안녕하세요 콥스랩(COBS LAB) 입니다.
오늘 소개해 드릴 논문은 ‘MobileViT : Light-weight, general-purpose, and Mobile-friendly Vision Transformer’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘MobileViT’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상 링크: https://youtu.be/1vZ2wEsUdZc)

먼저 background입니다. 위 그림은 MCUNet 논문에서 나온 표입니다. MCUNet에서는 AI가 점점 작아지고, 그래서 일반적으로 PC나 서버의 자원을 사용하는 Cloud AI에서 휴대폰 또는 싱글보드 컴퓨터 등을 사용하는 Mobile AI, 심지어 MCU 등 embedded 기기에서 극소량의 메모리만을 가지고 AI task를 수행하는 Tiny AI까지 AI의 규모와 범위가 점점 넓어지고 있다고 설명합니다.
본 논문에서는 Tiny AI까지는 아니고, Mobile 레벨에서 효율적인 아키텍처를 설계했다고 볼 수가 있습니다.

Edge AI는 예측 computing과 AI를 조합한 단어입니다. 이름에서 알 수 있듯이 서버 환경에 비해서 computing Power나 Memory 그리고 Storage에 제약이 있습니다. 반면에 제약에 비해서 도메인에 따라서 다르지만 Real-time inference을 요구하거나 극한 환경에 Robust 한 정확도가 요구됩니다. 대표적으로 자율주행이나 지능형 CCTV 등이 있습니다.

한정된 자원으로 최대한의 성능을 내야 되기 때문에 나온 여러 가지 경량화 방법들입니다. 첫 번째로 모델 자체를 가볍게 설계하는 EfficientNet이나 MobileNet 등이 있습니다. 두 번째는 Knowledge Distillation입니다. Knowledge Distillation을 사용을 해서 좀 더 무겁고 정확도가 높은 모델 말 그대로 지식을 증류하는 방식입니다. 세 번째로는 Model Compression입니다. Quantization이나 Pruning을 통해서 모델을 압축하는 방식입니다. 마지막으로 Dedicated Hardware Design은 Hardware 레벨에서 AI 연산에 최적화된 칩을 설계합니다.
본 논문은 4가지 방식 중에 첫 번째(Model Design)에 속합니다.

CNN과 ViT의 장점만을 살려서 mobile vision task에 적합한 가볍고 latency가 낮은 모델을 설계하는 것이 가능한지에 대한 질문입니다. 결과적으로 Mobile ViT와 CNN이나 ViT만을 기반으로 한 네트워크보다 좋은 성능을 달성을 했고 단 600만 개의 파라미터만을 가지고 ImageNet에서 78.4%의 정확도를 달성한 것을 확인할 수 있습니다.

CNN의 장단점입니다. CNN은 Spatial inductive bias가 있어서 학습하기가 쉽고 가볍고 빠르다는 장점과 data Augmentation에 덜 민감하다는 것이 장점입니다.
단점으로는 receptive field가 Local 하기 때문에 전반적인 global context를 포착하지 못한다는 단점이 있습니다.

ViT의 장단점입니다. CNN의 단점을 극복한 것이 ViT라고 할 수 있습니다. self attention을 통해서 모든 장거리 의존관계를 포착할 수가 있습니다. 그리고 대부분의 SOTA 모델들이 ViT 기반이기 때문에 정확도가 높다는 것이 장점입니다.
단점은 parameters가 굉장히 무겁습니다. parameters가 동일한 제약 조건하에서 DelT라고 하는 ViT 모델이 MobileNetV3보다 정확도가 떨어집니다. 그리고 computation이 굉장히 비싸고 느려서 실무에서 사용하기 힘들다는 단점이 있습니다. 그리고 data augmentation and regularization에 민감하다는 단점이 있습니다.

Related work입니다. Light-weight CNN는 MobileNet이나 MNASNet 등등이 있습니다. Transformer는 ViT를 시작으로 Convolution 하고 ViT를 조합하려는 시도들인 ViT-C나 CvT, PiT 등등이 있습니다.

논문에서 제안한 Mobile ViT의 세 가지의 설계 목표입니다.
- Better Performance - 같은 Parameter 수 하에서 더 좋은 성능을 달성하는 것이 목표입니다.
- Generalization Capability - 일반화 능력입니다. 단순히 가지고 있는 트레이닝 데이터에 대해서 좋은 성능을 달성하는 것뿐만 아니라 한 번도 보지 않은 데이터셋에 대해서도 좋은 성능을 달성하는 것이 목표입니다.
- Robust - hyperparameters에 대한 민감성을 줄이고 insensitive, robust 하게 만드는 것이 목표입니다.
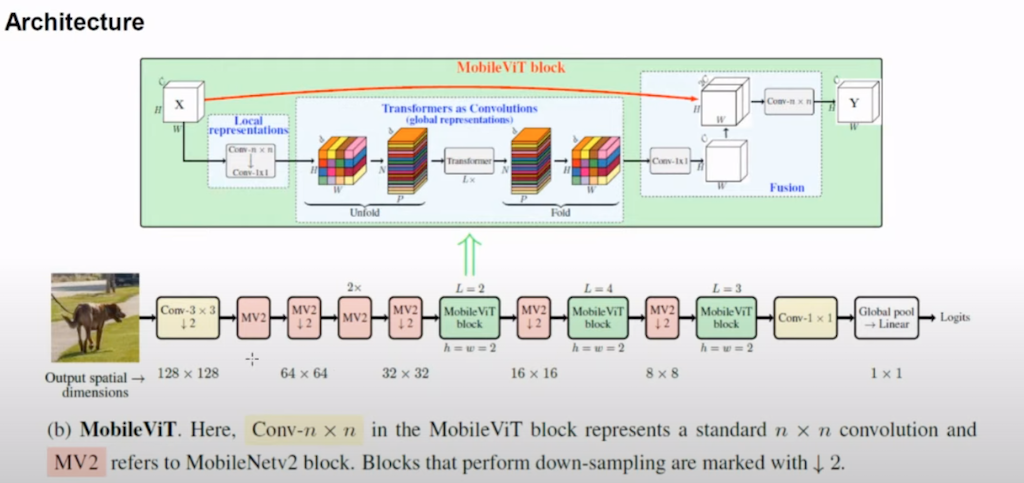
Architecture를 설명드리겠습니다. 논문에서 구체적으로 제안한 것은 Mobile ViT라는 전체 Architecture 중에 Mobile ViT block이 있습니다. Mobile ViT block이 단 세 개만 들어가게 되고 나머지는 MobileNet 2에서 제안한 block 또는 Mobile block이 down-sampling 연산을 대부분 담당하고 있습니다.
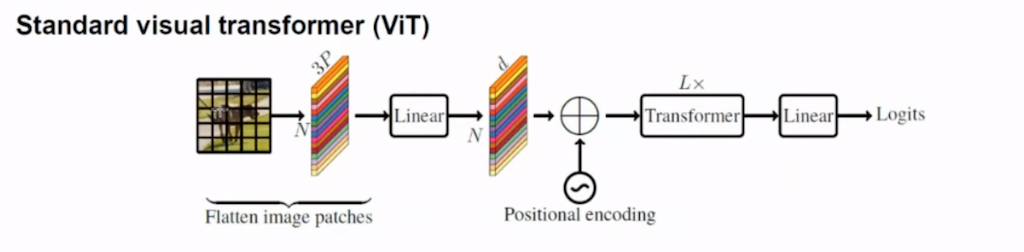
ViT입니다. ViT는 image parches를 전부 Flatten 한 다음에 사전에 정의된 hidden dimension에 맞게 Linear Projection을 수행하고 Positional encoding을 더해서 Transformer 연산을 적용합니다.
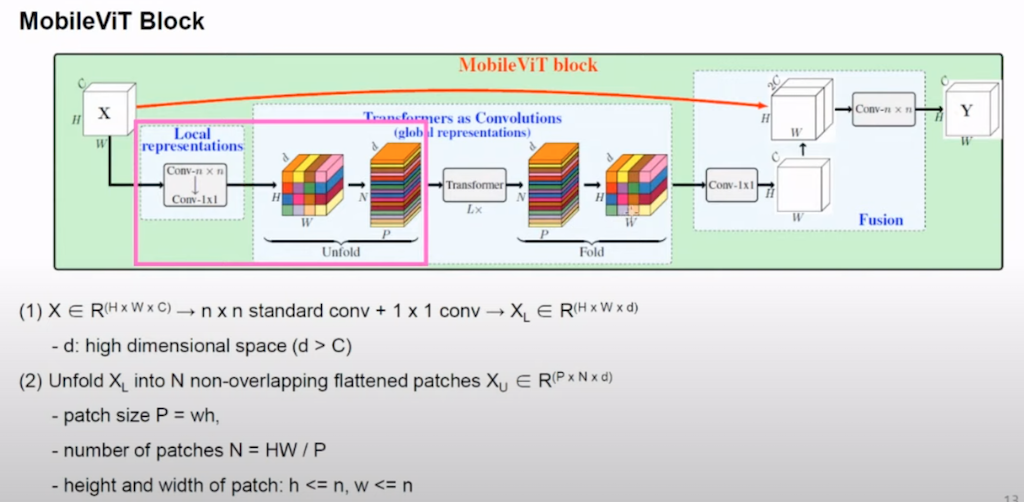
Mobile ViT block을 단계적으로 설명을 드리겠습니다. H x W x C의 tensor에 대해 kernel 사이즈 n x n에 conv을 적용을 하고 다시 1 x 1 conv 적용을 해서 원하는 크기의 d dimension의 H x W x d를 얻습니다. 다음에 tensor를 N x P x d의 tensor로 reshape 합니다. 여기서 P는 patch size를 말하고 N는 patch size에 따라서 자연스럽게 결정되는 patch의 개수를 의미합니다. 얻어진 tensor에 대해서 Transformer 연산을 수행을 하고 원래 입력이 되었던 H x W x d의 tensor로 reshape 합니다. 이 과정에서 patch의 순서나 pixel의 공간적 순서가 바뀌지 않기 때문에 Positional encoding이 별도로 필요하지 않은 것이 한 가지 장점입니다. 마지막으로 1 x 1 conv를 적용을 해서 처음에 shape였던 H x W x C의 텐서를 얻고 H x W x C 텐서와 concat을 해서 다시 한번 n x n conv를 적용을 해서 H x W x C의 텐서를 얻어내는 것으로 Mobile ViT block이 완료됩니다.

위 그림은 CNN과 Transformer를 조합을 해서 CNN의 단점인 local receptive field가 아닌 global computation을 좀 더 가볍게 수행한다는 것을 나타냈습니다. 파란색 Pixel는 주변 Pixel의 정보를 conv를 통해서 encoding 하는 것이고 encoding 된 정보에 대해서 self attention을 수행함으로써 빨간색 Pixel이 주변에 encoding 된 정보 간의 관계를 포착하고 결과적으로 모든 Pixel에 대해서 관계를 개선한다고 설명합니다.
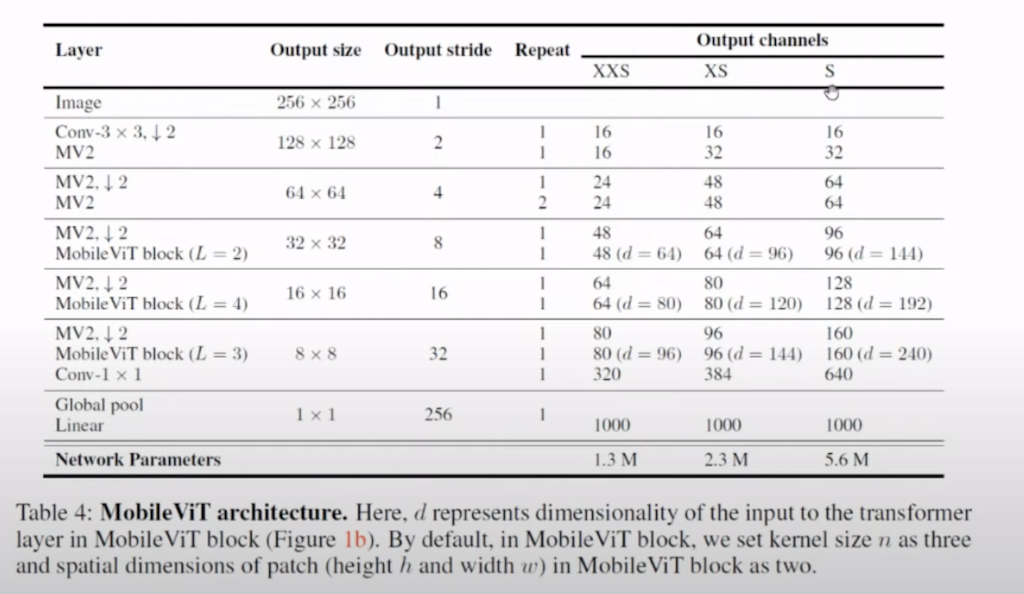
Architecture입니다. Output size가 256 x 256에서 1 x 1R까지 점점 내려가는 걸 볼 수가 있습니다. 논문에서 제안한 것은 S모델 , XS 모델, XXS모델이 있습니다. 세 가지 모델은 채널 수가 다르다는 것으로 분류했습니다. 그래서 parameter 수가 1.3M에서 5.6M으로 굉장히 적은 것을 확인할 수 있습니다.

CNN과 비교한 표입니다. 동일한 parameter 하에서 accuracy가 높게 나온 것을 확인할 수 있습니다. 또한 애초에 가볍게 설계된 MobileNet 같은 모델에 비해서도 accuracy가 훨씬 더 높았고 heavy 한 모델에 대해서도 좀 더 나은 성능이 나왔습니다.

ViT 기반 모델과 비교한 표입니다. DeIT나 ViT, Pit 등등 고도의 augmentation을 쓴 모델에 비해서 Mobile ViT가 단순한 augmentation을 썼음에도 훨씬 적은 parameter로 높은 성능을 달성한 것을 확인할 수 있습니다.

Hyperparameter settings에 대해서 나열한 것입니다. Multi-scale sampling을 통해서 image의 sacle를 바꿔가면서 트레이닝을 진행을 했습니다. 그리고 굉장히 간단하게 Random resized cropping, Horizontal flipping만을 적용한 것을 확인할 수 있습니다.
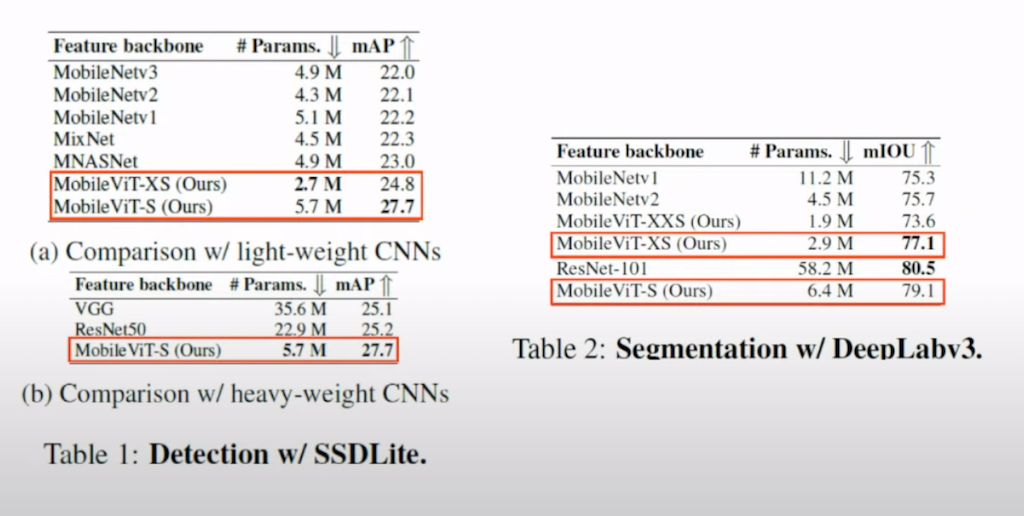
논문에서 목표로 했던 설계 목표 중의 하나인 Generalization probability입니다. Mobile ViT라는 모델이 단순히 classification에만 성능을 발휘하는 것이 아니라 detection이나 segmentation에 대해서도 backbone으로 사용됐을 때 좋은 성능을 발휘하는 것을 목표로 했습니다. 그래서 실험 결과 detection과 segmentation에 대해서도 뛰어난 성능을 달성한 것을 확인할 수 있었습니다.

실제 device에서 latency를 측정했습니다. MobileNet2에 비해서는 확실히 느리지만 DeIT나 Pit 등 ViT기반 모델에 비해서는 좀 더 빠른 latency를 보여준 것을 확인할 수 있습니다.
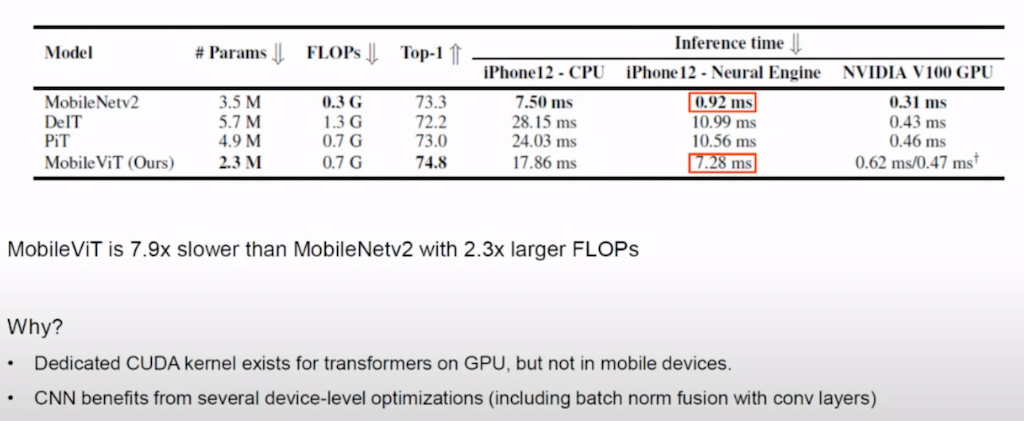
MobileNet2에 비해 느린 이유입니다. device는 iPhone12- CPU, iPhone12-Neural Engine, NVIDIA GPU에 대해서 테스트했습니다. Transformer 연산에서 일반적인 NVIDIA GPU에서는 CUDA kernel이 최적화되어 있지만 Mobile device 같은 경우에는 그렇지 않아서 MobileNet 2 하고 차이가 난다라고 설명하고 있습니다. 그리고 CNN는 워낙 오래된 연산이기 때문에 device 레벨에서 굉장히 최적화가 잘 돼 있어서 batch norm과 fusion 연산을 해서 따로 계산할 필요 없이 굉장히 최적화가 잘 돼 있다고 설명하고 있습니다.
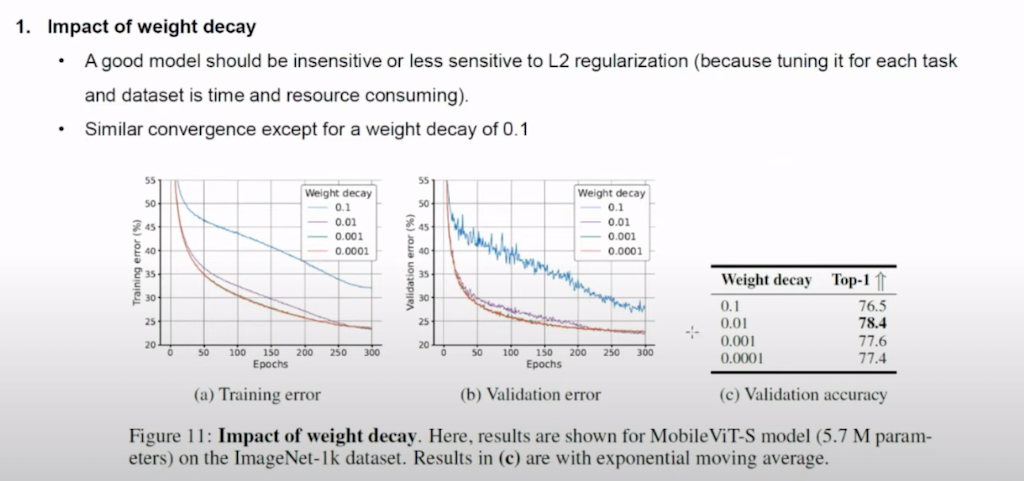
Ablation study에 대해서 설명드리겠습니다. weight decay를 다르게 수행한 결과입니다. 0.1인 경우를 제외하고 다른 경우에 비슷한 conv를 보여주고 있습니다.
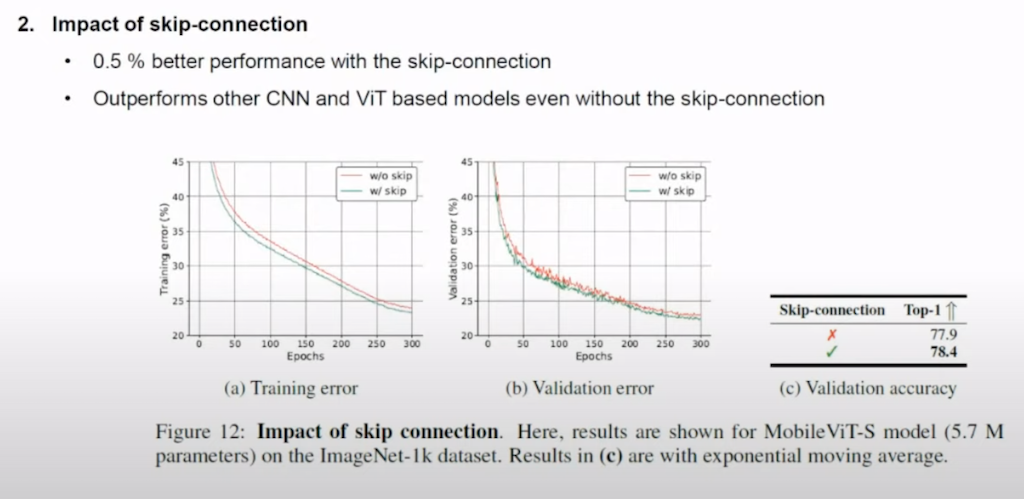
skip-connection의 영향입니다. skip-connection을 했을 때가 하지 않았을 때보다 0.5% 더 성능이 높았고 skip-connection을 쓰지 않은 경우에도 CNN과 ViT보다 성능이 더 좋은 것을 확인할 수 있습니다.
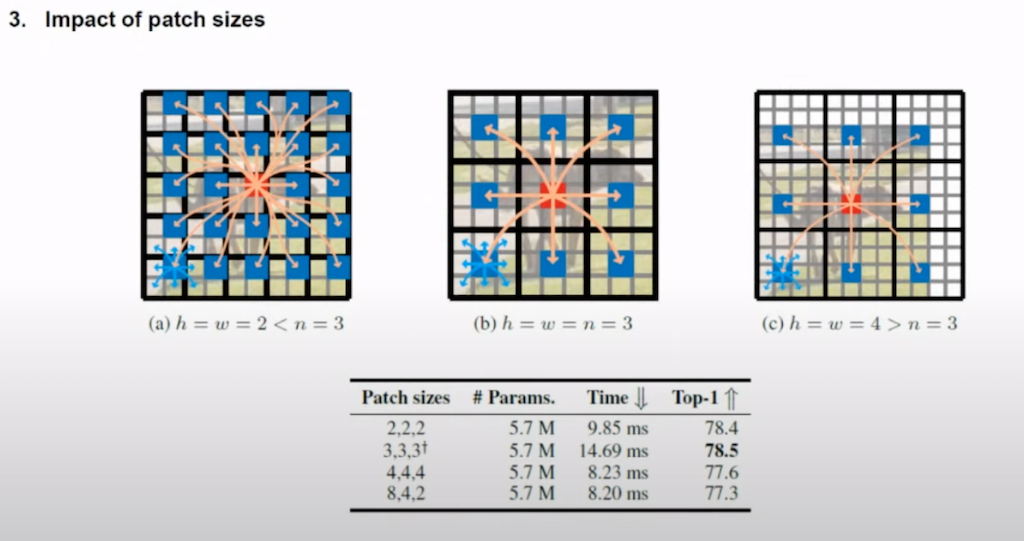
다음으로는 patch size의 영향입니다. patch size를 다르게 했을 때 모든 pixel의 정보를 encoding 할 수 없었기 때문에 3, 3, 3으로 했을 때 가장 성능이 좋은 것을 확인할 수 있습니다.

마지막으로 label-smoothing과 EMA를 적용한 결과입니다. label smoothing을 적용하면 3% 향상, 그리고 EMA까지 적용을 하면 +0.1%가 향상된 것을 확인할 수 있습니다.

결론입니다. Mobile ViT는 결국에 CNN과 ViT를 조합을 함으로써 좀 더 적은 수의 연산으로 global information을 포착하는 모델이라고 볼 수 있습니다. Mobile ViT 보다는 확실히 느리긴 하지만 높은 정확도를 달성을 하고 다른 ViT 기반 모델에 비해서는 정확도랑 속도 측면에서 더 나은 것을 확인할 수 있었습니다.
'이미지 처리 논문' 카테고리의 다른 글
| Explicit + Implicit Knowledge 활용 - YOLOR : You Only Learn One Representation: Unified Network for Multiple Tasks (0) | 2022.05.23 |
|---|---|
| 진보된 detection technique- YOLOX (0) | 2022.05.18 |
| Tiny Object Detection! (2) | 2022.05.16 |
| Dense vs Sparse - Sparse R-CNN (0) | 2022.05.16 |
| Pose Estimation논문! Transfer Learning for Pose Estimation of Illustrated Characters (0) | 2022.05.16 |




댓글