안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘SPLADE : Sparse Lexical and Expansion Model for First Stage Ranking’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘SPLADE : Sparse Lexical and Expansion Model for First Stage Ranking’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/OvVajh6yPEg)
이번 시간에는 간단한 배경 설명과 SPLADE가 제시하는 논문이 무엇인지에 대해서 설명드리겠습니다.
자연어처리 분야에서 메인 테스크가 아닌 Neural 네트워크를 기반으로 한 Information retrieval라는 도메인과 특정 분야에 있는 논문입니다.
Neural IR이 좀 생소할 수 있는데 네이버 같은 검색엔진 경우가 그런 경우입니다. 이는 검색엔진에 가장 기초가 되는 부분이라고 볼 수 있습니다. 검색엔진 구성요소가 여러 가지가 있는데 그중에 SPLADE는 retrieval 모델에 해당이 됩니다. retrieval 모델 간략하게 설명을 드리고 Stage of search나 Information retrieval의 최근 BNN에 NLP 부분에서 어떤 변화가 있었는지 간단하게 훑어 보고 세부적으로 indexing하는 approach가 여러 가지 방법이 있는데 Dense representation가 있고, Sparse representation가 있고 최근엔 attention representation 분야로 새롭게 나눠지고있는데 가장 전형적인 케이스인 Dense와 Sparse에 대해서 간단하게 소개드리도록 하겠습니다.
마지막으로 SPLADE가 어떤 논문인지 소개를 하면서 발표를 마무리하도록 하겠습니다.

retrieval 모델을 설명하기 앞서서 검색엔진 이라고 말씀을 드렸는데 검색엔진 분야에서도 Answering Questions System 즉, Q&A 모델로 가장 많이 활용되고 있는 분야 중 하나입니다.
검색엔진 하면 우리가 단어를 입력하면 해당 단어의 내용과 유사한걸 보통 검색 엔진으로 활용하고 있습니다. 최근에는 딥러닝이랑 기존의 챗봇 시스템이나 간단한 질의응답 시스템도 많이 개발이 되고 있는데 그중에서 가장 앞단에 해당되는 부분입니다. 그게 바로 vector database입니다.
사실 database는 여러 가지 형태가 있을 수 있습니다. 지금처럼 유명한 레디스라는 db도 key-value 형태로 되어 있고 Elastic search도 document db를 해서 document와 index간의 관계를 구조하는 db도 있고 Graph db도 있습니다.
오늘 소개해드릴 database 형태 중 하나인 vector database는 데이터가 numerical space에서 각각의 데이터 정보가 numerical vector로 표현된 database라고 보시면 될 것 같습니다.
실제로 프로버크에서 구현을 한다고 하면 어떤 특정 database 플랫폼을 활용할 수도 있지만 in memory 시스템에서 구현이 된다고 보시면 될 것 같습니다.
일단 database가 첫 번째로 구성이 되야합니다.

두 번째는 오늘 소개해드릴 논문의 가장 큰 범주인 retrieval 모델은 뽑는 모델입니다.
우리가 database에는 엄청나게 많은 document가 저장이 되어 있는데 해당 document를 다 indexing을 할 순 없습니다. 왜냐하면 사실 우리가 지금 검색엔진을 쓰고 있는 것도 구글에서 갖고 있는 모든 database를 다 색인한 결과가 아니고 구글은 이미 우리가 검색하기 전에 뭘 검색할 지 미리 알고 있습니다. 그리고 보통은 최신 시간순으로 되어 있고 해당 위치나 나의 계정 정보나 가장 많은 사람들이 검색하고 있는 query들이 구글은 미리 다 알고 있습니다. 그래서 미리 뽑아서 거기에 맞는 passage를 검색을 하게 되어 있습니다.
passage를 뽑는걸 retrieval라고 하고 ranking 모델을 쓰고 있습니다. 보통 Elastic search도 document db긴 하지만 실제로는 indexing 해 주는 기능이 내장되어 있는데 결국은 query가 들어오면 query에 맞는 context를 Passage라 부르는데 미리 candidate로 뽑는 과정을 말합니다.

보통 NLP에서 MRC라고 부르는 Machine reading comprehension 모델이라고 불리기도 하는데 결국 그 질의응답 시스템은 query가 들어오면 해당 정답을 찾아 줘야되는 문제가 또 하나 더 추가가 됩니다.
그래서 단순히 구글 검색엔진 결과만 보는 게 아니고 거기 안에 해당 컨텐츠 안에 특정 span들을 포착해서 ML 알고리즘을 찾아 줍니다.
여기에 reader 모델입니다. 우리가 챗봇은 아주 훌륭한 챗봇을 쓴다고 하고 구글이나 인공지능 비서 많이 씁니다. 그런 시스템이 다 reader 모델까지 다 attach 되어 있어서 결과적으로는 Why did Alyssa go to Miami?으로 specific하게 질문을 던지면 해당 passage를 indexing해서 뽑은 다음에 질의에 의미와 기대되는 정답이 가장 유사한 span찾는거 까지 To visit some friends 으로 specific한 텍스트를 뽑는 과정까지 전체가 Q&A 시스템입니다. 그중에 Neural Ir 부분에 retrieval 모델 중간 단계 역할이라고 보시면 됩니다.

retrieval가 ranking 모델이기도 합니다. ranking은 Pre-selecting candidate라고 하는데 전체 document를 다 뒤지는 게 아니고 미리 뽑아 놓습니다. 미리 뽑아 놓은 걸 ranking이라고 하는데 기존에는 term base 모델을 많이 사용을 했습니다.
Term은 키워드입니다. 구글에다가 검색을 한다고 하면 node js 서버 검색한다고 하면 nodejs가 term이 되고 install이 term이 됩니다. 이런 식으로 term base 모델을 많이 사용했었는데 traditional한건 bm25랑 inverted index, Elastic search에 있는 역색인 방법을 통해서 많이 활용하고 있습니다.
ranking의 특징 중 하나는 quick access 할 수 있습니다. 그래서 가장 query에 맞는 document를 access 할 수 있는 걸 말하고 검색엔진에서는 보통 이런 형태 때문에 해당 워드나 document를 detecting 해 주고 해당 단어가 가장 유의한 단어를 찾기 위해서 카운팅을 해줘야 됩니다. 여기서 카운팅 해주거나 detecting해줘야 되는 그런 문제가 있는데 결과적으론 Sparse한 words는 못찾습니다.
왜냐면 말 그대로 아주 쉽게 등장하는 단어인데 등장하는 document를 색인하는건 사실 상당히 되게 어려운 부분이고 특정 단어가 한 번 등장 했다고 해서 그게 유의미 하냐 했을 땐 어려운 문제가 됩니다.
단순히 ranking만 하기에는 한계가 있습니다. 한 번 더 re-ranking 해주는 과정을 거칩니다 retrieval가 re-ranking을 해주는데 결과적으로는 indexing을 해 주는데 좀 더 ordering을 내려줍니다. 가장 그럴싸한 document를 한 번 더 candidate를 뽑은 다음에 다시 순서대로 매겨서 좀 더 적합한 결과를 잘 찾을 수 있게 해주는 Ranker라고 단순히 ranking 해주는 것보다 Re-ranker가 computation cost가 훨씬 더 큰 차이점이 있습니다.

요즘은 BNN을 많이 사용하니까 실제로 구글은 이미 트랜스폼 되어 있고 네이버도 최근에 트랜스폼 되어서 vision IR까지 많이 나오는데 대부분 아직 term base긴하지만BNN쪽으로는 결국 baseline이 BERT 모델을 사용합니다. BERT는 pre train language 모델인데 사전에 Corpus 한 번에 다 넣었다가 mask language로 학습시켜서 각 word별로 representation를 가진 모델입니다. 이는 가장 많이 활용하고 있고 되게 특이하게도 BERT가 나온지 3~4년 됐는데 다른 downstream task외에 IR에서 많이 활용되기 시작했습니다. 최근 1~2년 사이인데 특이하게 SOTA를 달성했습니다.
이는 아주 큰 차이고 그래서 기존에 term base였다면 BERT를 쓸 수 있으니까 sentence로 통째로 임베딩 시켜 가지고 vector space database를 구축할 수 있어서 또 backbone 그대로 통째로 가져다 쓰다 보니까 처음에 ranking 해주는 효과가 훌륭합니다. 그래서 사람이 더 일일이 rule을 주거나 heuristic하게 어떤 구조를 줄 필요 없이 backbone 그대로 가져다가 사용할 수 있습니다.
Sparse 모델은 TF-IDF, BM25, LSI 이런 전통적인 구조를 많이 활용 했습니다. BERT는 어떤 전체 맥락 흐름을 제어하고 그걸 가지고 학습한 모델이기 때문에 생각보다 찾기 어렵습니다. 예를 들어 아주 신생 단어 같은 경우나 아주 specific한 단어 손흥민, 토트넘 딱 특정 단어를 찾아야 되는 문제에서 상당히 취약합니다. 첫 Sparse 모델을 연구하는 거 자체가 Neural IR한 큰 주제이기도하고 결론적으로 BERT를 많이 사용합니다.
최근에 Semantical representation 학습에 가장 큰 효과를 준 논문은 ANN. Approximate nearest neighboring라는 논문이고 나온지 1~2년 밖에 안된 논문입니다. vector repositioning 한 다음에 가장 근처에 있는 document들끼리만 index를 부여해가지고 부여한 과정은 BERT를 사용하는 이런 논문들이 있었습니다.

ranking은 document indexing을 해 주는 건데 document의 어떤 웨이트를 더 부여할 것이냐의 문제입니다.아까 말씀드렸던 것처럼 크게 IR쪽에는 Dense representation과 Sparse representation 있습니다. Sparse representation부터 설명 드리면 Lexical이라는 개념이 있고 Semantic이란 개념이 있습니다.
Lexical는 특정 단어나 신생 단어 혹은 의미가 아직 symbolic하게 단어의 의미가 부여된 상황이라고 보시면 될 것 같습니다. 보통 이 텍스트처럼 Corresponding actual specific words 혹은 subword 아주 symbolic한 의미가 갖고 있어야 되는 상태가 바로 Lexical입니다. 그래서 보통 이런 경우에는 Easier to interpret how documents are ranked by a given query 주어진 query에 의해서 특정 document가 어떻게 해서 도출 되었느냐 추론하기 아주 쉽습니다. 왜냐면 Lexical하기 때문에 document가 나온 이유에 대해서 확실하기 때문입니다.
sparse search engine 이런 특정 도메인 단어에 특화된 search engine을 구축한다고하면 상당히 낮은 cost에서도 만들 수 있습니다. 왜냐면은 아무런 구분 없이 검색을 하게 되면 성능이 떨어지기 때문에 Sparse가 필요한 부분에선 되게 좋은 방법론중 하나입니다. 하지만 단점은 있습니다. 요즘 많이 쓰는 BERT를 활용한다고 하면은 블랙박스기 때문에 어떤 단어를 도출하고 이걸 어떻게 추론할 수 있는지 예상하기도 힘들고 예상한 결과에 대해서 분석하기 매우 어렵습니다. BERT는 이런 단점을 가지고 있습니다.
기존에는 bpr 모델이라 해서 아주 유명한 논문입니다. Dense representation같은 경우 말 그래도 Semantic한 passage나 query가 들어오면 유사한 의미를 가진 문장이나 단어들을 매칭 시켜서 Similarity 구하는 방법이라고 보시면 되는데 대체적으로는 보통 학습 데이터셋 IR 쪽에도 데이터셋이 있는데 대체적으로 Sparse 보다는 Dense approach가 훨씬 좋습니다. 그래서 대체적으로 Neural IR쪽에 연구가 되는 주제는 Dense representation이긴 한데 성능은 훨씬 더 좋고 실제 사용하기도 더 좋은 평을 듣고 있습니다.
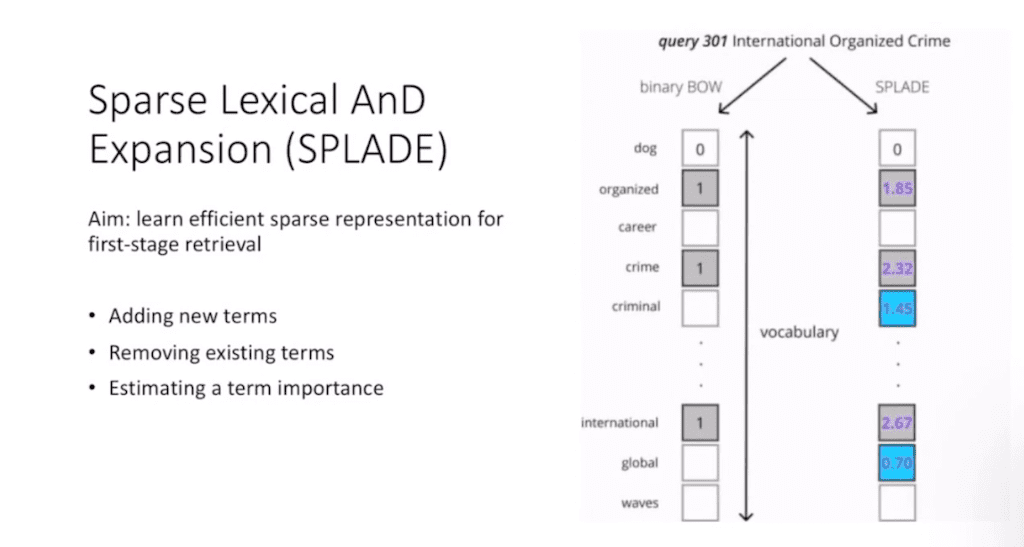
논문의 가장 본 주제인 SPLADE에 대해서 설명드리겠습니다. SPLADE은 어떻게 하면 Sparse representation를 잘 학습을 시킬수 있냐를 뜻합니다.
지금 보시는 것처럼 신규 term들을 더 추가하는 경우를 볼 수 있습니다. 예를 들어 의미 없는 단어들을 다 빼버리고 다음에 regularization해주는 데 특정 신규 단어 의미와 유사한 단어들은 symbolic한 거 가지고 추가를 해서 sequence token 중 하나로 추가를 합니다. 그다음에 backbone 모델에 넣고 학습데이터로 학습을 할 때 그 각각의 해당 단어에 토큰이 되면 토큰의 웨이트를 추론하는 걸 학습을 합니다.
그래서 SPLADE는 기존에 어떤 학습 데이터에 정답과 추론한 결과에 클래스나 이런 span들을 결과를 하는게 아니고 해당 단어가 얼마만큼 중요한지 그런 importance를 추론하는 게 기본 관건이라 볼 수 있습니다.

그래서 가장 중요하게 여겨지는 강제된 단어들의 웨이트를 계산을 하게 되는 것처럼 트리트먼트가 핵심 단어가 된다고 여겨지면 트리트먼트가 중요한 웨이트를 가지게 됩니다. Problem같은 경우는 expansion 해 준 것입니다. 중요하게 여겨지는 단어가 있으면 추가해서 넣는다고 말씀드렸는데 이런 단어들이 더 추가되면 좀 더 Lexical 하기에는 query를 더 설명할 수 있겠다라는 차원이 있다 보면 이런 단어들을 추가하고 다음에 의미 없는 leg 같은 거는 별로 의미가 없다면 빼버립니다. 그리고 나서 실제 document도 똑같이 빼 줍니다. 똑같은 전처리 작업을 해 줍니다.
이것을 가지고 서로 비교해서 ranking을 매겨준다고 보시면 될 거 같습니다. 그래서 결과적으로는 Expansion rich document symbolic하게 의미적으로 되게 엄청나게 fully rich 합니다. 그래서 우리가 문장을 쓸 때 조사도 들어가고, 접속사 들어가고 이런 경우 많으니까 이런걸 다 떼버리니까 하나하나단어들이 가지는 의미들이 엄청나게 커집니다. 이런 식으로 아주 그런 희귀한 단어들만 가지고 학습을 한다고 보시면 될 거 같습니다.

Sparse의 모델이 무엇이냐 라고 봤을 때 첫번째는 그림에서 맨 아랫부터 보시면 처음에는 document랑 query를 tokenize 해주면 결국 BERT의 vocabulary에 의해서 쪼개지기 때문에 각각의 CLS 토큰에 부가적인거고 각각의 BERT에서 학습된 단어들만 가지고 단어를 구성을 합니다.
다음에 BERT 모델에 넣고 MLM 모델을 통과시키면 어떤 특정 마지막 레이어가 나옵니다. 하나의 document는 하나의 single term으로 표현될 수 있게 최소한의 정보의 의미를 압축할 수 있는 단어로 saturating 해줍니다.
여러 개 document가 나오게 되면 각각의 document들 logit을 매겨가지고 각각의 웨이트를 계산을 해 줍니다.계산을 해 주게 되면 해당 document digit이고, calculation이고, dog, stock이고 이런 symbolic한 결과들이 나오게 되어 있습니다.이런 document 가지고 실제 query랑 매칭시켜서 ranking을 매겨주는 그런 과정을 거친다고 보시면 될 것 같습니다.
그래서 마지막에는 query랑 document를 얼마나 유사한지 dot product 내적을 해서 얼마나 유사한지 체크합니다.
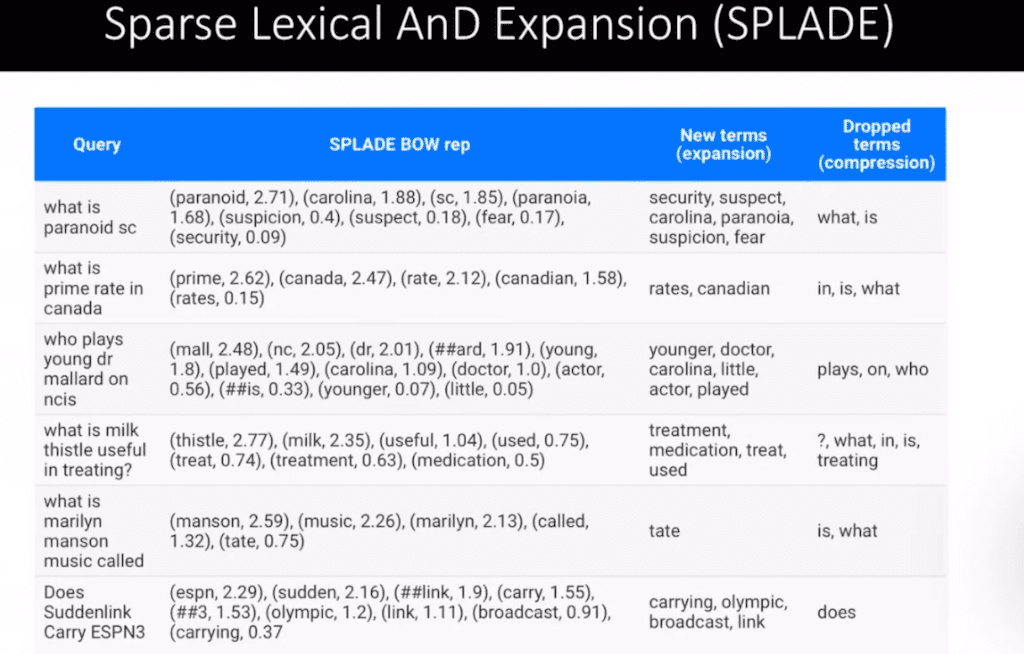
기존에 query는 질문하듯이 던질 수 있고 그다음에 query들을 각각의 가중치 초기화는 랜덤 하게 되어 있고 이걸 가지고 계속 학습을 하게 됐는데 이 term이 추가되는 security, suspect, Carolina 등 단어들이 추가가 되면은 좀 더 의미가 fully하게 들어가지게 됩니다. 그러면 각각의 단어는 Sparse하면서도 의미가 충분한 sentence를 구할 수 있게 됩니다.
반면 what is 등 부사나 조사 다 빼버리고 regularization 과정을 거칩니다. 이거는 query의 경우고 document도 동일합니다. 그래서 document와 query는 사실 상당히 되게 유사한 단어들간의 매칭을 계산한다고 보시면 될 거 같습니다.
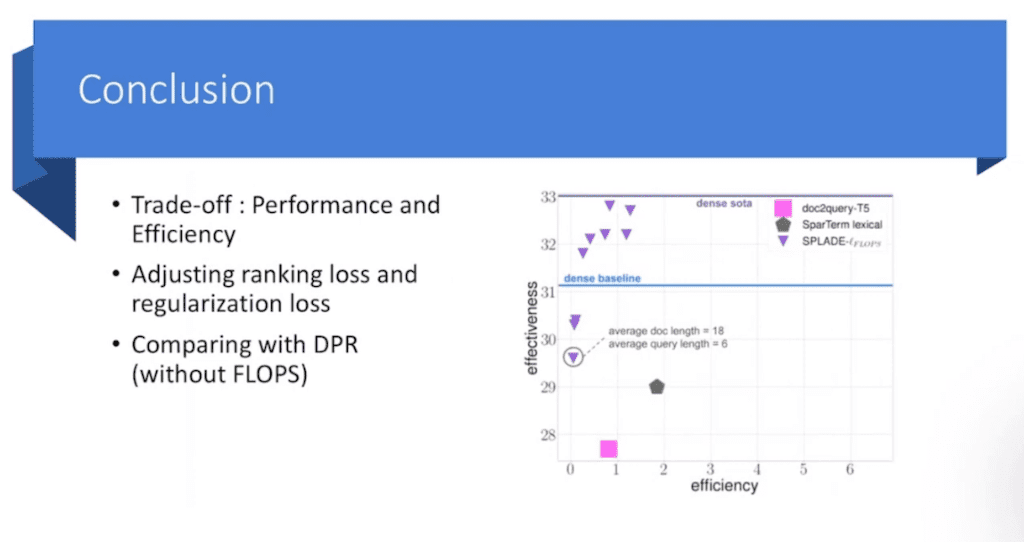
결과적으로는 모델 평가하는 데 있어서는 두 가지 지표가 있습니다.
하나는 effectiveness 라고 해서 결과적으로 정확도입니다. x축은 efficiency라고 해서 논문에서는 FLOPS라고 하는데 FLOPS를 어떻게 계산하는지는 따로 설명하진 않았고 결국은 계산량이기 때문에 계산이 커지면 커질수록 물론 성능은 좋을 수 있지만 한 번 검색하는데 5, 10초씩 걸릴 수 없어서 결국 속도에 의해서 가장 trade off 관계를 갖고 있기 때문에 얼마나 FLOPS안에서 높은 성능을 낼 수 있느냐라고 했을 때는 SPLADE가 짧은 시간 안에 나름 좋은 성능을 얻은 것을 확인할 수 있습니다.
아까 말씀드렸던 것처럼 Dense가 대체적으로 데이터 성능이 좋다고 말씀드렸는데 지금 보시면 Dense 보다 성능이 되게 떨어집니다. 그래도 나름 파라미터 튜닝하고 하다보면 Dense의 baseline을 넘어서는 걸 볼 수 있습니다.
맨 위는 Dense SOTA기 때문에 bpr이 개선된 버전이고 어쨌든 Dense랑도 비교했을 때도 baseline을 통과했기 때문에 Dense representation retrieval라고 상당히 경쟁적으로 쓸 수 있는 모델이다라는걸 보여 주고 있습니다.
Efficiency를 비교를 할 수 없다고 논문에서 얘기하고 있습니다. 왜냐면 Dense retrieval 같은 경우는 Efficiency를 따로 계산해 주는, 얼마나 효과적인지를 동일한 지표로 비교해 본 논문 결과가 없기 때문에 따로 설명을 하지 않았습니다.
하지만 bpr이라는 논문에서는 passage를 binary vector로 바꿔 주는 과정을 거칩니다. 메모리가 축소되서 Dense retrieval하게 뽑아주는 모델이 따로 있습니다. 보시면 성능에 대한 trade off를 많이 얘기를 하는데 일단은 다른 approach기 때문에 이러한 논문을 볼 수 있다고 소개해 드릴 수 있을 것 같습니다.




댓글