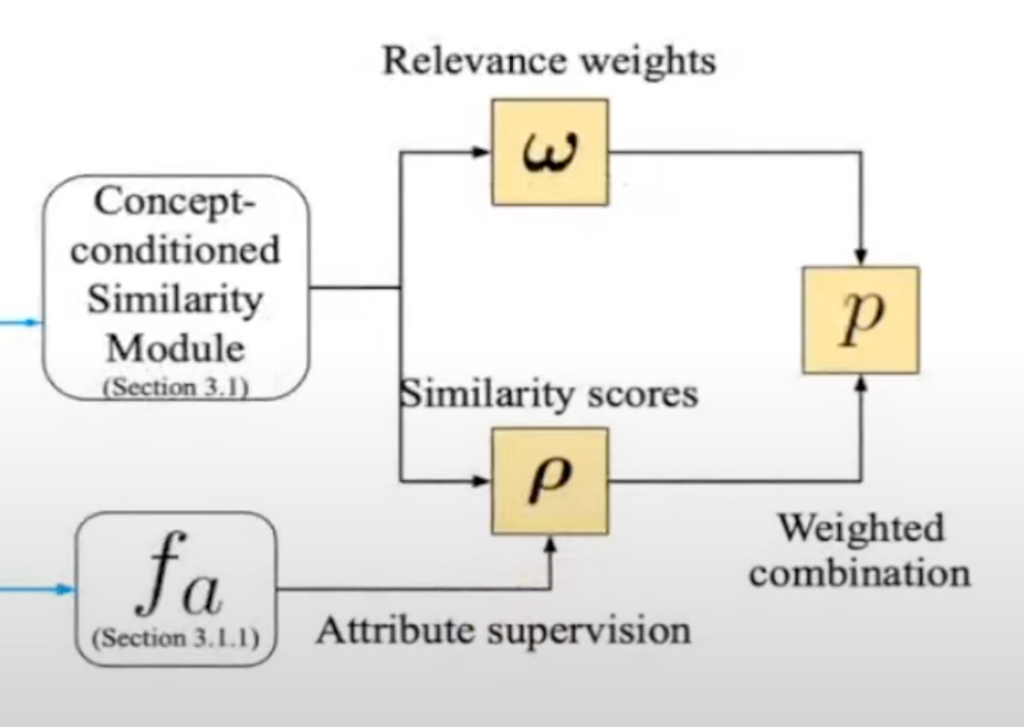
image encoder를 통해 나온 feature h1과 h2를 통해 CSM 모듈에 들어갑니다. 이 CSM 모듈을 통해 최종 유사도 값이 산출됩니다.
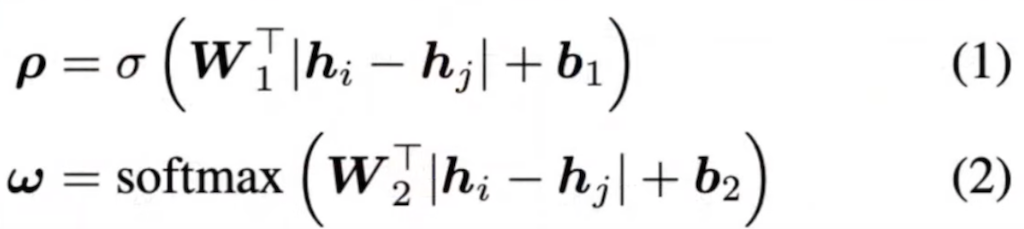

image encoder를 통해서 나온 h1과 h2를 통해서 similarity score p와 relevance score weight가 구해지고, 이 hidden layer의 차이로 similarity score와 relevance weight도 구합니다. 그리고 여기서 W1과 W2, b1과 b2가 학습이 되고 최종 유사도의 값 p는 다음 값의 합입니다.
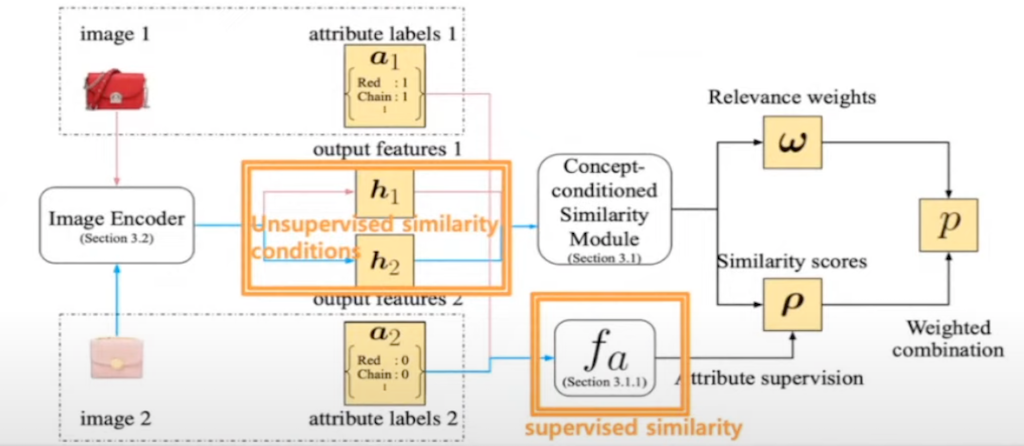
PAN network에서 similarity conditions을 결정하는 경우는 unsupervised similarity conditions과 supervised similarity conditions 이렇게 두 가지가 있는데, unsupervised similarity conditions은 image encoder를 통해, h1, h2를 통해서 결정이 됩니다. 여기서 추가적으로 fa라는 logical function이 추가됐습니다. fa는 AND OR NOR 게이트 등이 있는 logical function를 의미합니다.

다음은 트레이닝 방식입니다. binary cross entropy Loss function을 사용하였고, 만약 super vision attribute가 없다면, 즉 annotation 된 attribute가 없다면 Lamda 값은 0이 됩니다.

논문에서 사용하게 된 데이터셋은 3가지입니다.
첫 번째는 Polyvore Outfits입니다. 해당 데이터셋은 크게 두 가지 task가 있습니다. 첫 번째 task는 네 가지 선택지 중에서 현재 있는 패션과 어울리는 선택지를 찾는 것입니다. 퍼포먼스는 얼마나 자주 정답을 맞는 지로 측정됩니다. 두 번째 task는 패션이 잘 compatible 한 지 확인하는 것이고, 이 측정지표는 AUC지표로 측정됩니다. 기존 Polyvore Outfits 데이터셋에서는 두 task 모두 perfect 퍼포먼스를 보였기 때문에 PAN 논문에서는 기존 데이터셋보다 어렵게 만드는 과정을 resample 했습니다. PAN 논문에서는 4개 후보군에서 10개 후보군으로 바꾸고 패션 compatible 경우에만 negative 데이터셋을 모든 카테고리를 바꾸는 것이 아니라 한 가지의 카테고리만 바꾸는 등 더 어렵게 데이터셋을 형상화하게 했습니다.
두 번째 데이터셋은 새의 종을 구분하게 되는 CUB 데이터셋과 세 번째 데이터셋은 패션 이미지에서 많이 사용하게 되는 In Shop Retrieval 데이터셋입니다. In Shop Retrieval 데이터셋은 Retrieval 데이터셋에서 query 이미지 데이터, 즉 한 옷과 같은 데이터를 찾는 task입니다.
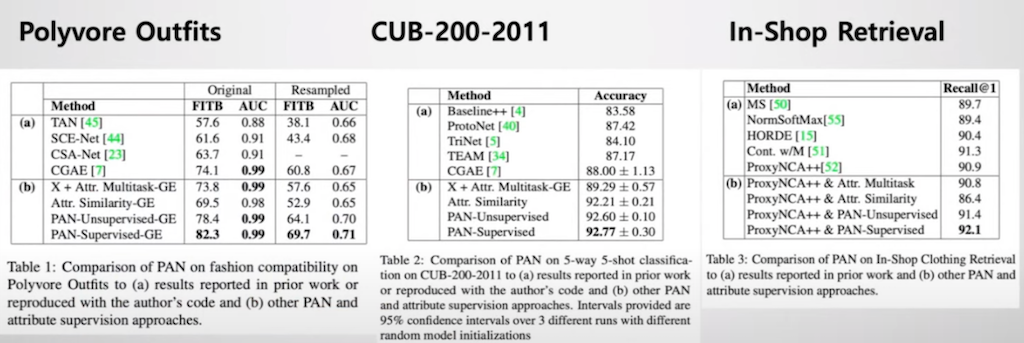
PAN 모델 아키텍처는 세 가지 데이터셋에서 모두 최신 연구보다 높은 정확도를 가지고 있는 것을 보였습니다. 특히 no supervised일 때도 유용하다는 것을 볼 수 있습니다.
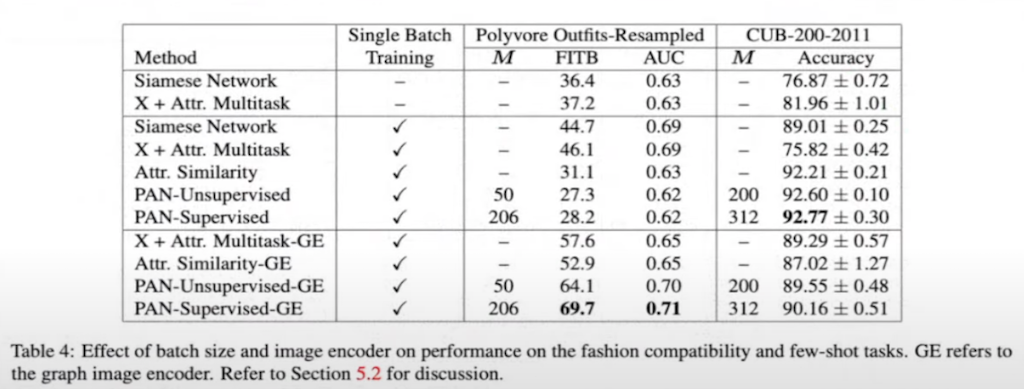
이전에는 이미지 유사도에 대한 batch 크기와 매개 변수의 차이에 대한 일관성이 없었지만 해당 연구에서는 whole 트레이닝을 하거나 또는 mini batch를 사용해서 정확도 차이를 서술했습니다. 그리고 image encoder에 있어서도 Graph encoder와 단순한 CNN이 Siamese network의 차이를 비교 서술했습니다. Polyvore Outfits에서는 PAN GE encoder가 단순히 그냥 종을 분류하는 이미지 데이터셋에서는 Siamese 보다는 PAN 기반 네트워크가 정확한 것을 확인할 수 있습니다.
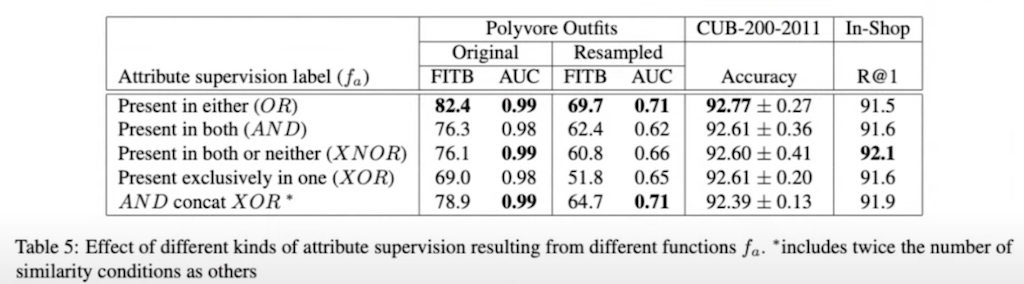
fa logical function입니다. 두 이미지에 속성이 있거나 둘 다 없는 경우, 즉 XNOR를 사용했을 때 이 두 개의 이미지가 유사한 1에 가깝다고 예측하는 것이 직관적인 선택처럼 보입니다. 하지만 다른 속성을 포함하기 때문에 이미지가 일치할 수 있는 패션 호환성의 Polyvore Outfits 데이터셋에서는 XNOR이 적절하지 않다고 보여주고 있습니다. Polyvore 이상의 패션 호환성에서는 OR이 가장 우수한 것을 볼 수 있고 단순히 새의 종을 구분하는 CUB 데이터셋에서는 여전히 XNOR이 경쟁력이 있음을 보입니다. fa logical function을 보면 여전히 XNOR이 가장 적합하다는 걸 확인할 수 있습니다.
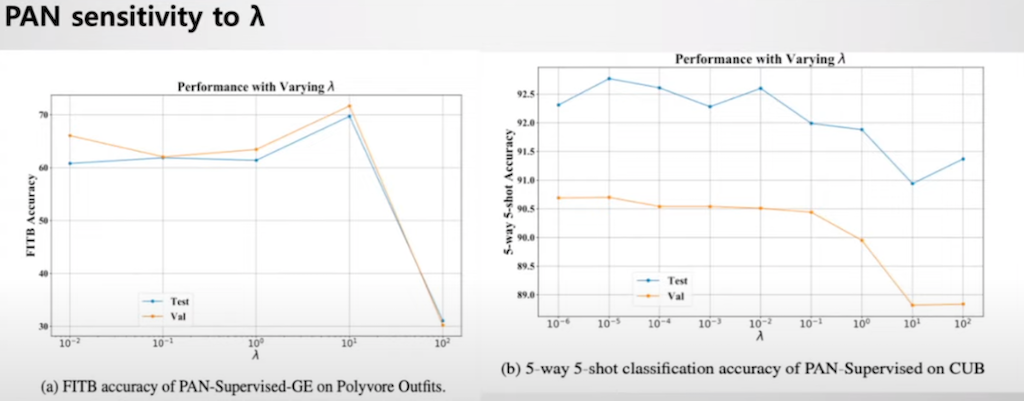
λ에 대한 PAN 모델의 민감도는 Polyvore Outfits 데이터셋에서 λ가 10일 때 정확하고, CUB 데이터셋에서는 λ가 10의^-5일 때 정확도가 가장 높은 것을 확인할 수 있습니다.

결론입니다. PAN 모델을 통해서 Joint feature image에 Similarity score, 즉 속성 값과 relevance score의 미세한 차이를 같이 볼 수 있게 됐습니다. 또한 attribute가 Sparse 할 때도 image encoder를 통해서 hidden layer가 자동으로 학습될 수 있다는 것에서 기존 논문과 다른 인사이트를 제공했고 최신 기술의 정확도를 능가했다는 점에서 큰 의의가 있다고 결론을 지었습니다.




댓글