오늘 소개해 드릴 논문은 ‘YOLOX’입니다.
콥스랩(COBS LAB)에서는 주요 논문 및 최신 논문을 지속적으로 소개해드리고 있습니다.
해당 내용은 유튜브 ‘딥러닝 논문읽기 모임' 중 ‘YOLOX’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상 링크: https://youtu.be/N2rLSzEqqI8)
YOLOX 논문은 Object Detection에서 자주 사용되는 YOLO 모델에 Anchor free 메서드를 적용해서 성능을 향상하는 방법을 소개한 논문입니다.

본격적인 모델 소개 앞서 Object Detection이라는 건 무엇인지, 그리고 YOLO 시리즈의 관해서 간략하게만 되짚어보겠습니다. Object Detection은 이미지에 있는 객체를 찾고 그 해당 영역을 bounding box를 하는 테스크를 의미를 합니다. 최근에 트랜스포머 계열의 모델들이 Object Detection 태스크에 들어오기 전에 대부분의 Object Detection 모델들은 CNN 기반이었습니다.

YOLO 역시 대표적인 CNN 기반의 네트워크입니다. 위 그림에서 오른쪽 숫자들은 YOLO 시리즈들의 퍼블리시 연도 그리고 citation 수를 나타내고 있습니다. 해당 논문의 citation수가 굉장히 높은 것을 확인하실 수 있습니다. detection관련 논문에서 가장 유명한 논문이라고 해도 과언이 아닌 것 같습니다.
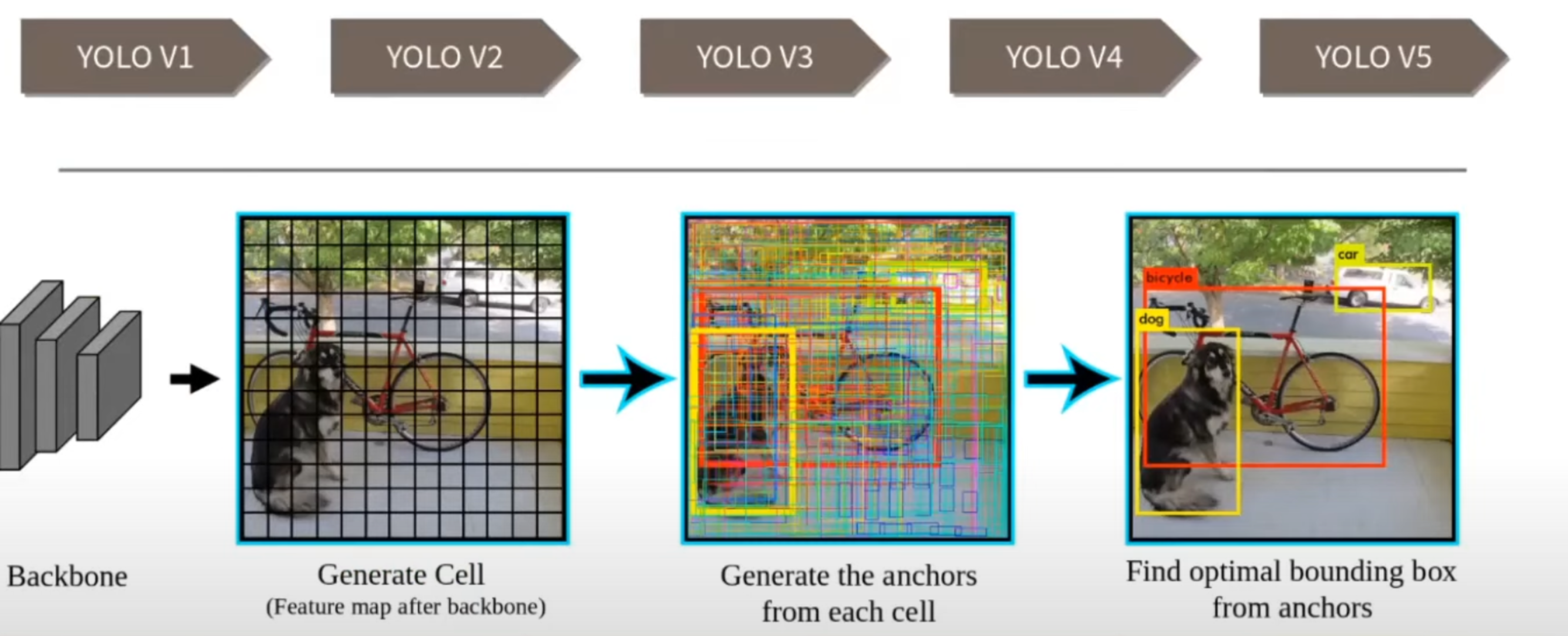
YOLO의 작동방식에 대해 설명드리겠습니다. YOLO는 시리즈별로 작동방식이 조금은 상이하지만 V1을 제외한 모든 버전에서는 공통적으로 사용되는 Anchor라는 특징이 있습니다. Anchor는 object detection을 할 때 다양한 비율과 다양한 크기의 오브젝트를 잘 잡아내기 위해서 도입이 되었습니다. Anchor를 간단히 말하면 bounding box를 만들어내기 위해 기반이 되는 설정값입니다. Anchor를 사용하는 방식은 위 그림들이 나타내고 있습니다. 첫 번째 단계로는 일반적인 네트워크와 같이 backbone을 통해서 feature extraction을 진행합니다. 위 그림에서는 13 * 13인데 바로 맨 마지막 backbone 아웃풋의 feature map의 shape이라고 생각을 해 주시면 될 것 같습니다. 피쳐 맵 각각의 한 칸 들을 YOLO에서는 Cell이라는 명칭으로 부릅니다. 따라서 본 예제에서 개수는 Cell이 169개라고 볼 수 있습니다. 그리고 각각의 Cell에는 depth를 포함하고 있습니다. 만약에 아웃풋 디멘션이 13 * 13 * 10이라면 Cell 하나의 shape은 1 * 1 * 10입니다. 각 Cell에서 Anchor를 만들어 내고 그 Anchor를 기반으로 다시 bounding box를 만들어내는 과정을 거치게 됩니다. Cell 각각에서 Anchor를 만들어 내고 bounding box를 다 만들어 내다 보니까 전부 다 visualization 하면, 위 그림과 같이 엄청나게 많은 bounding box가 생깁니다. 이 bounding box 후보군들 중에서 ground truth(GT)와 겹치는 accuracy가 높은 bounding box만 남기고, 그 bounding box 중에서도 또 좋은 것만 골라서, 결국에는 이렇게 원하는 레이블을 찾는 오브젝트의 영역을 디텍션 하는 방식이 됩니다. 결국 Anchor라는 것이 bounding box를 만드는 기반이 되고, 이것으로 bounding box를 만들어서 GT에 근접한 것들을 남기는 과정이라고 생각하시면 될 것 같습니다.
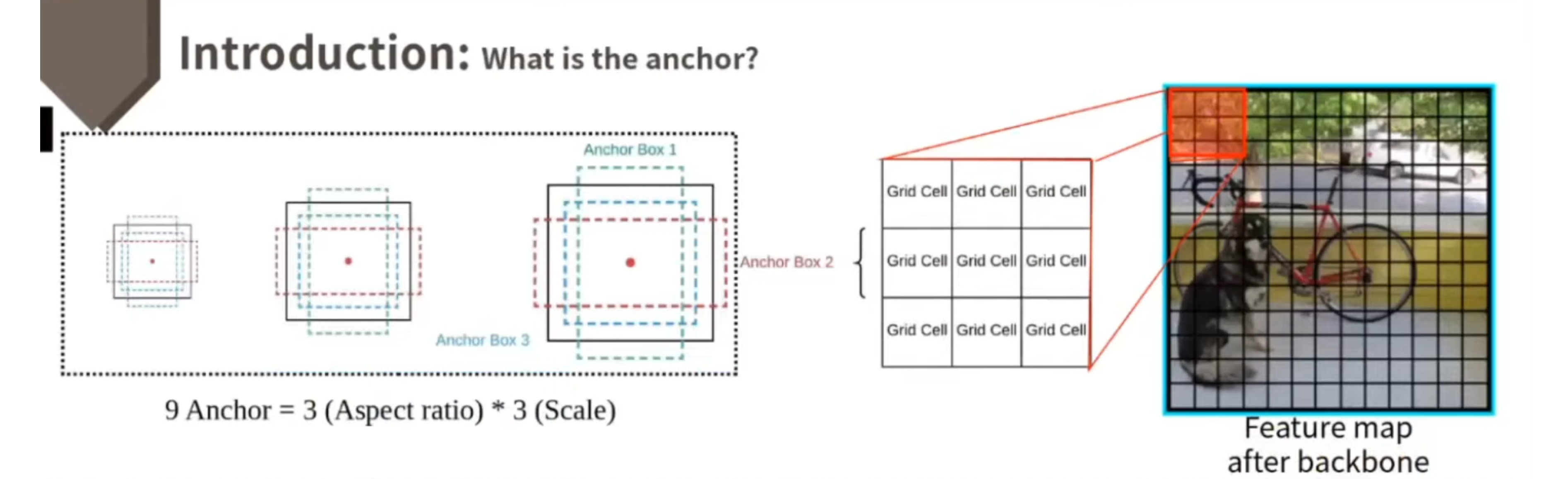
Anchor에 대해서 조금 더 자세히 알아보도록 하겠습니다. Anchor는 bounding box를 만드는 기반이 되는 값들입니다. 그래서 Anchor는 다양한 비율과 다양한 크기의 오브젝트를 좀 더 잘 찾을 수 있도록 하는 목적으로 만들어졌기 때문에, 이런 Anchor 또한 다양한 사이즈와 다양한 Aspect ratio를 가지고 있습니다. 위 그림에서 보시면, 하나의 사이즈가 세 개의 Aspect ratio를 가져서 총 아홉 개 Anchor를 가지고 있습니다. 일반적으로 9개 Anchor를 많이 사용하기에, 여기서도 예시로써 9개 Anchor를 들었습니다. backbone 후에 feature map이 위와 같다고 하면, 9개 Cell만을 보면 9개 Cell 중, 한 Cell에서는 9개 Anchor를 기반으로 bounding box를 만들어내게 됩니다. 따라서, 총 Anchor의 개수는 13 * 13이니까 169 * 9개의 Anchor가 만들어지게 됩니다.
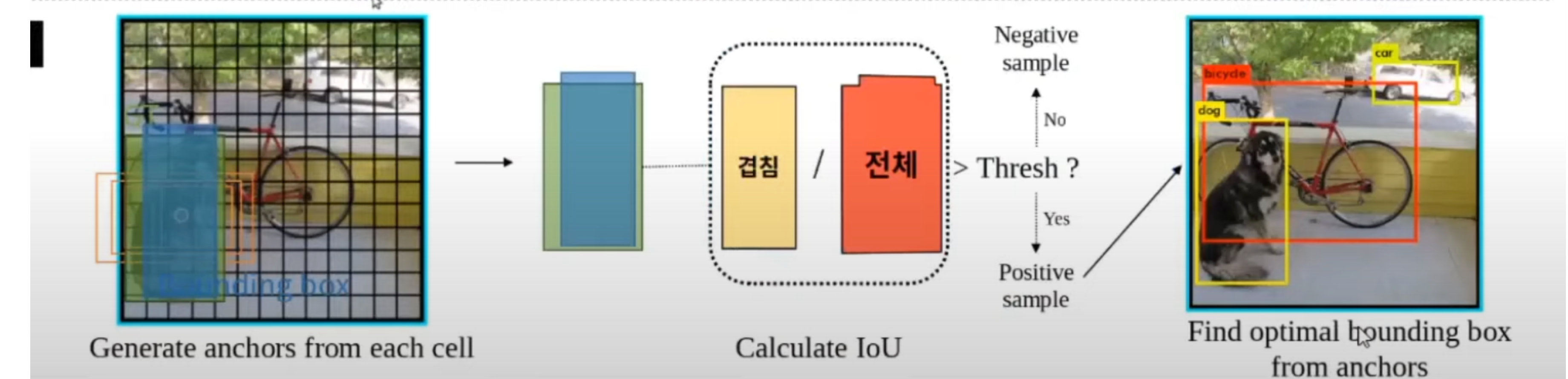
bounding box 또한 똑같은 개수로 만들어진다고 생각을 하시면 될 것 같습니다. 그림과 같이 만들어진 bounding box는 초록색 부분이 GT 부분이고 파란색 부분이 bounding box부분입니다. 그리고 GT와 이 bounding box와 얼마나 겹치는지 측정을 합니다. 얼마나 많이 겹치는지 를 나타내는 지표를 IoU 라고 합니다. IoU는 두 박스가 있을 때, 두 박스 전체영역 / 겹치는 영역으로 하나의 밸류를 만들어내서 밸류가 일정 이상이면 이것이 GT와 어느정도 근접한 bounding box를 예측했다 라고 생각을 해서 Positive 샘플로 분류를 하게 되고, Positive 샘플들을 모아서 학습을 진행을 하게 됩니다. 여기까지 진행하면 마지막에 후보군 bounding box들 중에서 조금 더 accuracy가 높은 것들만 추려내면 깔끔하게 bounding box가 남는 과정이 진행됩니다. 이런 방식으로 Anchor를 통해서 bounding box를 만들어 내고, 학습을 진행하는 만큼 Anchor base 메서드는 recall은 조금 높지만 계산량이 많고 Negative 샘플이 많기 때문에, class imbalance problem이 가중되는 단점이 있습니다.
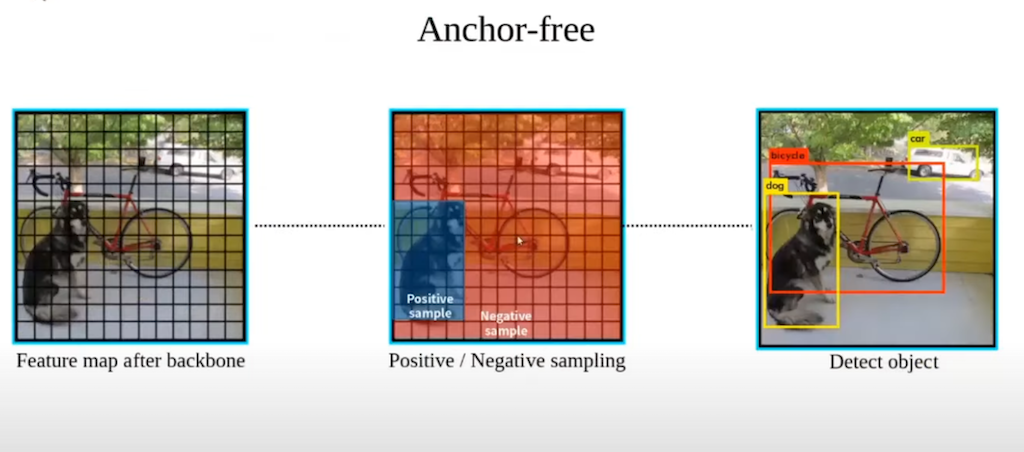
YOLOX에서는 Anchor를 사용하지 않는 Anchor free 방법을 사용합니다. 간략하게 말해서, Anchor free 메서드는 feature extraction 과정까지는 같지만, Anchor free라는 이름과 같이, 각 Cell마다 Anchor를 사용하지 않고, 바로 bounding box나 class를 classification 하는 과정을 거칩니다. 위 그림에서 그라운드 박스가 파란색 Cell이라고 하면, GT bounding box에 속하는 Cell들은 Positive 샘플로 할당하고, 속하지 않는 것은 Negative 샘플로 할당을 하게 됩니다. 이 논문에서는 이와 같은 Anchor free 방법에 추가적인 여러 방법들을 사용을 해서 성능 향상을 이끌어 냈습니다.
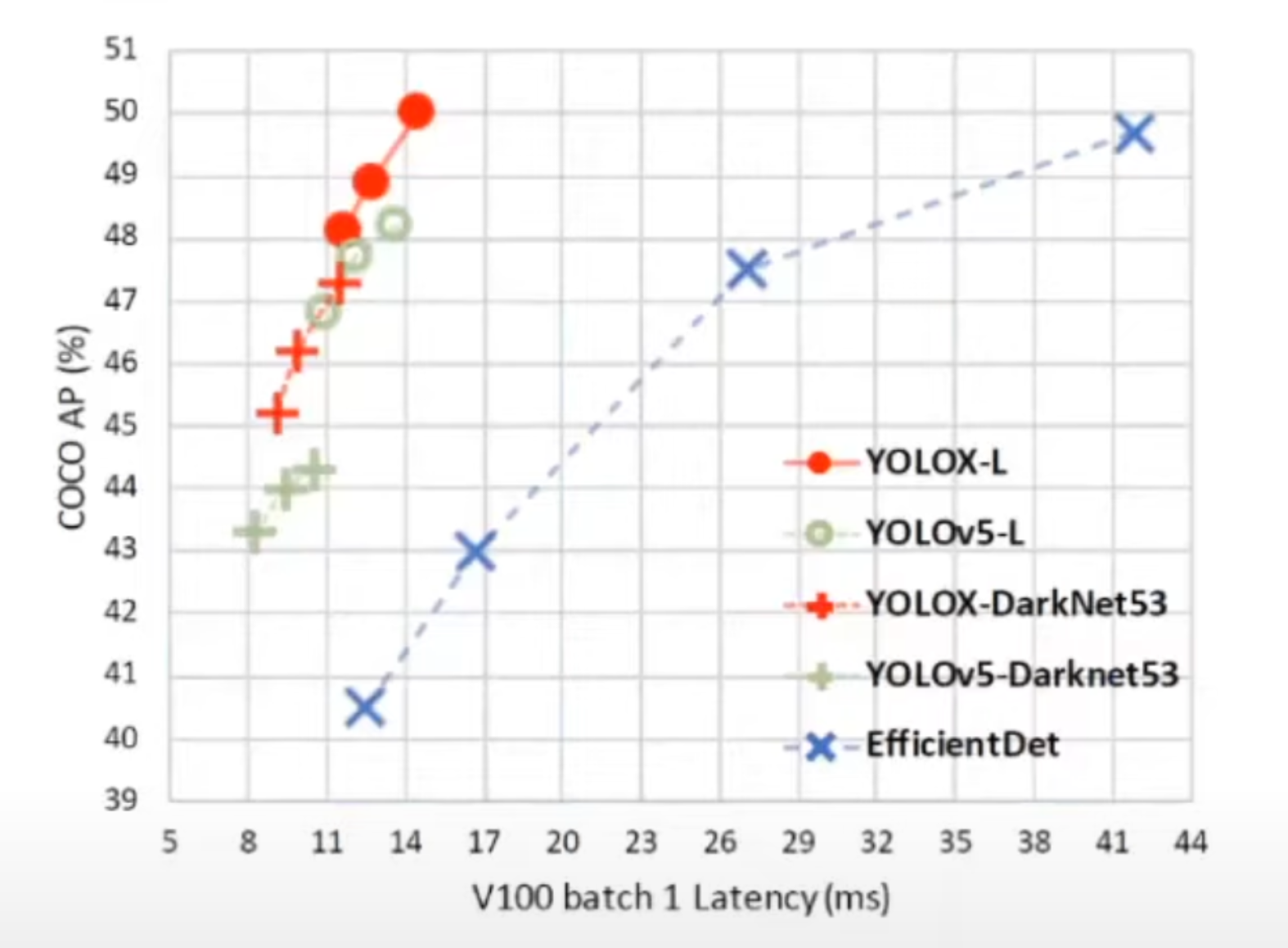
다음으로 YOLOX의 퍼포먼스 부분입니다. 위 그림은 약간 덩치가 큰 모델들에 Anchor free 방법과 다양한 방법들을 사용을 해서 latency 대비 average precision을 제시한 그래프입니다. 초록색으로 표시된 것들이 원래 모델이고, 빨간색이 Anchor free 방법을 적용한 것입니다. 원래 모델보다는 Anchor free를 적용한 것이 average precision이 높게 나타났습니다.
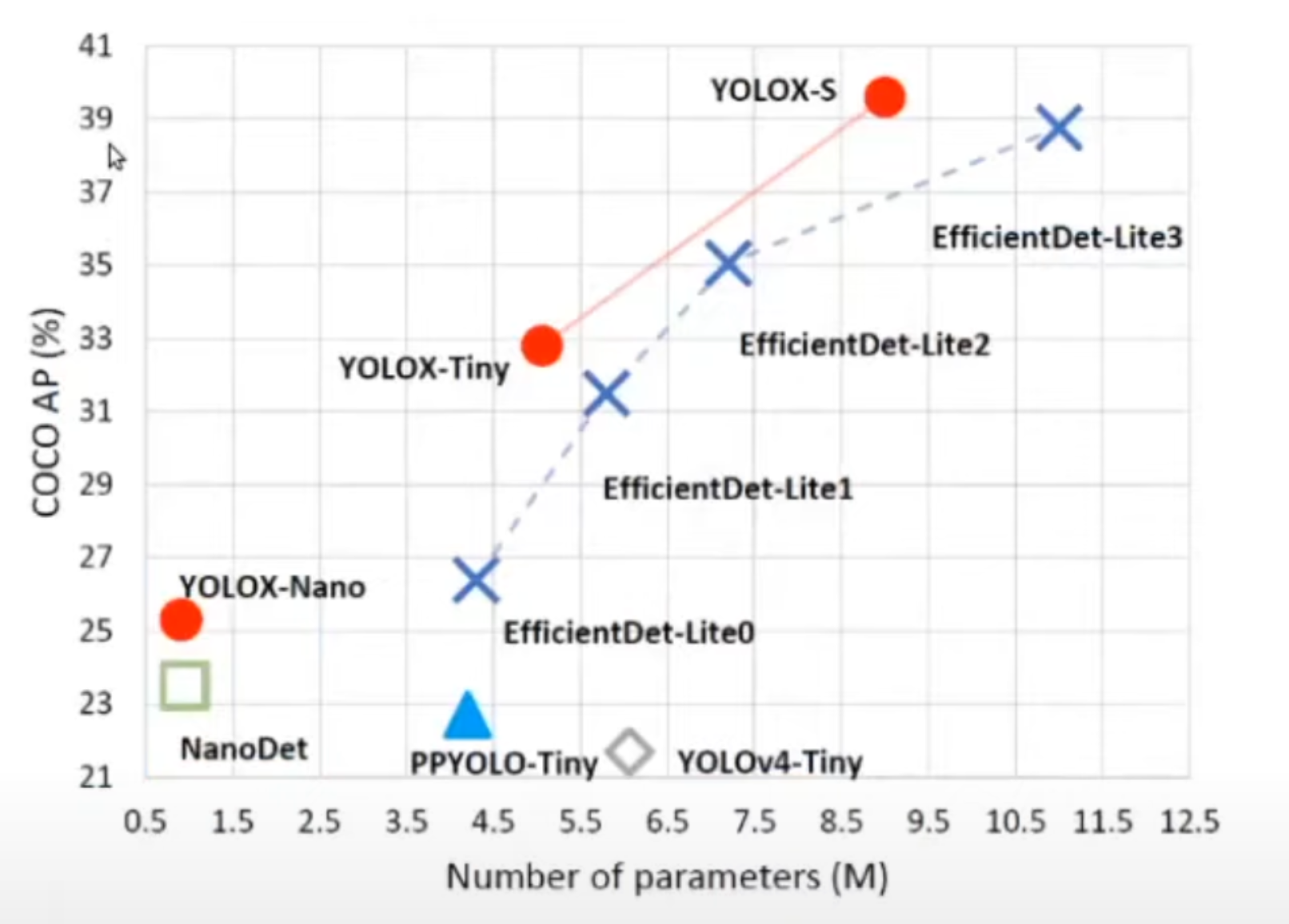
오른쪽 그림은 조금 작은 모델들에 Anchor free 방법을 적용한 그래프이고, 파라미터 대비 average precision을 나타내고 있는데, YOLOV4의 Tiny나 NanoDet 등에 적용해서, 원래 모델의 성능보다는 더 높은 성능을 보여주고 있습니다.

YOLOX의 네트워크 부분을 살펴보겠습니다. 전체적인 네트워크 구조를 나타내 보았습니다. YOLOX는 backbone 네트워크로는 YOLOV3의 spp를 탑재한 backbone 네트워크를 사용을 하였습니다. 그 이후에는 PAFPN이라는 피라미드 네트워크로 연결하고 그다음에 prediction을 진행하는 구조로 되어 있습니다. backbone 네트워크부터 다시 살펴보자면, 앞에서 언급했던 그래프에서는 YOLO V5를 개량한 모델의 그래프를 제시를 하였는데, 여기서는 YOLOV3을 사용을 하고 있습니다. 논문에서는 그 이유를 YOLOV4나 V5는 Anchor base 메서드에 과적합 돼 있어서 Anchor free 메서드를 적용하기 위해서는 V3가 더 적합했기 때문이라고 밝히고 있습니다.
그다음으로는 피쳐 피라미드 네트워크 줄여서 PAFPN이라고 하는 네트워크입니다. FPN는 backbone에서 여러 가지 스케일에 feature map을 뽑아내고 여러 스케일의 feature map에서 prediction을 진행을 해서 멀티 스케일을 고려하는 네트워크입니다. 멀티스케일 feature를 뽑아내고 탑다운까지 진행을 하면서 바로 헤드로 넘어가는데 PAFPN에서는 하나가 더 붙었습니다. 그래서 바텀업 라인도 생기고 최종적으로 위 그림과 같이 세 개에서 각각 프레딕션 헤드가 있어서 프레딕션을 진행하도록 되어 있습니다.
Anchor free의 단점으로 멀티 스케일을 고려하지 못해서 작은 오브젝트 등을 잘 찾기가 힘든 부분이 있는데, 저자는 이런 약점들을 FPN를 통해서 멀티스케일을 고려해서 극복하고자 했습니다.
마지막으로 그림의 우측 부분은 프레딕션을 나타내고 있습니다. FPN의 3개의 아웃풋에서 각각 진행이 되고, 프레딕션은 classification, regression, 그리고 Objectness에 대해서 진행을 합니다. 참고로, Objectness 스코어는 프레딕션이 각각의 Cell에서 이루어지기 때문에, 그 Cell이 백그라운드를 나타내는지 아니면 오브젝트를 어떤 오브젝트 라도 포함하고 있는지, 오브젝트가 있는지 없는지를 0에서 1 사이의 밸류로 나타내는 스코어를 뜻합니다.
저자는 전체적으로 이러한 네트워크 위에 크게 4가지 방법을 가지고 성능 향상을 이끌어냅니다. 이렇게 헤드가 여러 개인 것을 뜻하는 Decoupled head와 데이터 증강인 Data augmentation 그리고 Anchor free Multi positive라는 방법을 적용했습니다. YOLOX 포스팅에서는 이렇게 4가지 항목을 중심으로 설명을 드리겠습니다.
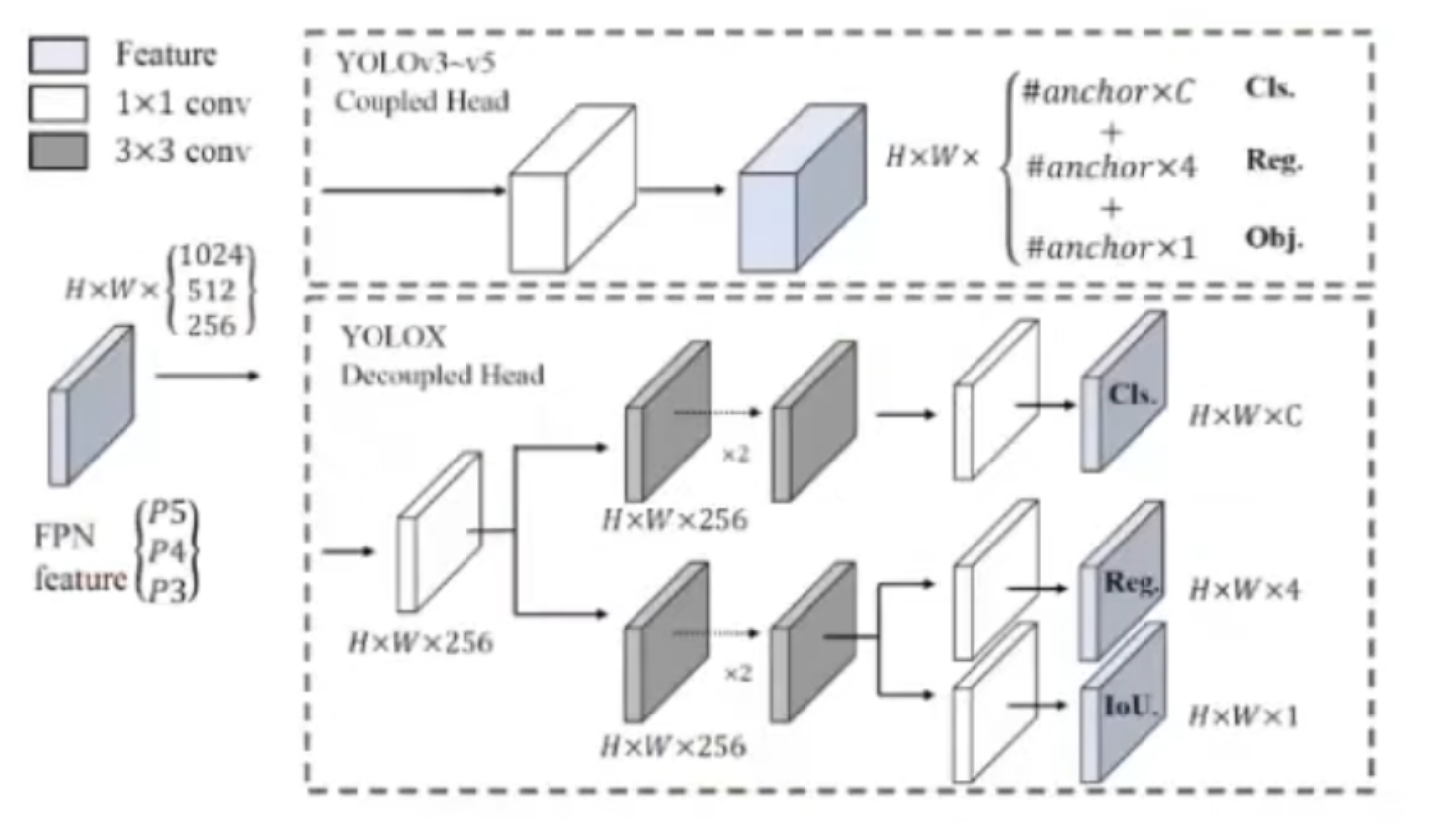
YOLOX에 적용한 기법 중 첫 번째로 Decoupled head가 있습니다. Decoupled head라는 것은 이름처럼 하나의 헤드가 아닌 여러 개 헤드로 나뉜 것을 의미합니다. YOLOV3부터 V5까지는 하나의 헤드만 사용을 했습니다. 즉, regression 파트, classification 파트, 그리고 Objectness파트까지 전부 합쳐서 하나의 벡터로 만들어서 학습을 하고 prediction을 하는 방법을 사용을 했습니다.
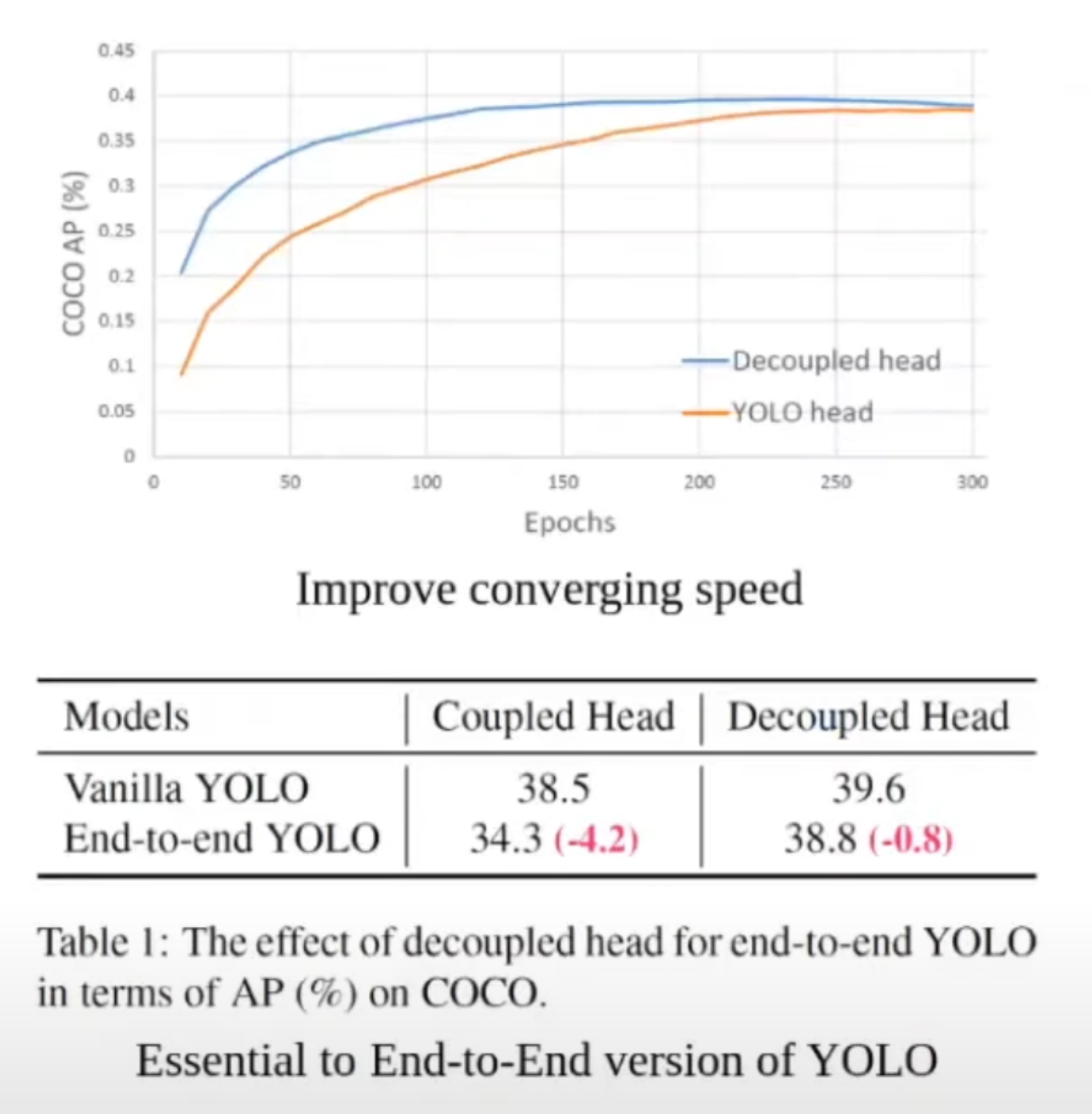
위 그래프를 보시면, Decoupled head와 YOLO head의 epoch당 AP값으로 표현된 학습 속도를 보실 수 있습니다. Decoupled head가 아무래도 조금 더 converging 속도가 빠른 것을 확인하실 수 있습니다. YOLOX에 적용한 기법 두 번째는 end-to-end로 가기 위해서는 Decoupled head가 필수적이라는 측면입니다. 위 그림의 아래 테이블은 기존의 YOLO와 Decoupled head를 사용했을 때와 기존의 YOLO 방식과 end-to-end YOLO 방식을 비교한 테이블입니다. 결과적으로는 end-to-end의 Decoupled head가 조금 더 AP값이 잘 나오는 것을 확인할 수 있습니다.

다음으로는 augmentation 방법입니다. 이 논문에서는 총 4가지의 Data augmentation 방법을 적용을 했습니다. random horizon flip과 원본 영상의 hsl을 변경하여 증강시키는 클러스터라는 방법, 원본 이미지 외에 3개의 추가적인 사진을 섞는 Mosaic이라는 방법, 마지막으로는 그 이미지랑 레이블의 다른 것을 조금씩 섞는 Mixup이라는 방법을 사용했습니다. 오른쪽 그림에서 비행기라는 레이블에 나비라는 레이블을 조금씩 섞어서 임시로 만들고, 레이블도 만든 것을 확인하실 수 있습니다. 놀라운 점 중 한 가지는, 이 논문의 저자는 강력한 Data augmentation을 써서, pre-training 된 weight를 써도 성능 향상이 별로 안 되었다고 합니다. 그래서 논문에서는 스크래치부터 학습을 했다고 언급하고 있습니다.
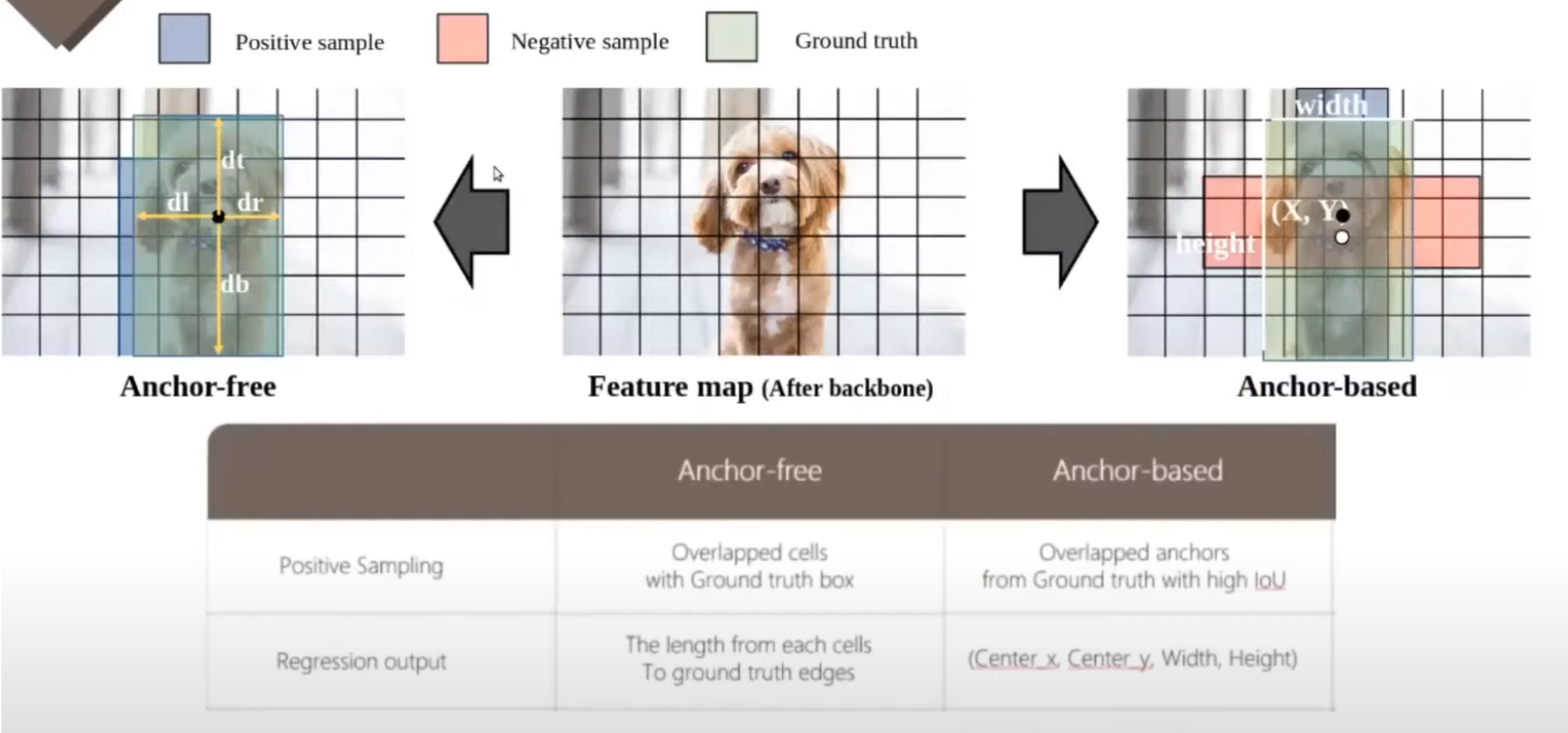
다음으로 Anchor free 기법입니다. 중간 이미지가 그 feature map을 거친 backbone 네트워크를 거친 최종 feature map을 나타냅니다. 좌측이 Anchor free 그리고 우측이 Anchor base 방법을 나타내고 있습니다. Anchor base 방법부터 말씀을 드리자면, 위 그림 좌측의 검은 점이 있는 Cell에서 프레딕션을 진행한다고 가정을 했을 때, Anchor base 방법은 regression을 진행을 하고 regression에서 나오는 아웃풋 값을 바탕으로 Anchor의 중심점과 가로와 세로의 길이를 연산을 해서, 결과적으로는 bounding box에 가로 세로 길이와 중심점을 같은 것을 학습합니다. 여기서 빨간색 박스와 파란색 박스는 각각 Anchor가 만들어낸 bounding box를 의미합니다. 여기서는 아무래도 파란색 박스가 초록색 GT박스와 IoU가 높기 때문에, 이 파란색 bounding box가 Positive 샘플로 분류가 되고 빨간색 박스는 학습에 참여하지 않게 됩니다. 그리고 Anchor free 방법에서는 그라운드 트루스 bounding box 안에 있는 Cell들이 전부 Positive 샘플이 됩니다. 그래서 그중에서도 이렇게 검은 점에서 프레딕션을 진행한다고 했을 때, Anchor free 방법에서는 해당 Cell에서부터 GT의 각 모서리까지 길이를 학습을 하게 됩니다. 그래서 이를 바탕으로 bounding box를 만들어 내고 디텍션 테스크를 수행을 합니다.

다음으로, 위 표는 Anchor free 방법과 Anchor base 방법을 사용했을 때, 결과적으로 장단점을 나타낸 표입니다. 첫 번째로는 Hand-crafted parameter입니다. Anchor는 데이터셋에 따라서 그 사용자가 직접 디자인을 해야 합니다. 데이터셋에서 가로로 긴 것이 많으면, 아무래도 Aspect ratio가 가로가 좀 더 커지는 단점이 있고, 반면에 Anchor free 같은 경우에는 불편함은 없습니다. 두 번째로 Computational cost 같은 경우에는 Anchor는 하나의 Cell에서 9개의 Anchor를 만들어 내고 anchor free는 하나의 프레딕션만 진행을 한다고 했을 때, 단순 계산만으로 9배의 차이가 나는 계산량을 생각해볼 수 있습니다. 그리고 세 번째로는 Generalization인데, Anchor는 데이터셋에 따라서 각자가 디자인하고, 그래서 데이터셋에 조금 디펜던시가 있어서 Generalization 측면에서는 Anchor free가 더 높은 측면이 있습니다. Class imbalanced problem 같은 경우에는 Anchor base는 Cell마다 9개 Anchor를 만들어 내고, 거기에서 나오는 Negative 샘플도 많기 때문에 아무래도 Anchor free 방법이 이런 문제에서는 좀 더 자유롭습니다. accuracy 같은 경우에는 사실이 모델마다 적용된 기법들이 다 달라서 anchor base랑 Anchor free와 따로 정확히 비교를 하긴 힘들겠지만 본 논문에서는 기존의 YOLO V3보다는 Anchor free가 좀 더 우세하다고 볼 수 있습니다. 마지막으로 recall에서 Anchor base는 각 Cell에서 9개를 예측을 하고, Anchor free는 1개만 예측을 하기 때문에, 좀 더 Anchor base가 recall이 높은 것을 확인을 하실 수 있습니다.
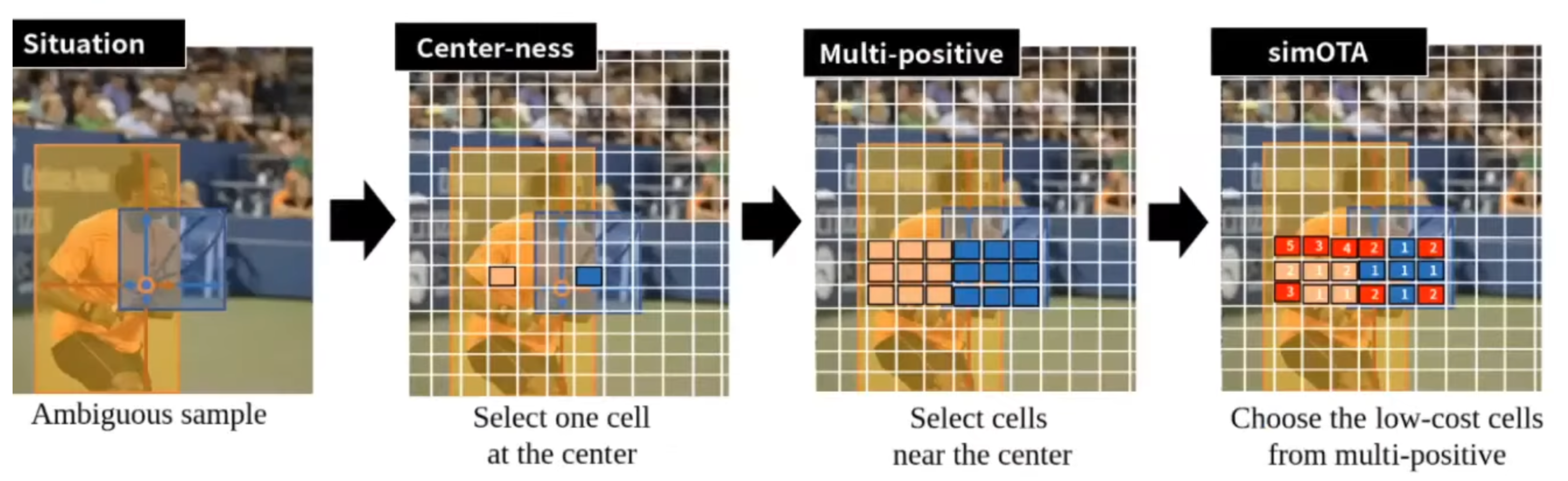
적용한 기법들을 소개하는 것 중에, 마지막으로는 Multi positive 내용이 있습니다. 사실 기본적인 Anchor free의 방법만으로는 Anchor base방식의 accuracy를 따라잡을 수가 없습니다. 그래서 본 논문에서는 accuracy를 향상하기 위해서 다른 방법을 적용을 했습니다. 첫 번째 방법은 CenterYOLOness입니다. 이 방법은 좌측에 사진과 같이 예측하고자 하는 Cell이 있다고 하면, 이 Cell이 오브젝트 레이블이 불분명 한 문제 때문에 디텍션 ratio이 떨어졌다고 해보겠습니다. 각 Cell 중에 원래 Positive가 있는데, 오브젝트에 중심에 해당하는 Cell들만 Positive로 할당하는 CenterYOLOness라는 방법을 사용을 해서 정확도를 더 향상했습니다.
YOLOX의 저자는 가운데에 있는 Cell 말고 옆에 주위에 있는 Cell들도 더 충분히 좋은 prediction을 할 수 있다고 보았고, 그런 관점에서 Multi positive라는 것을 제안을 해서 센터 말고 주위에 있는 Cell들도 다 사용을 해서 prediction을 하자라고 제안을 했습니다.
결론적으로는 저자는 오브젝트 중심에 있으면서도 Loss가 낮은 k개의 샘플을 Positive 샘플로 적용을 해서 프레딕션을 진행하였고 디텍션 퍼포먼스의 향상을 이끌어냈습니다.
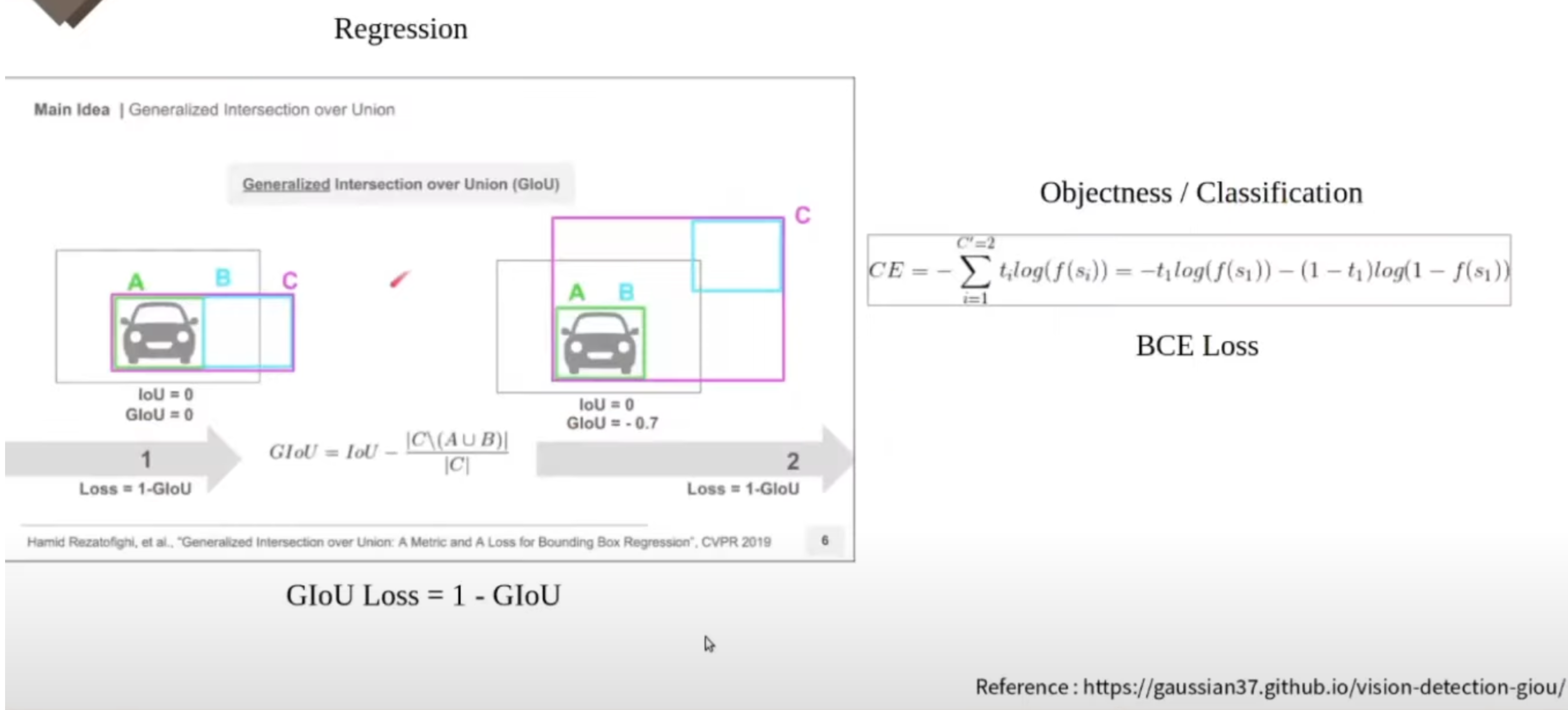
마지막으로는 Loss에 관련된 사항들을 정리를 해 보았습니다. Objectness와 classification과 regression에 대해서 프레딕션을 진행을 한다고 이 글 초반에 말씀을 드렸습니다. Objectness와 classification에 대해서는 BCE Loss를 사용하였습니다. regression에 관해서는 IoU Loss를 사용합니다. 여기서는 초록색이 GT 레이블이고 그리고 민트색이 프레딕션 한 bounding box입니다. IoU를 그대로 Loss에 사용을 하게 되면 좌측과 우측을 그 예측한 정도가 다르게 됩니다. 왼쪽 그림에서 IoU는 둘 다 0입니다. 왜냐하면 겹치는 값이 아무것도 없기 때문입니다. 이런 면들이 IoU를 그대로 Loss에 사용하기에는 좀 부적합하다고 생각을 해서 GIoU가 나왔습니다.
오른쪽 그림에서 그라운드 트루스 박스와 프레딕션 한 bounding box를 모두 포괄하는 C라는 박스를 만들어냅니다. C박스는 이 두 박스가 근접하면 근접할수록 더 작아지게 됩니다. 오른쪽 그림에서 C박스 영역에서 A와 B의 합집합을 뺀 영역을 확인하실 수 있습니다. 그래서 좌측과 우측의 IoU는 모두 0이지만 GIoU는 0이고 오른쪽 GIoU는 0.7이 됩니다.
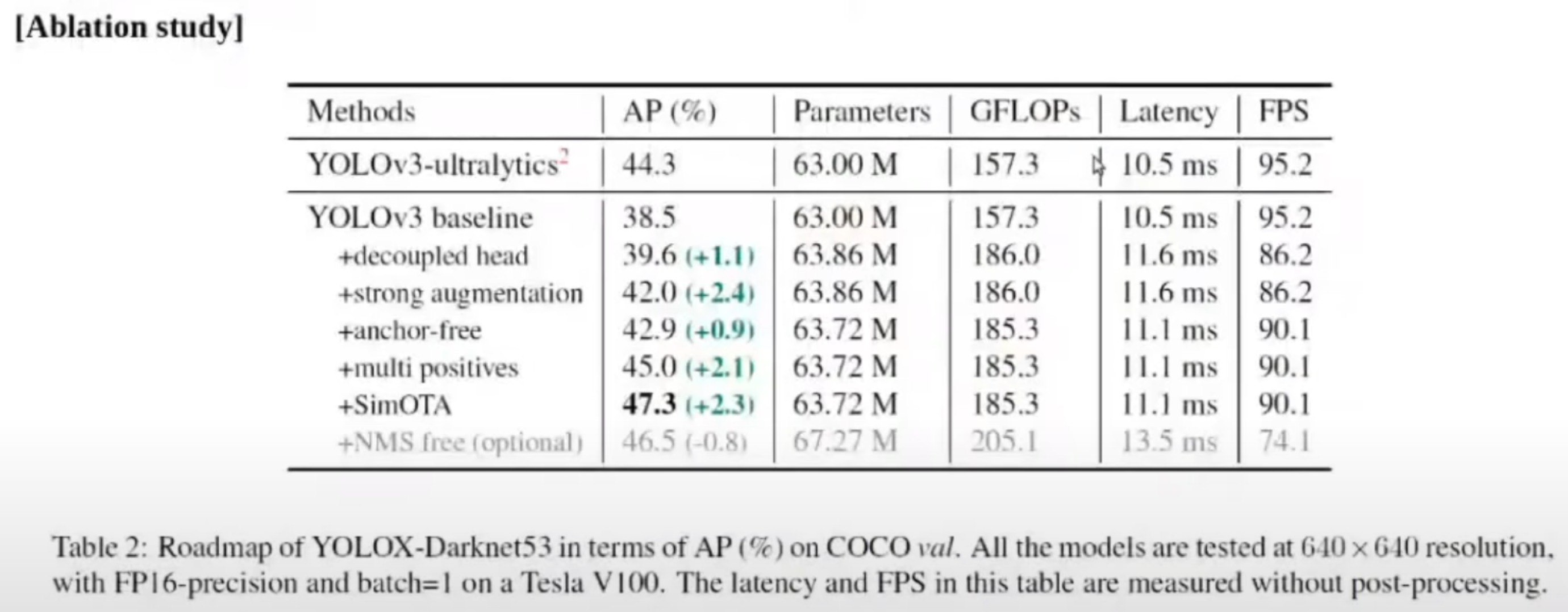
다음으로, Experiment 중 ablation study를 살펴보겠습니다. 위 표를 보시면 YOLO V3 base모델에 비해서, 앞에서 소개한 방법들을 적용하는 것이, 성능 향상에 도움이 되었다는 것이 결론입니다. 추가적으로 Anchor free 방법을 사용했을 때는 strong augmentation까지는 Anchor free방법이 적용이 되어있지 않은 것으로 보이는데, Anchor free를 적용하고 조금 더 속도가 빨라져서 계산량 부분에서 이득이 있었다는 것을 확인할 수 있었습니다. 마지막에 NMS free라는 것은 최종적으로 나온 bounding box 중에 accuracy가 높은 bounding box만 추려내는 post processing 파트입니다. 표를 보시면, Anchor free 네트워크라 해도, post processing을 적용을 하였을 때가 조금 더 AP가 향상되고, 없앤다면 낮아지는 결과를 확인을 하실 수가 있습니다.
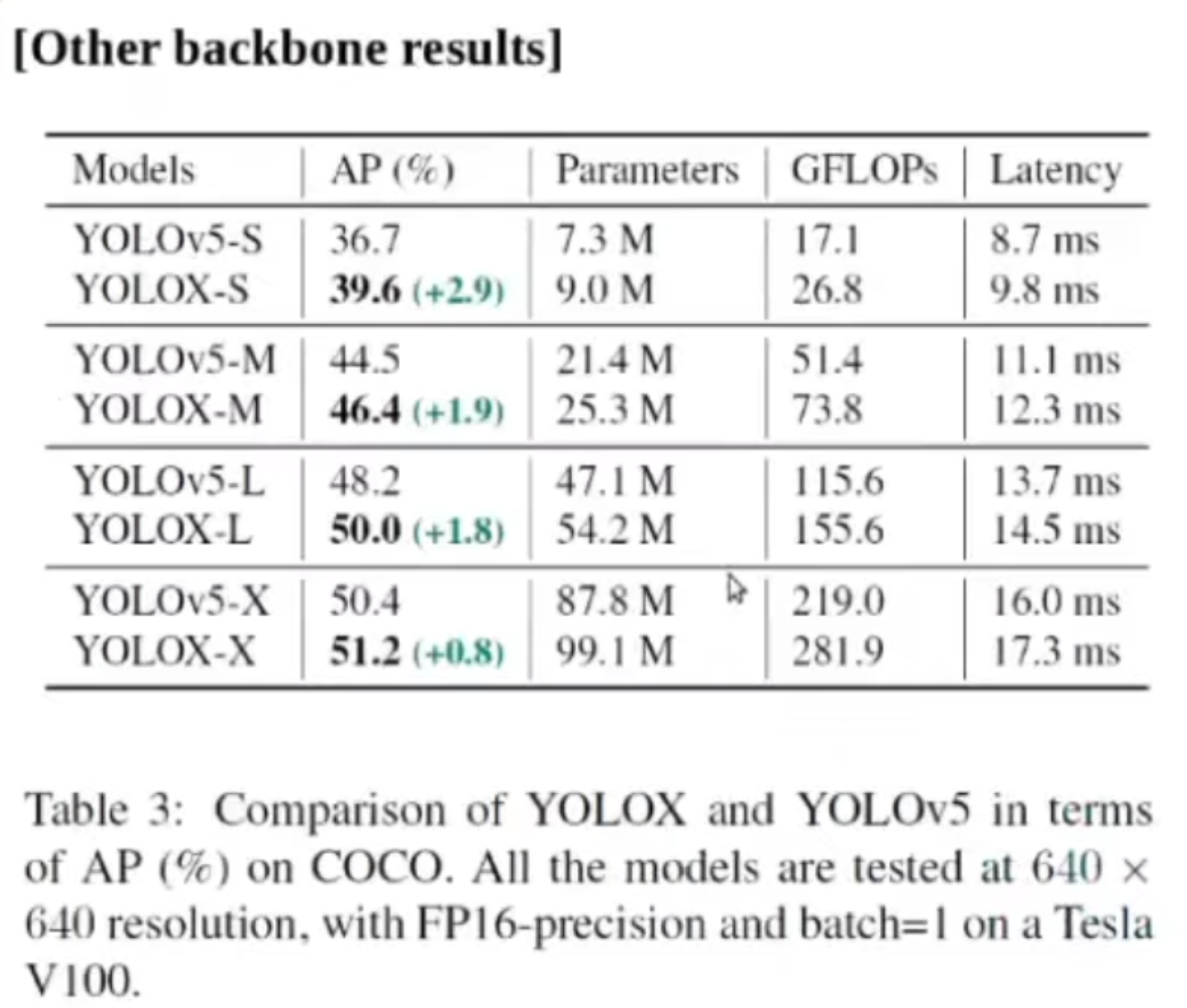
다른 backbone을 적용했을 때의 결과입니다. 이것들은 각각 그 YOLO V5를 base 라인으로 해서, YOLOX에서 제안한 방법들을 적용하였고, 각각 AP이 조금씩 올라가는 것을 확인하실 수 있습니다. 그에 따라서 파라미터도 조금씩 상승을 하고 latency도 조금씩 상승을 하는 trade off가 있지만, AP값은 조금 더 향상된 결과를 보실 수가 있습니다.
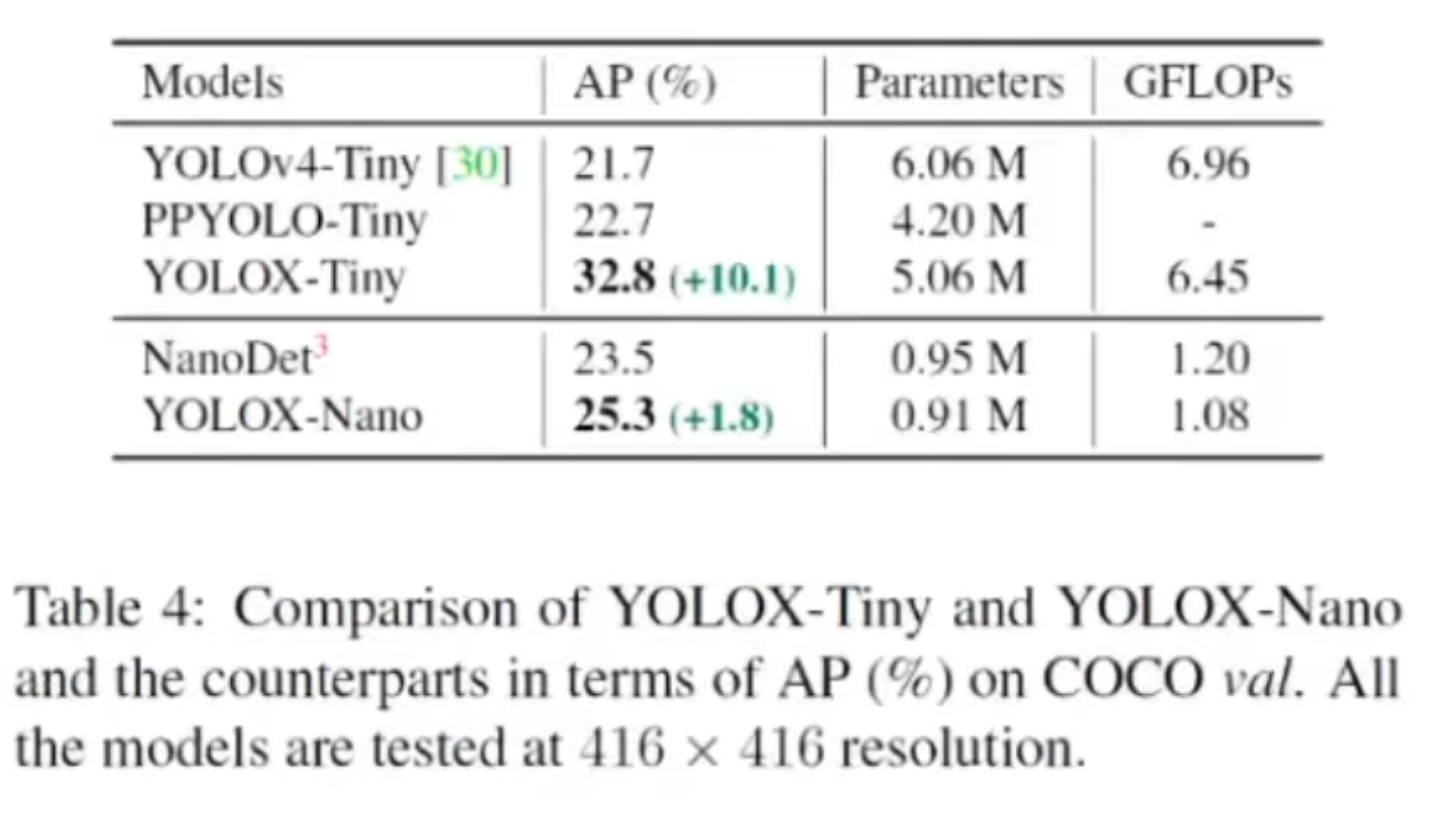
작은 모델들에 대해서 살펴보겠습니다. 각각 AP는 올랐고 파라미터수는 좀 늘었지만 AP값은 조금 더 향상된 결과를 확인할 수 있습니다.
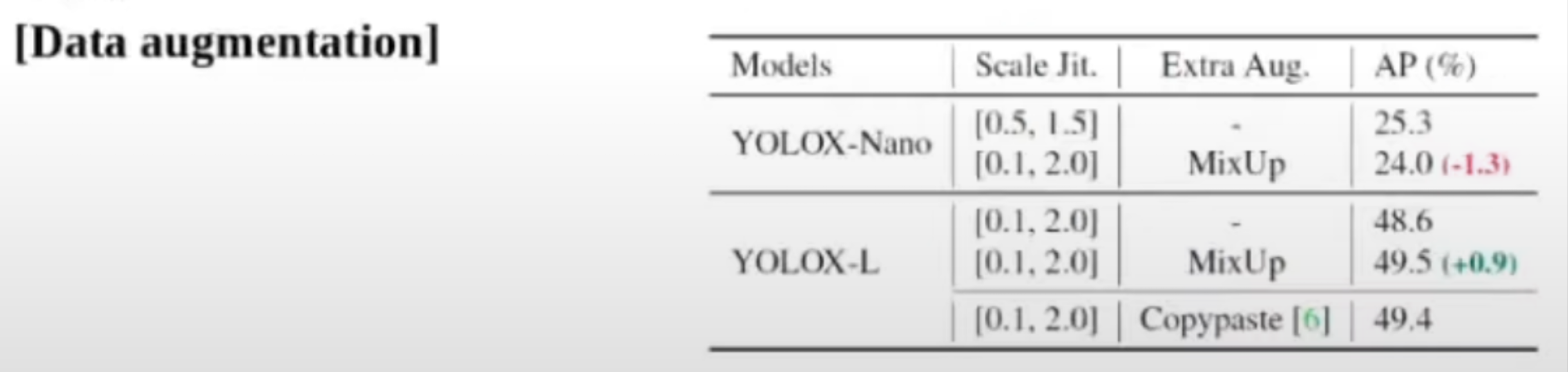
Data augmentation 방식인데, 저자들은 그 모델 사이즈에 따라서 Data augmentation 차등적으로 적용을 해야 된다고 생각을 했습니다. 그래서 실험을 해봤을 때도 작은 모델 같은 경우에는 Mixup 같은 것을 사용했을 때 AP가 더 떨어졌고, 큰 모델 같은 경우는 Mixup을 사용해서 많이 올랐다는 것을 알 수 있습니다. 최종적으로, YOLO V5에 이 논문에서 제시한 방법을 적용한 것이 AP면에서는 가장 좋다는 것을 알 수 있습니다.
마지막으로 정리해보면, 이 논문의 contribution은 Anchor free 방법을 YOLO 시리즈에 적용했다는 점, 그리고 label assigning strategy를 썼다는 점을 들 수 있습니다. 또한, 진보된 디텍션 테크닉과 모델 사이즈에 관계없이 효과적인 방법들을 적용했다는 것이고, 적용한 방법들이 오리지널 모델의 accuracy를 더 향상시켰다는 점 입니다. 지금까지 YOLOX에 대한 포스팅이었습니다. 감사합니다.
'이미지 처리 논문' 카테고리의 다른 글
| 보다 더 정확하게! – Effectively Leveraging Attributes for Visual Similarity (0) | 2022.05.23 |
|---|---|
| Explicit + Implicit Knowledge 활용 - YOLOR : You Only Learn One Representation: Unified Network for Multiple Tasks (0) | 2022.05.23 |
| MobileViT: Light-weight, general-purpose, and Mobile-friendly Vision Transformer (2) | 2022.05.16 |
| Tiny Object Detection! (2) | 2022.05.16 |
| Dense vs Sparse - Sparse R-CNN (0) | 2022.05.16 |




댓글