

우리나라 포함, 대기업들이 초거대 AI 기술을 공개함과 동시에 폐쇄적으로 변해가는 느낌이 있었습니다. 몇 년 전만 하더라도 많은 비용을 투자한 모델이라도 오픈소스 문화를 위해 사전 학습된 모델을 공개를 했지만, 몇몇 모델들은 비용을 지불하고 사용하는 모습으로 바뀌어 가고 있었습니다. GPT 버전만 하더라도, GPT-3부터는 작은 스타트업은 서비스를 위한 fine tuning을 하기 위해서는 지속적으로 비용을 내는 구조로 다가갈 수밖에 없었습니다.
그러나 우리의 Face book은 Chat GPT( GPT 3.5 기반)로 많은 주목을 받는 Open AI를 비웃듯 오픈 소스 커뮤니티를 위해 GPT3보다 뛰어난 성능을 보이는 LLAMA를 공개하였습니다. 콥스랩 에서는 해당 논문을 발 빠르게 리뷰해 보겠습니다.
Meta는 Open Science 문화를 실천하기 위해, 인공지능의 분야 중 하나인 대규모 언어 모델에 대한 연구를 진전시키기 위해 최첨단의 기반 언어 모델인 LLaMA(Large Language Model Meta AI)를 공개적으로 공개하게 되었습니다.
LLaMA와 같은 더 작고 성능이 뛰어난 모델은 대규모 인프라에 액세스할 수 없는 연구 커뮤니티에서 이 분야의 모델을 연구하도록 돕는 데 도움이 됩니다.
GPT-3와 동등한 성능에 비해 LLaMA와 같이 더 작은 기반 모델을 교육하는 것은 새로운 방법을 시험하고 다른 사람들의 작업을 검증하며 새로운 사용 사례를 탐색하는 데 필요한 컴퓨팅 파워와 리소스가 훨씬 적게 들기 때문에 대규모 언어 모델을 사용하는 환경에서 매우 적합합니다.
그렇기에 Finetuning에도 매우 큰 이점을 가집니다.
지난 1년간 수백억 개의 매개변수를 가진 대규모 언어 모델들은 창의적인 텍스트 생성, 수학적 정리 해결, 단백질 구조 예측, 독해 질문에 대한 대답 등의 새로운 능력을 보여주었습니다.
그러나 대규모 언어 모델에 대한 완전한 연구 액세스는 이러한 모델을 교육하고 실행하는 데 필요한 리소스 때문에 여전히 제한적입니다.
이러한 제한된 액세스는 이러한 대규모 언어 모델이 작동하는 방식을 이해하는 데 연구자들의 능력을 제한하여, 편견, 독성 및 오해 정보 생성과 같은 알려진 문제를 완화하고 이러한 모델의 견고성을 개선하기 위한 노력의 진전을 방해합니다.
LLaMA와 같은 더 작은 모델은 교육 및 미세 조정하기 쉬운 토큰(token)으로 교육됨으로써 특정 제품 사용 사례에 대한 더 민첩한 적용이 가능합니다.


LLaMA 모델은 대부분의 벤치마크에서 GPT-3보다 우수한 성능을 보인다
이 논문은 대규모 언어 모델(Large Language Models, LLMs)에 대한 연구입니다.
LLMs는 대량의 텍스트 데이터를 학습하여, 새로운 작업을 수행하는 능력을 보였습니다.
이 논문에서는, 작은 모델을 더 많은 데이터로 학습시키는 것이,
큰 모델을 더 많은 파라미터로 학습시키는 것보다 성능이 더 좋을 수 있음을 보여주고 있습니다.
또한, 이 연구에서는 서비스를 위해 고려해야 할 모델 추론(inference) 메모리 양이 매우 중요한 것임을 강조하며, 특정 수준의 성능을 얻기 위해 큰 모델을 학습하는 것이 학습에 시간은 덜 걸릴 수 있지만,
보다 작은 모델을 더 오랫동안 학습시키는 것이 inference에서 더 유리함을 보여주고 있습니다.
논문의 목적은 보다 적은 비용으로 대규모 언어 모델을 학습시켜 성능을 개선하는 것입니다. 이를 위해 LLaMA라는 모델을 제안하며, 이 모델은 7B부터 65B 파라미터까지 다양한 크기의 모델로 구성되어 있습니다. LLaMA 모델은 대부분의 벤치마크에서 GPT-3보다 우수한 성능을 보이며, 단일 GPU에서 실행될 수 있어 LLM의 연구와 접근성을 높일 수 있다는 장점이 있습니다.
이 연구는 transformer 아키텍처(Vaswani et al., 2017)와 학습 방법에 대한 개요를 제시하고, 다른 LLM과의 성능 비교 결과를 보고합니다. 또한 최근에 나온 책임 있는 AI 커뮤니티의 벤치마크 중 일부를 사용하여 모델에 인코딩된 편향성과 독성을 노출시키고 있습니다. 이 논문은 대규모 언어 모델의 연구와 개발에 대한 중요한 기여뿐만 아니라, LLM의 책임 있는 사용에 대한 논의를 이끌어내는 데에도 큰 역할을 할 것으로 기대됩니다.
역시 갓 transformer입니다..

논문의 Train 접근 방법은 이전 연구 (Brown et al., 2020; Chowdhery et al., 2022)에서 소개된 방법과 유사하며, Chinchilla scaling laws (Hoffmann et al., 2022)에서 레퍼런스를 했다고 합니다.
논문은 일반적인 옵티마이저를 사용하여 많은 양의 텍스트 데이터에서 대규모 트랜스포머를 학습했습니다.
논문의 데이터 셋은 다양한 도메인을 다루는 몇 가지 데이터를 혼합해서 구성하였습니다. 이전 대규모 언어 모델(LLMs)을 교육하는 데 사용된 데이터 소스를 재사용하면서 공개적으로 사용 가능하고 공개 소스와 호환되는 데이터만 사용하는 제한 조건이 있습니다.
하지만! 해당 논문은 사용한 데이터셋과 비율, 그리고 전처리 방법까지 함께 공유합니다.
해당 데이터의 비율 또한 함께 공유합니다.

English Common Crawl 67% 사용
2017년부터 2020년까지 범위에 걸쳐 다섯 개의 CommonCrawl 덤프를 CCNet 파이프라인 (Wenzek et al., 2020)으로 전처리합니다.
이 프로세스는 데이터를 줄 수준에서 중복 처리를 하고, fastText(face book의 fastText 사랑!) 선형 분류기를 사용하여 영어가 아닌 페이지를 제거하기 위한 언어 식별을 수행하고 ngram 언어 모델을 사용하여 저품질 콘텐츠를 필터링합니다.
게다가 논문은 Wikipedia의 참조로 사용된 페이지를 분류하는 선형 모델을 교육하고 무작위로 샘플링된 페이지와 구분되지 않은 페이지를 제거하는 작업을 했습니다.
C4 15% 사용
탐색적 실험 중에 다양한 전처리된 CommonCrawl 데이터 세트를 사용하면 성능이 향상된다는 것을 관찰했습니다.
따라서 논문은 데이터에 공개적으로 사용 가능한 C4 데이터 세트 (Raffel et al., 2020)를 포함시켰습니다. C4의 전처리에는 중복 제거 및 언어 식별 단계가 포함됩니다.
CCNet과 가장 큰 차이점은 구두점의 존재나 웹 페이지의 단어 및 문장 수와 같은 휴리스틱을 주로 사용하는 품질 필터링을 진행했습니다.
Github [4.5%]
Google BigQuery에서 사용 가능한 공개적인 GitHub 데이터 세트를 사용합니다. Apache, BSD, 및 MIT 라이선스로 배포된 프로젝트만 보존합니다. 또한, 줄 길이나 알파벳 문자의 비율 등의 휴리스틱을 사용하여 저품질 파일을 필터링하고, 정규 표현식을 사용하여 헤더와 같은 보일러 플레이트를 제거합니다. 마지막으로, 정확한 일치로 파일 수준에서 중복 데이터 세트를 제거합니다.
Wikipedia [4.5%]
2022년 6월부터 8월까지 20개 언어 (bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk)에서 위키피디아 덤프를 추가합니다. 데이터를 처리하여 하이퍼링크, 주석 및 다른 포맷 보일러 플레이트를 제거합니다.
Gutenberg 및 Books3 [4.5%]
퍼블릭 도메인에서 출판된 책을 포함한 Gutenberg Project와 대규모 언어 모델 교육을 위한 공개적으로 사용 가능한 데이터 세트인 ThePile의 Books3 섹션을 포함합니다. 책 수준에서 중복 데이터를 제거하고, 90% 이상의 콘텐츠 중복이 있는 책을 제거합니다.
ArXiv [2.5%]
과학적 데이터를 데이터 세트에 추가하기 위해 arXiv Latex 파일을 처리합니다. Lewkowycz et al. (2022)를 따라 첫 번째 섹션 이전의 모든 항목과 참고 문헌을 제거합니다. 또한, .tex 파일에서 사용자가 작성한 인라인 확장 정의 및 매크로를 제거하여 논문 간 일관성을 높입니다.
Transformer의 대규모 구조를 사용 했고, 논문은 PaLM과 같은 다른 모델에서 사용된 여러 가지 개선점을 활용하였습니다.
해당 파트에서는 기존의 아키텍처와의 주요 차이점에 대해 기술 하고,
이러한 변경에 대한 영감을 받은 곳은 괄호안에 표시하였습니다.
Pre-normalization [GPT3].
각 transformer sub-layer의 입력을 정규화하여 출력을 정규화하는 대신에, 훈련 안정성을 개선하기 위해 논문은 입력을 정규화 하였습니다.
Zhang and Sennrich (2019)에 의해 도입된 RMSNorm 정규화 함수를 사용했습니다.
SwiGLU 활성화 함수 [PaLM]
성능을 개선하기 위해 ReLU non-linearity 대신 SwiGLU 활성화 함수를 도입한다. 논문은 PaLM과 달리 4d 대신 2^34d의 차원을 사용하였습니다.
Rotary Embeddings [GPTNeo].
절대 위치 임베딩을 제거하고 대신 Su et al. (2021)에 의해 도입된 회전 위치 임베딩(RoPE)을 네트워크의 각 레이어에 추가하였습니다.
옵티마이저
논문은 AdamW 옵티마이저(Loshchilov and Hutter, 2017)를 사용하여 학습 하였습니다.
하이퍼 파라미터는 다음과 같이 설정 했다고 합니다.
β1 = 0.9, β2 = 0.95.
우리는 코사인 학습률 스케줄을 사용하며, 최종 학습률은 최대 학습률의 10%와 같다. 가중치 감쇠는 0.1이고, 기울기 클리핑은 1.0으로 설정했다고 합니다.
약 2,000개의 웜업 단계를 사용하며 모델의 크기에 따라 학습률과 배치 크기를 다르게 사용하였습니다.(하단 표 참고).


효율적인 학습 을 위해..
모델의 훈련 속도를 높이기 위해 몇 가지 최적화를 적용하였습니다.
먼저, Rabe와 Staats와 Dao 등(2022)의 연구에서 영감을 받아
다중 헤드 어텐션 연산(causal multi-head attention operator)의 효율적인 구현을 사용합니다.
이 구현은 xformers 라이브러리에서 사용 가능하며,
어텐션 가중치를 저장하지 않고 언어 모델링 작업의 인과성으로 마스크 된 키/쿼리 점수를 계산하지 않음으로써 메모리 사용과 계산량을 줄입니다.
더 나아가, checkpointing을 이용하여 역전파 동안 다시 계산되는 활성화 함수의 양을 줄이는 등의 작업을 수행하여 훈련 효율성을 더욱 개선합니다.
이를 위해 PyTorch autograd에 의존하는 대신,
트랜스포머 레이어에 대한 역전파 함수를 수동으로 구현하여 선형 레이어의 출력과 같은 계산량이 많은 활성화 함수를 저장합니다.
이 최적화를 최대한 활용하려면 모델과 시퀀스 병렬 처리를 사용하여 모델의 메모리 사용량을 줄여야 하며(Korthikanti 등, 2022), 네트워크 상의 활성화 함수 계산과 통신 간(all_reduce 작업으로 인한) 중첩도 가능하도록 합니다.
65B-parameter 모델의 경우, 2048 A100 GPU에서 80GB의 RAM을 사용하여 약 380 토큰/초/GPU를 처리합니다. 따라서 1.4T 토큰을 포함한 데이터 셋을 훈련하는 데 약 21일이 소요됩니다.

엄청난 양입니다.. 하지만 큰 걱정 할 필요 없습니다! 계속 리뷰 보시겠습니다.

비슷한 크기의 모델, 더 큰 모델과 비교하여 최고 성능 달성
이전 연구들 (Brown et al., 2020)을 따라, 우리는 zero-shot 및 few-shot 작업을 고려하고, 다양한 벤치마크에서 결과를 공유 합니다.
• Zero-shot.
작업에 대한 문장 설명과 테스트 예제를 제공하고, 모델은 열린 식 생성을 사용하여 답변을 제공하거나 제안된 답변을 순위에 따라 평가합니다.
• Few-shot.
작업에 대한 몇 가지 예시 (1~64개)와 테스트 예제를 제공하고, 모델은 이 텍스트를 입력으로 사용하여 답변을 생성하거나 다양한 옵션을 순위에 따라 평가합니다.
논문은 LLaMA를 다른 기초 모델들인 비공개 언어 모델 GPT-3, Gopher , Chinchilla , PaLM 그리고 오픈소스 OPT 모델 (Zhang et al., 2022), GPT-J , GPTNeo 와 비교합니다.
뒷장에서는 LLaMA를 OPT-IML 및 Flan-PaLM 과 같은 fine-tuning 모델과 간단하게 비교합니다.
논문은 자유 형식 생성 작업과 다중 선택 작업에서 LLaMA를 평가합니다.
다중 선택 작업에서는 제공된 문맥을 기반으로 주어진 옵션 중 가장 적합한 완성을 선택하는 것이 목표입니다. 주어진 문맥에서 완성의 가능성이 가장 높은 것을 선택합니다.


이번 섹션에서는, LLaMA-65B 모델이 기본적인 명령에 따르는 것을 이미 할 수 있지만, 아주 작은 양의 finetuning이 MMLU 성능을 높이고 모델이 지시를 따르는 능력을 더 향상시킨다는 것을 보여줍니다.
이 연구는 이 논문의 초점이 아니므로 Chung et al. (2022)과 동일한 프로토콜을 따라 instruct 모델인 LLaMA-I를 훈련시켰습니다.

위 표에서, 우리의 instruct 모델 LLaMA-I의 MMLU 결과를 보고, OPT-IML (Iyer et al., 2022) 및 Flan-PaLM 시리즈 (Chung et al., 2022)와 같은 중간 크기의 기존 instruct finetuned 모델과 비교한 결과입니다.
이번 연구에서 사용된 간단한 instruct finetuning 접근법에도 불구하고, MMLU에서 68.9%를 달성했습니다. LLaMA-I (65B)는 중간 크기의 instruct finetuned 모델보다 MMLU에서 우수한 성능을 보입니다. 그러나 MMLU에서 GPT code-davinci-002의 최신 기술인 77.4에는보다는 낮긴 합니다.

편견, 차별, 모욕적인 내용의 데이터 생성
대형 언어 모델은 훈련 데이터에 존재하는 편견을 재생산하고 증폭시키는 것으로 나타났으며(Sheng et al., 2019; Kurita et al., 2019), 편견, 차별이 있는 모욕적인 내용을 생성할 수 있습니다.(Gehman et al., 2020). 논문은 훈련 데이터 셋이 웹에서 수집된 데이터의 상당 부분을 포함하고 있기 때문에, 이러한 모델이 이러한 콘텐츠를 생성할 수 있는 잠재적 위험성을 파악하는 것이 중요하다고 생각했습니다.
LLaMA-65B의 잠재적인 위험성을 이해하기 위해, 우리는 독성 콘텐츠 생성 및 스테레오타입 감지를 측정하는 다양한 벤치마크에서 평가를 실시하였습니다.

사진 설명을 입력하세요.
높을수록 해당 부분에 대한 내용을 포함한다는 내용이고 LLMA는 평균적으로 다른 언어 모델에 비해 그런 부분을 덜 생산하는 걸 확인할 수 있습니다.
언어 모델 커뮤니티에서 일부 문제점을 나타내는 일부 표준 벤치마크를 선택하였지만, 이러한 평가는 이러한 모델과 관련된 위험성을 완전히 이해하기에 충분하지 않았다고 합니다.

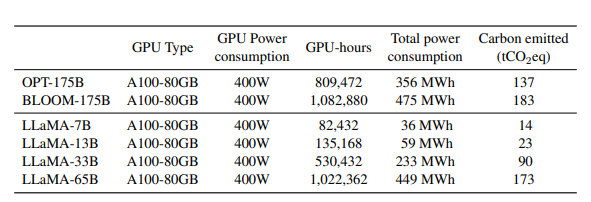
모델의 학습은 대량의 에너지를 소모하고 이에 따라 이산화탄소 배출을 유발했습니다.
이 모델들을 개발하는 데 약 5개월 동안 2048 대의 A100-80GB를 사용했다고 추정했습니다. 따라서 이 가정 하에 모델 개발에 약 2,638 MWh가 필요하며 총 1,015 tCO2eq의 배출이 발생했습니다. 이러한 모델을 공개함으로써 이미 학습이 완료된 상황에서 미래의 탄소 배출을 줄일 수 있으며, 일부 모델은 상대적으로 작아 하나의 GPU에서 실행할 수 있어 더욱 효율적인 에너지 사용이 가능할 것입니다.
멋집니다!

본 논문에서는 대규모 언어 모델 시리즈를 공개하며, 최첨단의 기반 모델과 경쟁력을 지닌 것을 제시했습니다.
특히, LLaMA-13B는 10배 이상 작은 크기임에도 불구하고 GPT-3보다 우수한 성능을 보이며,
LLaMA-65B는 Chinchilla-70B 및 PaLM-540B와 경쟁력이 있습니다.
이전 연구와는 달리, 상용 데이터 셋을 사용하지 않고 공개 데이터만을 사용하여 최첨단 성능을 달성할 수 있다는 것을 보여주었습니다.
이 모델들을 연구 커뮤니티에 공개함으로써 대규모 언어 모델의 개발을 가속화하고, 유해성과 편향 같은 알려진 문제를 완화하는 노력에 도움이 될 것을 기대한다고 합니다.
또한, 이 모델에게 우리가 하고자 하는 테스크의 목표에 대해 Fine Tuning 하면 결과를 얻을 수 있다는 것을 발견했습니다.
마지막으로, 우리는 꾸준한 성능 향상을 보았기 때문에 더 큰 사전 학습 말뭉치에서 훈련된 더 큰 모델을 미래에 공개할 계획입니다.
교육 & 프로젝트 문의
tfkeras@kakao.com




댓글