안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Debiased Contrastive learning of Unsupervised Sentence Representation'입니다.
해당 논문은 ACL 2022년에 Publish된 논문입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임'Debiased Contrastive learning of Unsupervised Sentence Representation’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/SJUZFEE5ELw)

먼저 알아야 할 background 입니다.
첫 번째로는 sentence representation learning 입니다. 이 sentence representation learning은 sentence 단위로 representation를 뽑아서 다양한 테스크의 성능을 올릴 수 있도록 유니버셜한 sentence representation learning을 많은 연구를 통해 하고 있습니다. 특히 sentence representation에 조금 강한 pretrain language 모델을 활용합니다. 이 pretrain 된 language 모델의 문제점 중 하나가 Anisotropy 한 문제를 갖고 있습니다. Anisotropy 한 문제는 embedding space가 이 전체적인 차원을 쓰지 못하고 이렇게 narrow 한 곳 안에서만 representation embedding이 되는 것을 뜻합니다. 이렇게 되면 당연히 classification 할 때 성능이 덜 나올 수밖에 없는 embedding 구조입니다.
그래서 이런 문제를 해결하기 위해서 Contrastive Learning을 활용합니다. Contrastive Learning은 의미가 비슷한 것은 가까워지고 의미가 비슷하지 않은 것은 embedding space에서 멀어지도록 학습하는 것입니다. 의미가 비슷한 게 가까워지도록 하는 것이 Alignment를 만족했다고 할 수 있고 다른 의미들이 representation 공간을 다 쓰도록 embedding 되는 것이 Uniformity를 만족시킨 epresentation라고 생각할 수 있습니다.
그래서 이 대조학습을 위해서 Positive pair를 구성하기 위한 연구가 굉장히 활발히 진행되었습니다. 대표적으로 SimCSE 같은 경우에는 Dropout을 미니멀한 Augmentation으로 활용해서 positive pair로 두고 in batch안에sentence들을 negative로 보는 연구가 정말 인기가 많고 사람들이 많이 찾아보고 있습니다. 그런데 이 논문에서는 in batch negative에 대한 random 하게 샘플 되는 negative에 대한 연구가 없다고 얘기하고 있습니다.
그리고 또 한 가지는 Virtual AdversarialTraining 입니다.VirtualAdversarialTraining은 어떠한 특정 Noise를 주어서 하나의 데이터를 만들고 이것을 인공지능이 인지하도록 해서 robust 한 학습이 가능해지도록 하는 기법입니다.
그래서 NLP 에서는Adversarial 한 Noise를 embedding layer 에서 많이 주어지고 이러한 것들이 Text classification 이나 Translation에서 조금 효과적임을 보여주고 있다고 논문에서 언급하고 있습니다.

그래서 대표적으로 알아야 되는 SimCSE입니다.
SimCSE는 동일한 문장을 random Dropout 된 encoder에 두 번 통과시켜서 같은 의미를 갖고 있지만 조금 다른 hidden representation를 갖고 있는 두 가지의 embedding 값을 뽑아내서 Positive로 학습하게 하고 이 batch 내에 있는 다른 sentence 들을 negative로 멀어지게 학습하도록 하는 대조 학습 기법입니다.
이 논문에서는 framework에 대한 문제점으로 in batch negative sentence들이 생각보다 높은 Similarity를 갖고 있다. 이렇게 Similarity를 보면 0.7 이상의 Similarity를 갖고 있는 것이 반 이상이 된다라고 지적을 하고 있습니다. 또 하나의 문제로 pretrain 된 language 모델이 Anisotropy 한 문제가 Semantic을 제대로 이해하도록 하는 representation을 나타내기 어렵다고 얘기하고 있습니다.

해당 논문은 위의 문제점 두 개를 해결하기 위해서 DCLR 이라는 framework를 제안하고 있습니다. 이 DCLR은 Debiased Contrastive learning of Unsupervised Sentence Representations 입니다. 여기에 핵심 아이디어로는 in batch negative안에서 유사도가 높은 것을 false negative로 보고 false negative에 대해서 웨이트를 주어지겠다고 하는 것입니다. 또 하나는 Gaussian noise를 통해서 Adversarial 하게 학습을 하고 이러한 학습을 통해 Uniformity를 잘 지켜내도록 하겠다는 아이디어입니다.

해당 논문은 세 가지의 contribution이 있습니다. 첫 번째로는 unsupervised sentence representation의 대조학습에서 bias에 대한 sampling bias를 줄이는 것에 대해서 첫 번째 시도를 하였고 또 하나는 DCLR이라는 framework를 제안했습니다. 세 번째로는 이 framework를 통해 일곱 개의 STS 테스크에서 효과적임을 보였다고 얘기하고 있습니다.

논문의 Approach입니다.
하나는 Adversarial 한 측면에서의 기법입니다.
Noise를 Generating 해줘야 하는데 이 Gaussian 분포를 활용해서 Noise를 주어지게 되고 이 Noise가 주어진 Noise base negative들이 Contrastive learning Loss의 negative 자리로 합쳐져서 이 Noise가 주어진 것을 조금 더 Uniformity 하게 학습하도록 해주는 것입니다.
하나는 Contrastive with instance Weighting입니다. 이거는 하나의 Threshold를 줘서 해당 negative들이 Threshold 이상의 유사도를 갖고 있을 때는 0으로 주어서 negative로 학습을 하지 않도록 하고 Threshold 이하일 때는 negative로 보겠다 해서 1을 웨이트로 주는 것을 말합니다.
그래서 이 두 가지 방법으로 아까 앞서 말했던 두 가지의 문제점을 해결하도록 framework를 제안하고 있습니다.

실험입니다. 실험 비교를 굉장히 다양하고 많은 실험을 했다는 것을 알 수 있습니다.
첫 번째로는 Glove와 USE입니다. 이는 static 한 방법을 이용한 것입니다. 두 번째로는 PLM을 활용할 때 Flow를 어떻게 쓰냐라는 것도 비교하고 있고 그다음으로는 isotropy 한 게 pretrain 된 language 모델을 좀 isotropy 하게 해결한 모델 두 가지와 Contrastive learning을 하고 있는 네 가지 방법을 비교하고 있습니다.
여기 보시면 static 한 것이 좋은 성능을 내고 있지는 않지만 그래도 PLM을 활용했을 때 중간 정도의 그런 성능을 낼 수 있다는 것을 알 수 있습니다. 여기에 Contrastive learning을 base로 한 모델들이 대체적으로 좋은 성능을 보이고 있음을 알 수 있습니다. 그중에서도 SimCSE가 DCLR를 제외했을 때 가장 좋았고 DCLR을 적용했을 때는 DCLR이 가장 좋았다고 논문에서 얘기하고 있습니다.
DCLR은 SimCSE에서 Debias 한 부분과 Adversarial 한 어택을 통해서 성능을 올렸다고 생각하시면 될 것 같습니다.
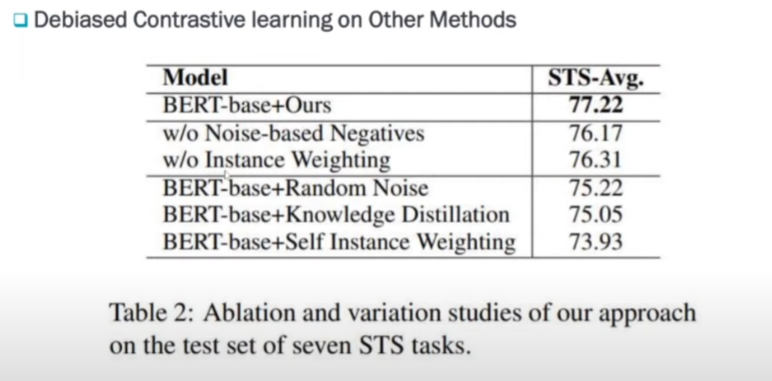
Debiased Contrastive learning을 다른 Methods들과 비교했을 때입니다.
Noise base negative가 없었을 때 성능과 Instance Weighting이 없었을 때 성능을 비교해 봤을 때 좋은 성능을 내고 있다는 것을 알 수 있었고 즉, 이 두 가지 방법이 성능 향상에 유의미했다고 알 수 있습니다.
마찬가지로 random Noise나 Knowledge Distillation 그런 것들과 비교했을 때도 이 방법이 가장 좋았다고 얘기하고 있습니다.
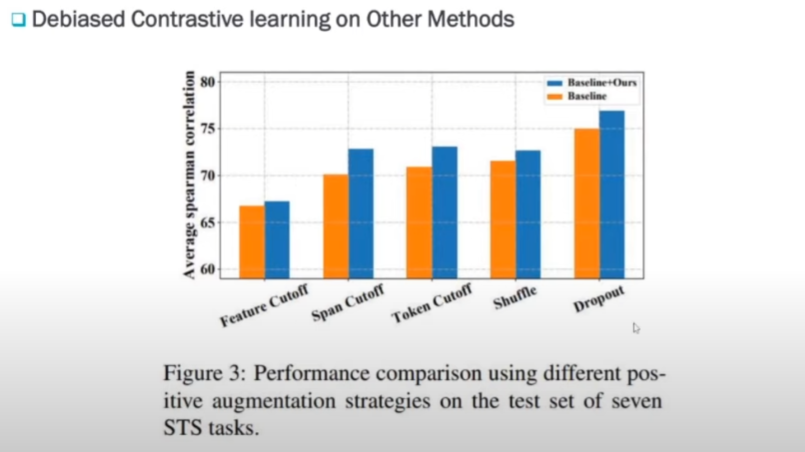
해당 논문은 여러 가지 Augmentation 기법에다가 DCLR를 적용해 보았습니다. feature Cutoff나 Dropout 같은 경우에는 SimCSE와 같은 방법입니다. 모든 방법에서 DCLR을 적용했을 때 좋은 성능을 보였다고 실험으로 보여주고 있습니다.
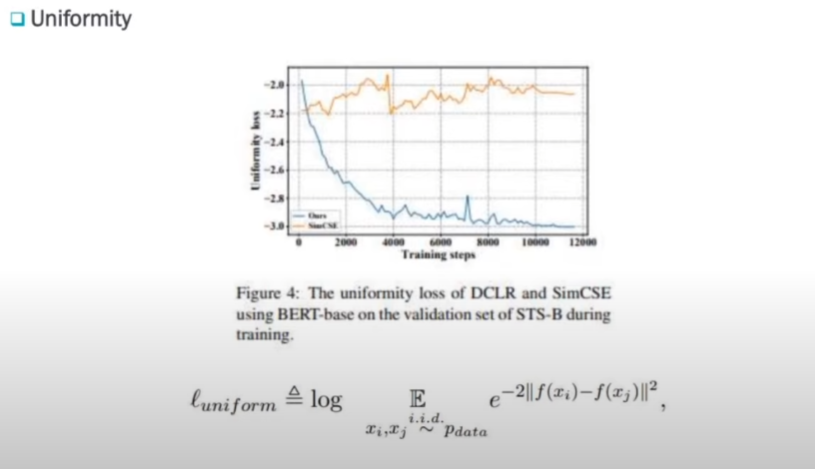
그리고 sentence representation에서 중요한 정량적 지표 중 하나가 Uniformity입니다. 이 Uniformity도 DCLR을 활용했을 때 훨씬 작은 Loss를 갖고 있음을 보여주고 있습니다. 주황색이 SimCSE이고, 이 SimCSE에다가 DCLR를 적용했을 때 Uniformity가 훨씬 좋아지는 것을 볼 수 있습니다.
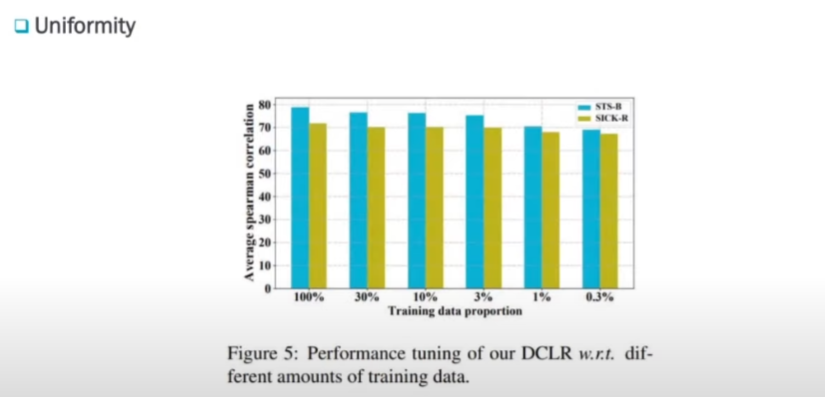
그리고 트레이닝 데이터에 대한 비율에 따라서 성능 변화를 보이고 있습니다. 이 트레이닝 데이터가 굉장히 작을 때에도 성능이 많이 떨어지지 않을 수 있다는 것을 보여주고 있습니다.
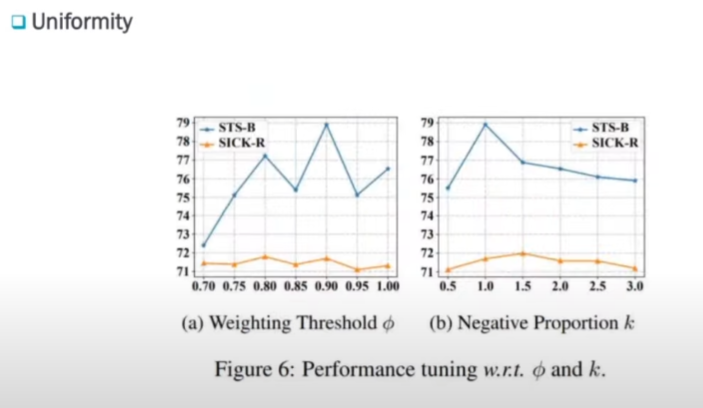
그리고 하나는 Threshold가 어디서 제일 좋고 negative 비율이 어디서 제일 좋은지입니다.
여기는 1.0 여기는 0.9일 때 가장 좋음을 알 수 있습니다.

결론입니다.
해당 논문의 Contribution은 DCLR를 제안하였고 DCLR의 아이디어 2개는 random sampling bias를 줄이는 것 하나와 Instance weight method를 통해 false negative에 영향을 줄인 것입니다.
한 가지 더는 Adversarial 한 어택을 줘서 그거에 대해 조금 더 robustic 하게 학습을 할 수 있었다는 거 하나입니다. 그래서 결과론적으로 보면 일곱 개의 STS 테스크에서 좋은 효과를 보였다고 논문에서 말하고 있습니다.




댓글