안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘MLP-Mixer: An all-MLP Architecture for Vision’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘MLP-Mixer’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상 링크: https://youtu.be/L3vEetyNG_w)

본 논문이 이야기하는 특징을 설명드리겠습니다. 지금까지 흘러온 컴퓨터 비전 분야에서 알 수 있듯이 더 큰 데이터 셋 사용과 컴퓨팅 용량 증가라는 패러다임 전환으로 이어지고 있습니다. 그리고 Convolutional Neural Network가 컴퓨터 비전에서 일반적으로 사용하는 네트워크가 되어왔습니다. 이것을 조금 더 개선하고자 batch normalization 혹은 skip-connections 등을 좀 더 추가한 연구들이 많이 이루어졌습니다. 최근에는 ViT라 불리는 self-attention layer에 기반한 vision transformer가 나오면서 sota를 찍고 있는 것을 볼 수 있습니다. 이 ViT의 경우, hand crafted visual feature와 inductive biases를 완화시키는 것으로 알려져 있습니다. 본 논문에선 두 가지를 사용하지 않는 개념적으로나 기술적으로나 경쟁력 있으면서도 단순한 아키텍처인 MLP-Mixer를 제안했습니다.
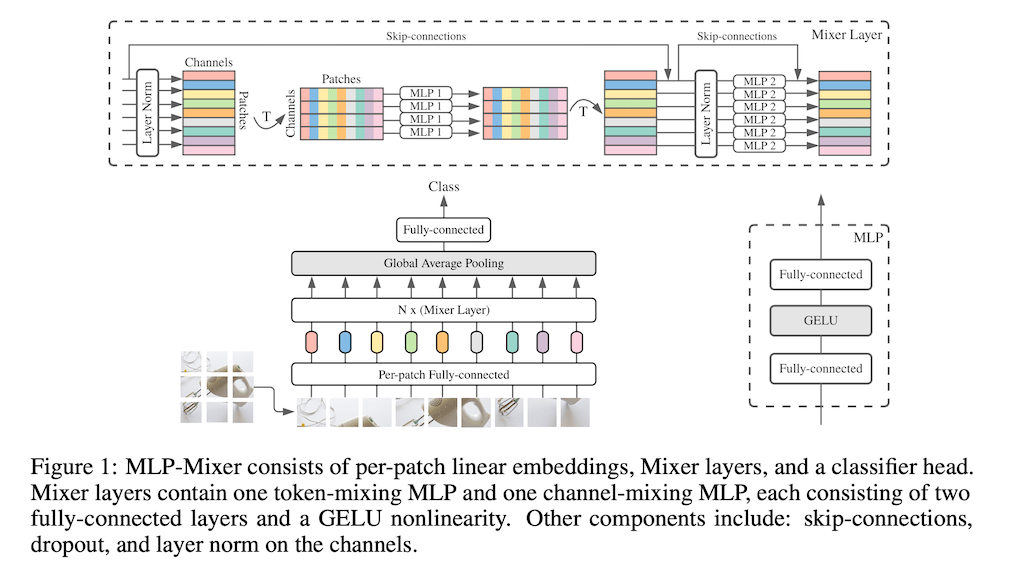
Mixer 구조에 대해 설명드리겠습니다. Mixer 구조는 크게 두 가지로 channel-mixing과 token-mixing으로 나뉘어있습니다. 이것을 CNN기반 모델과 self attention 모델로 가져가게 된다면, channel-mixing은 convolution에서 1 x 1 convolution을 진행하는 것과 동일하다고 생각하시면 됩니다. token-mixing의 서로 다른 spatial locations 간에 섞고 CNN에서 N x N convolution과 pooling을 이용하는 부분과 동일합니다. 어떻게 보면 depth-wise convolutions과도 유사하다고 생각할 수 있는데 attention 기반 네트워크로 가게 된다면, 해당 네트워크가 이 두 가지를 모두 진행합니다.
인풋 이미지가 들어간다라고 가정을 했을 때 우리는 이걸 H와 W로 나눠서 이야기를 하겠습니다. S는 토큰으로 나눠진 것의 길이다라고 할 수 있고 그렇기 때문에 HW / P^2으로 작성할 수 있습니다. 그래서 여기서 인풋으로 들어간 패치당 Fully-connected를 거쳐서 projection 시킨 것을 표현하자면 N x(Mixer Layer)에 들어가는 X에 해당되는 파트의 크기가 S x C에 해당 되게 됩니다. 본 논문에서 추가로 얘기를 했던 것은 S x C 구조가 결국 Sparse Convolution과 유사하다고 설명합니다. 그 후 S가 각각의 믹싱 파트를 거쳐서 classification까지 진행된다고 생각해 주시면 됩니다.

각각의 patch x channel이 들어가게 되면 이것을 transform 시켜서 토큰 와이즈로 mixing이 한번 들어가게 됩니다. 토큰 와이즈는 channel이 있고 patch가 있으면 patch x로 진행이 되는 것입니다. 채널에 대해서 MLP로 채널 mixing이 진행됩니다.

MLP는 Fully-connected로 진행되기 때문에 patch x channel 크기는 계속 동일하게 유지가 되고 Activation으로 GELU를 사용했습니다.

실험을 어떻게 설정했는지에 대해 설명드리겠습니다. 먼저 본 논문에서는 크게 세 가지를 알아보기 위한 실험을 했습니다. 어떻게 보면 기존 네트워크들보다 더 뛰어났다 라는 것을 이야기하기보다 기존 네트워크랑 유사한 성능을 지녔기 때문에 MLP만으로도 충분하다고 합니다. 그래서 downstream task의 정확성 그리고 Upstream 데이터셋에서 모델을 처음 훈련할 때 필요한 pre-training 중에서 전체 computational cost를 본 것이 있고 그리고 마지막으로 실무에서 중요하다고 할 수 있는 inference time 처리량을 보고자 했습니다. 여기서 굉장히 많은 데이터셋을 사용하고 있습니다. 그래서 downstream task는 분류 문제를 해결하는 다섯 개의 해당되는 데이터셋을 사용하고 있습니다. Pre- training는 큰 스케일의 데이터를 사용을 하면 좀 더 좋은 결과가 나타나는 것을 보여주고 있습니다.

Fine-tuning details은 기존 학습에 사용했던 데이터 크기보다는 해상도가 조금 더 큰 224 혹은 448을 사용했습니다. 여기서는 패치 크기를 동일한 것을 사용을 했기 때문에 Fine- tuning에서 큰 데이터 사용을 하게 되는 경우에 커진 데이터만큼 패치도 늘어나게 되고 그만큼 모델도 커집니다.
Metrics의 경우 크게 두 가지로 Computational cost와 Model quality가 있습니다. Computational cost의 경우 전체 pre-training time을 계산했고 세 가지 요소를 함께 볼 수 있습니다. model quality의 경우, fine-tuning 다음에 top-1 downstream accuracy로 측정했습니다.

다음은 다양한 Mixer 모델을 설정해서 진행했습니다. 그래서 모델 크기 자체가 “B”, “L”, “H” 이야기를 하면서 그 정도의 크기로 스케일이 어떻게 되는지를 볼 수 있고 추가로 서로 다른 패치 크기로 사용을 한 것을 확인할 수 있습니다. 그리고 각각 Hidden size나 Sequence length 도 서로 다른 것을 볼 수 있고 이것을 기반으로 해서 실험을 진행했습니다.

다음은 본 모델과 비교한 baselline 모델입니다. 사실 MLP-Mixer 자체는 convolution이나 self attention을 사용하지 않기 때문에 이전 sota와 다른 아키텍처라 할 수 있습니다. 사실 MLP-Mixer는 CNN과 Transformer로부터 아이디어를 얻어냈기 때문에 attention 기반, Conv 기반으로 서로 다른 네트워크들을 비교를 했습니다. attention 기반으로는 ViT 모델이 들어가게 되고 추가적으로 local self attention layer를 사용한 HaloNet이나 Conv기반으로는 Big Transformer, NFnet 등을 사용을 해서 실험을 했습니다. 이것은 ResNet 기반이고 Efficent Net으로 진행을 한 것입니다.

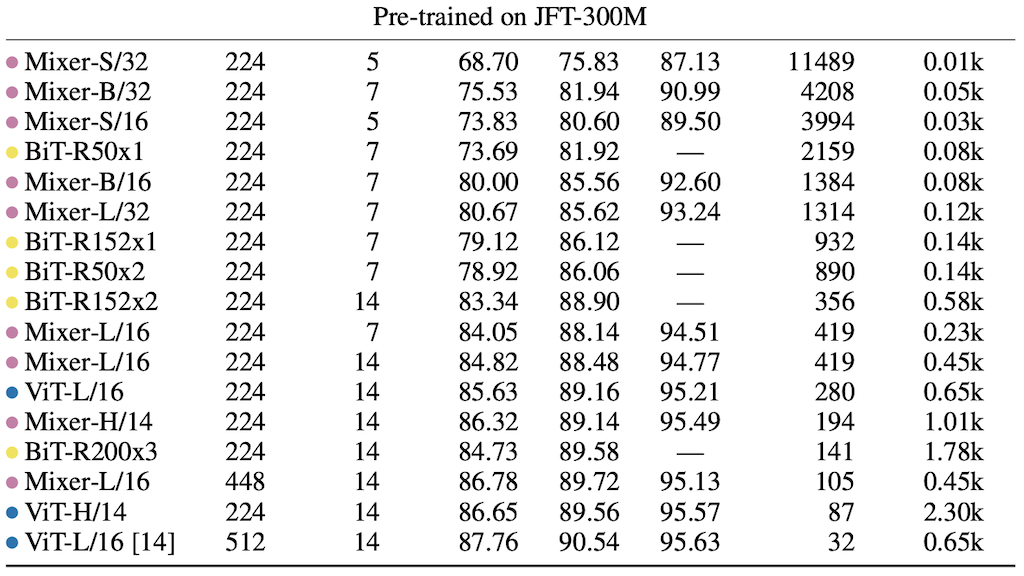
Main Results입니다. Mixer는 다른 모델에 비해 약간 낮지만, 전반적으로 좋은 성능 (ImageNet에서 84.15 % top-1)을 보임을 볼 수 있습니다. 먼저 ImageNet 같은 경우는 기본 ImageNet을 사용했고 Real L 같은 경우는 레이블을 clear 한 데이터입니다. Avg 5는 다섯 개의 downstream task를 평균을 낸 값입니다. Throughput img/see/core은 inference time에 해당되고 TPUv3는 computational cost를 나타냈습니다. Mixer는 다른 모델에 비해서 성능이 크게 차이가 나지 않고 전반적으로 좋은 성능을 보이는 것을 볼 수 있습니다. 분홍색점이 Mixer에 해당되고, 노란색 점이 convolution결과, 그리고 파란색 점이 attention과 관련된 결과입니다.
Mixer는 네트워크에서 upstream 데이터셋의 크기가 증가하면 성능이 크게 향상됩니다. 그래서 Mixer는 ViT와 유사하게 regularization이 필요하다고 설명합니다.

결과 figure입니다. 좌측 그림을 보시면, 정확도와 계산량의 trade off 측면에서 Mixer가 기존의 아키텍처와 경쟁할만하다는 것을 확인할 수 있습니다. 또한 아키텍처 class 간에도 전체 pre-training cost와 downstream accuracy 간의 상관관계를 볼 수 있습니다.

Pre-training dataset의 크기에 따라 달라지는 것을 보여준 표입니다. 큰 데이터 셋에 대한 Pre-training이 Mixer의 성능을 크게 향상한다는 것을 볼 수 있습니다. 본 논문에서 추가로 이야기했던 것은, 작은 JFT 데이터셋으로 pre-train을 한 경우, Mixer 모델이 overfitting 한 것을 설명하고 있습니다. 동시에 ViT 모델 또한 overfitting 하지만, 덜 overfitting 된다고 설명하고 있습니다. 그러나 ViT의 경우 conv기반으로 한 모델인데 convolution 때문에 inductive bias가 강하게 발생해서 어느 정도 overfit이 발생했다고 이야기하고 있습니다.

모델 스케일과 관련된 결과입니다. 본 논문에서는 모델 크기를 늘리는 것과 Fine-tuning 시에 입력 해상도를 늘리는 것 두 가지를 고려했습니다. Pre-training에서 모델 크기를 늘리는 것은 컴퓨팅 테스트 시간, 처리량 모두에 영향을 미치지만, Fine-tuning에서 입력 해상도를 늘리는 경우에는 처리량에만 영향을 줍니다. 그래서 논문에서는 Fine-tuning에서 해상도를 224를 사용하는 것으로 진행했습니다. 이에 대한 결과가 동일하게 나타나고 있고 Image size가 448도 나타내고 있습니다. 그리고 Image size와 각각 얼마만큼의 epoch를 사용했는지에 대해서 가까운 computing 타임과 inference 타임을 같이 보여주고 있습니다. 결과적으로 다른 모델들과 Vit와 같이 크게 차이 나지 않는 결과를 보이고 있습니다.
서로 다른 Conv나 attention과 비교를 하는 Mixer 모델들의 차이를 보여주는 결과입니다. 동일하게 크게 차이가 나지 않는 것을 볼 수 있습니다.

Mixer모델이랑 ViT, Resnet까지 포함해서 크게 차이 나지 않은 결과를 볼 수 있습니다. 또한 training에서도 loss가 ViT랑 비교했을 때 Mixer가 굉장히 유사하다고 이야기를 하고 있습니다. 동시에 ViT보다는 조금 더 overfitting이 발생되었다고도 이야기하고 있습니다.
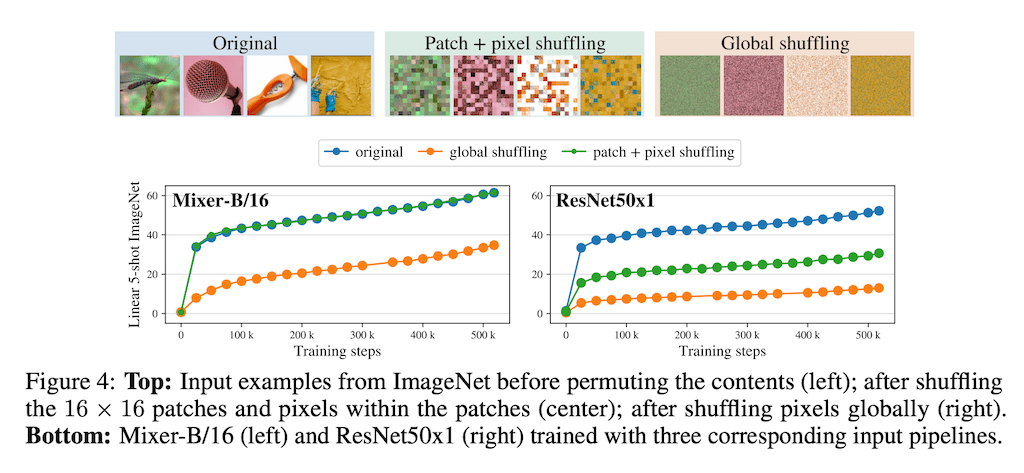
inductive bias랑 관련된 결과입니다. 여기서는 CNN 구조와 Mixer 간의 차이를 다음과 같이 보여주고 있습니다. 여기서는 두 가지 서로 다른 transformation을 이용한 입력을 사용하여 실험을 했습니다. Patch+ pixel shuffling은 각 패치 내에서 패치 순서와 픽셀 순서를 섞은 것이고 Global shuffling는 전체 이미지에서 픽셀을 전반적으로 섞은 것을 이용했습니다. Mixer는 파란색과 녹색 곡선이 일치 함을 볼 수 있고, 반면에 ResNet의 경우, inductive bias로 인해 이미지 내의 특정 픽셀 순서에 의존하기 때문에 성능이 크게 저하된 것을 확인할 수 있습니다.

visualization 파트입니다. CNN과의 차이를 보여주려고 한 부분이라 할 수 있습니다.
일반적으로 CNN의 첫 번째 레이어는 이미지의 로컬 영역에서 픽셀에 작용하는 Gabor와 유사하게 학습하는 것을 볼 수 있다고 합니다. Mixer는 token-mixing에서 global 정보를 교환하는 부분이 있다고 하고 정보를 CNN과 유사한 방식으로 처리하는지를 보고자 했습니다. 참고로 학습된 unit 구조는 hyperparameter에 따라 다르다고 이야기를 하고 있습니다. 그래서 본 그림 같은 경우에는 JFT-300 데이터셋을 이용을 해서 훈련된 Mixer의 처음 3 개 token-mixing의 hidden unit을 나타낸다고 하고 있습니다. 학습된 feature들 중 일부는 전체 이미지에 대해 진행된다고 할 수 있지만, 다른 영역들은 작은 영역에 대해 진행되는 것을 볼 수 있습니다. 그리고 layer가 깊어질수록 조금 더 복잡하고 식별하기 어려운 구조로 진행되는 것을 볼 수 있고 이것을 통해서 MLP-Mixer가 어떻게 학습이 되는지 feature을 나타내 주는 그림을 보여주고 있다고 할 수 있습니다.

결론입니다. 본 논문에서는 비전 분야에서 단순한 네트워크를 보여주었고, 실용적인 측면에서 feature가 어떤 것을 학습하는지와 CNN과 Transformer 모델과 비교를 했을 때 어떤 점이 다른지를 보여주었습니다. 이론적 측면에서는 좀 더 inductive bias에 대해 도움이 된다고 얘기를 하고 Mixer 모델이 나중에 motivation에 좀 더 기여를 많이 할 거 같다고 설명합니다.




댓글