안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Improving the Quality Trade-Off for Neural Machine Translation Multi-Domain Adaptation’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Improving the Quality Trade-Off for Neural Machine Translation Multi-Domain Adaptation’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/c8-aLsXqvus)
이 논문은 EMNLP 페이퍼로 제출된 논문이고 내용이 짧고 간단한 내용입니다.

이 논문의 motivation은 NMT 트렌드를 자체가 Pre train 된 모델을 가지고 Fine tuning 하면서 성능을 높이는 게 대부분의 추세인데 그 경우에 general-purpose 모델이 주어졌을 때, generic domain에서 학습된 모델이 주어졌을 때 새롭고 다양한 domain에다가 최적화를 시키면서 동시에 원래 학습이 되었던 generic domain에 대해서도 성능을 유지할 수 있을까? 가 이 논문의 motivation입니다.

이런 의문을 가진 이유는 sequential 트레이닝 모델에서 항상 발생하는 문제인 catastrophic forgetting 문제를 해결하기 위해서입니다. catastrophic forgetting이란 어떤 새로운 task에 대한 성능이 올라가면서 이전에 학습시킨 task에 대한 성능이 급격히 떨어지는 현상을 말합니다.

목표에서는 두 가지 기법을 도입을 해서 generic domain에 대한 퍼포먼스를 유지하면서도 새로운 domain에 대한 성능을 올리는 것이 논문의 목표라고 보시면 되겠습니다.

먼저 가정을 하나 하고 들어갑니다. domain adaptation에 사용되는 target domain에 대한 데이터셋이 아주 적다고 가정을 합니다. 만약에 target domain에 대한 데이터셋이 많다면 여기에서 제안하는 방법이 적합하지 않을 수 있고 target domain에 대해서 from scratch로 학습시키는 것이 낫다는 것을 가정으로 하고 논문을 제안을 했습니다.

첫 번째로 제안하는 방법은 EWC라는 방법입니다. Elastic Weight Consolidation라는 기법입니다. 수식을 해석하자면 오리지널 task를 A라고 가정을 하고 새롭게 학습시킨 target domain을 B라고 할 때 새롭게 학습시키는 트레이닝에서 Loss function이 위 식으로 정의가 됩니다. 여기 LB가 말을 하는 거는 task B 파라미터에 대한 Loss를 의미를 합니다. 그리고 뒤에 붙는 텀은 기존의 A와 관련된 파라미터의 변화를 최소화하도록 학습하는 방식입니다.
여기 그림을 보시면 파라미터가 회색 범위에 있을 때 task A에서 Loss가 낮았다면 반대로 이 파라미터가 task B에 대해서 Loss가 낮으려면 이렇게 노란색 범위를 유지해야 한다고 할 때 뒤에 있는 텀에 페널티가 없을 때에는 이 파란색 화살표를 따라서 움직이게 됩니다.
그래서 이 파라미터가 움직이면서 task A에 대해서 Loss가 적었던 그 공간에 벗어나게 되면서 catastrophic forgetting 현상이 일어나게 되는 겁니다. 이런 현상을 막아주고자 task B에 대해서도 Loss가 낮고, task A에 대해서도 Loss가 낮게 이 방향으로 움직이도록 학습을 시켜주게 됩니다.

두 번째 방법은 Data mixing입니다.
Data mixing은 데이터를 섞어주는 방식입니다. 말 그대로 original task domain에 트레이닝 데이터셋이랑 새로운 target domain에 대한 트레이닝 데이터셋을 섞어주면서 학습을 시켜주게 됩니다.
2개의 비율을 조절하면서 generic과 domain 성능의 trade-off를 조정을 할 수 있게 됩니다.

이 두 가지 방법을 섞어서 학습시킵니다. 이때 Loss function을 정의합니다.
기존의 EWC는 이 논문에서 제안한 방식은 아니고 이전에 EWC만 제안한 논문이 있었습니다. 그 논문에서는 A와 task B에 대한 성능이 독립적으로 움직인다고 가정을 하고 EWC를 제안을 했습니다.
그래서 이 경우에 오리지널 task A의 데이터셋을 완전히 두 개로 나눕니다. 화살표를 잘못 적었는데 A1이 A2 보다 훨씬 더 작을 때 작다고 가정을 하고 이 식을 다시 세우면 A를 A1, A2로 split을 할 수가 있게 되고 이때 task B와 task A1, task B와 task A2가 독립적이었기 때문에 식들이 일치하게 됩니다.
그래서 이 의미는 A1이 전체 데이터셋 A를 대변할 수 있다고 이 식에서 나타내는 바가 됩니다. 그래서 이 식을 따라서 오리지널 task에 Data mixing을 통해 섞인 텀을 여기 A1 Loss를 추가하게 됩니다. 결국 이 식을 설명을 하면 task A1에 대한 Loss, task B에 대한 Loss를 더해주고 이때 이 task A1은 task A에 대해서 샘플링한 일부분에 그 데이터셋만을 의미합니다. 그리고 뒤에 텀을 추가를 해서 A와 B 가 동시에 작아지는 만족한 공간에서 파라미터가 위치할 수 있도록 조정을 해 주는 텀이 되겠습니다.
여기서 제안하는 방식은 이 두 가지가 전부입니다.
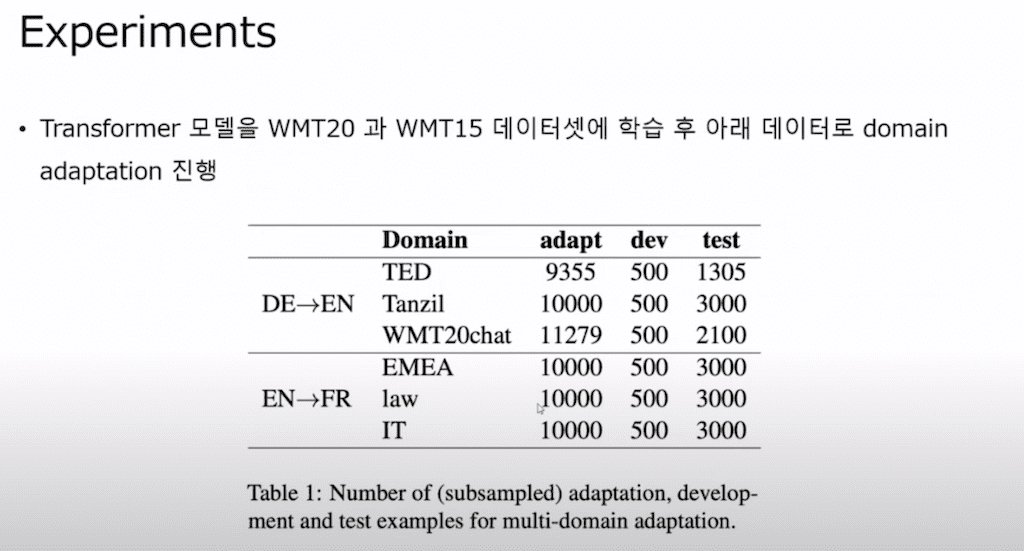
Experiments입니다.
먼저 generic domain에 대해서 트랜스포머 모델을 학습을 시킵니다. 트랜스포머 모델은 번역 데이터셋만 가지고 학습을 시키게 됩니다. 그 후에 아래에 있는 그 데이터셋을 가지고 domain adaptation을 시키게 됩니다. 독일어를 영어로 번역하는 task에 대해서는 구어체 데이터셋을 가지고 튜닝을 시키게 되고 위에 나와있는 샘플만 가지고 학습을 시키게 되고 dev 셋을 통해서 validation을 해서 학습을 중단시킵니다.
그리고 또 프랑스어 같은 경우에는 이렇게 세 가지 domain에 대해서 adaptation을 시키게 됩니다.
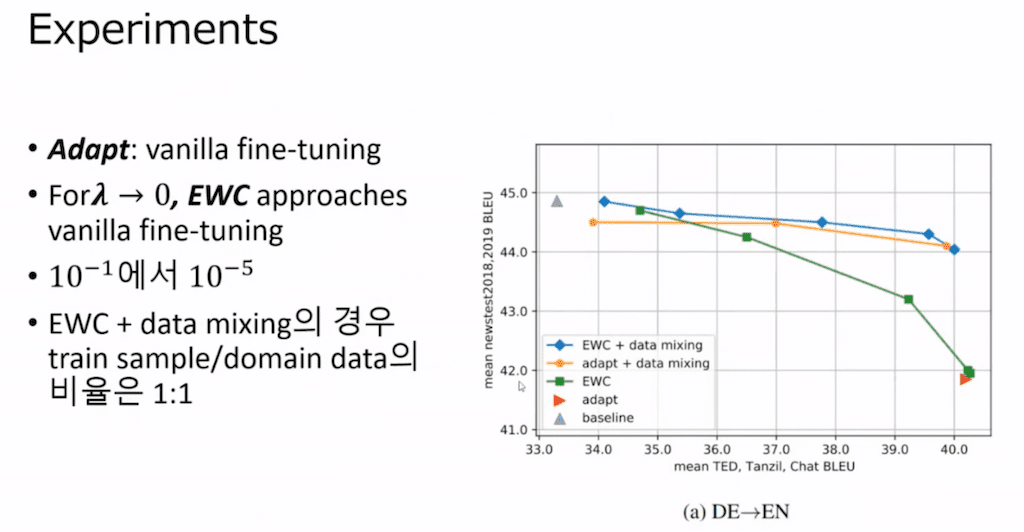
실험 결과를 보시면 일단은 왼쪽 축은 generic domain 데이터셋에 대한 성능의 평균값이라고 보시면 되고 그 아래 축은 새롭게 target domain에 대해서 학습을 시킨 것의 평균값이라고 보시면 될 거 같습니다.
그래서 결과를 보시면 파란색 선을 보시면 가장 generic에서도 성능이 좋고 그리고 target domain에 대해서도 성능이 좋은 거를 확인을 할 수가 있습니다.
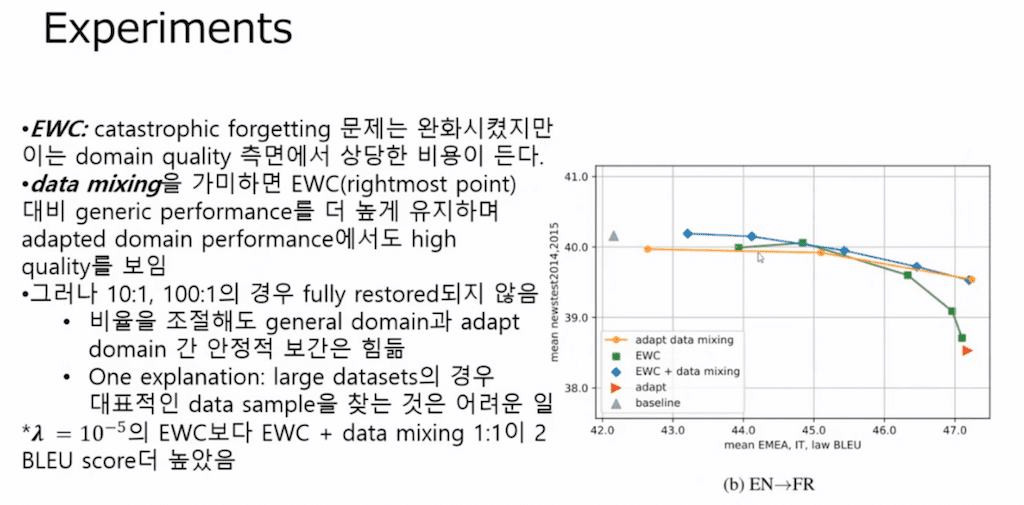
Elastic Weight Consolidation 방법만 도입을 했을 때는 초록색 선을 보시면 catastrophic forgetting 문제는 완화시켰는데 domain 퀄리티 측면에서는 상당한 비용이 드는 것을 확인을 할 수가 있었습니다.
초록색 선을 보시면 여기에서 오른쪽으로 갈수록 람다 값이 감소하게 됩니다. 여기가 10 ^ - 1 그리고 여기가 10^-2, 10^-3,4,5까지 람다 값을 감소시키면서 뒤에 EWC의 vector 텀이 붙는 가중치를 적게 주면서 학습시킨 부분입니다.
그래서 텀의 비율을 줄였을 때 그 값을 확인을 해 보면 람다 값이 적어질수록 generic domain에 대해서 성능은 상당히 점점 떨어지는 것을 확인을 할 수가 있습니다.
그리고 트레이닝과 target domain에 비율을 변화를 시키면서 학습시킨 게 주황색 선입니다. 주황색 선을 보면 오리지널과 target domain의 비율이 100:1, 여기는 10:1 그리고 여기는 1:1로 학습시킨 부분입니다.
원래 domain 데이터셋이 워낙 generic에 비해서 작기 때문에 1:1이 여기에서 generic의 비율이랑 target domain이 1:1이고 그 이하로 내려가는 부분 학습을 시키지 않았습니다. 여기서 Data mixing을 보시면 target domain이랑 1:1로 학습시켰을 때 target domain에 대한 성능이 당연히 높아지는 것을 확인할 수 있었고 그리고 generic에 대해서는 살짝 떨어지는 것을 확인을 할 수가 있었습니다.
그리고 각각의 성능을 비교를 해보면 여기가 람다가 10^-5일 때 EWC 실험값보다 EWC랑 Data mixing을 했을 때 target domain이랑 1:1일 때 그때 값이 2 스코어나 더 높았다는 것을 확인을 할 수가 있습니다.
그래서 EWC만 적용하는 것보다 Data mixing이랑 EWC 기법을 같이 적용을 하는 게 더 성능을 향상시키는 방법이라는 것을 확인할 수가 있었습니다.
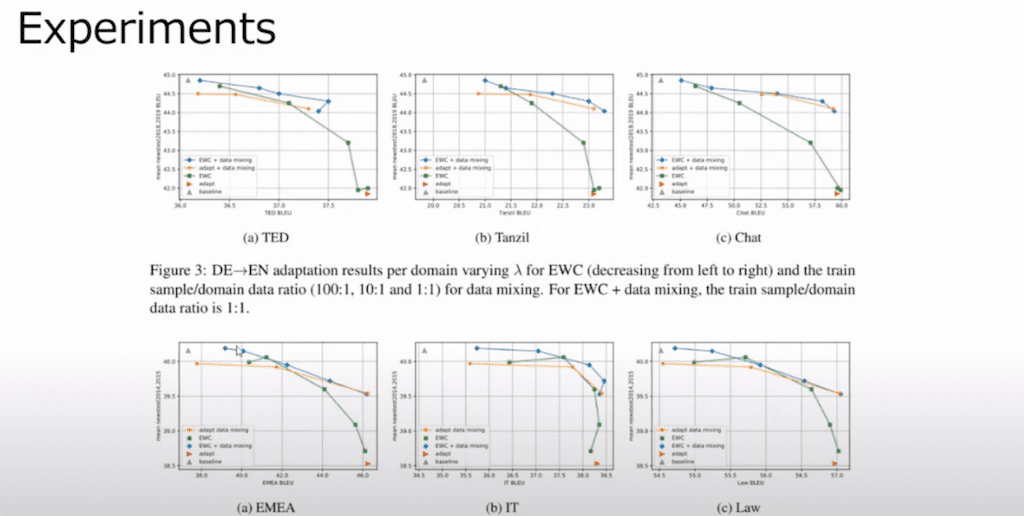
이 데이터셋들은 각각의 데이터셋에 adaptation을 시킨 결과입니다.
여기에 트렌드가 거의 다 일정하게 보인다 라는 것을 확인할 수가 있습니다.
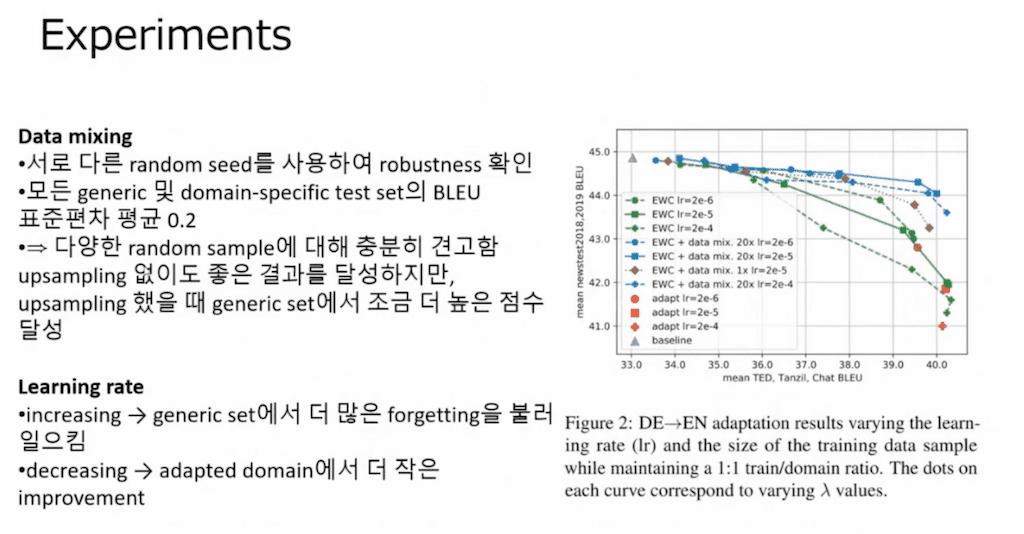
두 번째 실험 같은 경우에는 Data mixing의 비율이랑 learning rate를 조절해 가면서 이 데이터에 모델의 성능을 평가를 한 부분입니다.
당연하게도 learning rate이 클수록 catastrophic forgetting 현상이 더 크게 일어났고 learning rate를 작게 할수록 catastrophic forgetting은 적어졌지만 adapted domain에서 성능 향상이 더 적은 것을 확인을 할 수가 있습니다.
그리고 Data mixing을 여러 번 random sampling의 seed를 바꿔가면서 robustness를 확인을 했고, 이 값을 통해서 어쩔 때는 잘 나오고 어쩔 때는 못 나오는 게 아니고 다양한 random sampling에 대해서도 비슷한 성능의 결과가 나오는 것을 볼 수가 있었습니다.
up sampling이 없을 때도 좋았지만 up sampling을 했을 때 generic 데이터셋에서 좀 더 높은 점수를 얻었다는 것을 확인을 할 수가 있었습니다.




댓글