안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Efficient Passage Retrieval with Hashing for Open-domain Question Answering(BPR)’입니다. 짧게 BPR이라고 불리고 있는 논문입니다
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Efficient Passage Retrieval with Hashing for Open-domain Question Answering(BPR)’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/ESzmoZU-QfQ)
오늘 발표 내용의 목차는 다음과 같습니다. Passage Retrieval이 뭔지 일단 간단히 설명드리고 선행 연구 DPR에 대해서 간단히 설명드린 다음에 논문의 주제인 BPR과 그다음에 실험한 결과에 대해서 같이 이야기해보도록 하겠습니다.

Passage Retirieval은 우리가 query라고 하는 게 일단 질문을 하나 던지면 질문을 받는 시스템이 있습니다. 그 시스템을 보통 Retrieval 시스템 이라고도 하고 검색 엔진이라고도 합니다. 그래서 일단은 그 특정 데이터베이스에 모아져 있는 데이터 중에서 그걸 색인하는 과정을 Retrieval라고 하고 Indexing이라고도 불리는데 시스템 안에서 가장 검색어와 유사한 Passage를 찾습니다. Retrieval Passage라고 해서 이런 과정을 거치고 있습니다.

디테일하게 보겠습니다. 예를 들어 NFT라고 검색어 하나를 Retrieval 시스템에서는 우리가 그동안 데이터베이스를 모아둔 위키피디아라든가 나무 위키라든가 그다음에 웹에서 각종 크롤링되었던 document를 메모리에 올려놓고 색인합니다. 색인하면 지금과 같은 결과가 나옵니다. NFT 개념편, 업비트에서 관련 주요 동향 등등 NFT와 가장 유사한 document를 랭킹 해서 둔 시스템이라고 볼 수 있습니다.

조금 더 디테일하게 보면 Passage Retrieval 시스템에서는 Open domain이라는 거는 domain에 국한되지 않는 시스템을 말합니다. 그래서 방금 말씀드렸던 것처럼 NFT가 될 수도 있고 최근에 축구경기, 스포츠라던가 각종의 주제들이 다양하게 섞여 있는 데이터베이스를 Question Answering 할 때 Open domain QA라고 합니다.
그런데 다르게 구성도 할 수 있습니다. 지금처럼 Retrieval 시스템과 데이터 베이스를 indegration 해놓고 query를 받는 시스템과 그다음에 실제로 specific 한 Question을 던지는데 실제에 대한 document 뿐만이 아니라 정답을 내보내야 되는 경우가 있습니다.
지금 저희가 많이 쓰고 있는데 챗봇 같은 경우가 그런 경우인데 뒷단에는 MRC 모델들이 붙어가지고 거기서 QA를 수행을 해주는 값을 합니다. 대부분 MRC라고 하는 거는 사실 간단하게 말하면 기계 독해 모델입니다. 보통 많이 얘기하는 스쿼드 라든가 koquad라는 그런 대회도 있습니다. 그런 모델들은 MRC 모델이라고 불립니다.

그래서 지금 보고자 하는 부분은 Retrieval 쪽이라고 해서 Indexing 하는 부분이라고 보시면 됩니다. Reader는 이 실험에서도 당연히 성능 평가하기 위해서 Reader를 얼마나 잘 읽었는지도 평가를 해야 되기 때문에 기본적으로 큰 세팅 없이 간단한 Reader 모드로만 붙여놓고 실험을 했기 때문에 앞에서 제안하는 BPR과 DPR 모델인 Retrieval 쪽에서 논문이 제안됐다고 보시면 될 것 같습니다.
그래서 조금 더 디테일하게 보면은 query와 Passage가 같이 들어왔을 때 그걸 인코딩해주고 그다음에 similarity 함수들 많이 있습니다. 그런 것도 랭킹을 해서 각 상단에 Top-k개를 몇 개 뽑아 놓고 그걸 가지고 MRC 한다고 보시면 됩니다.

지금 소개해 드리는 논문은 DPR이고 BRP의 이전 선행 연구인 SOTA를 기록했던 Open domain QA에서 많이 사용되는 Retrieval 모델입니다.
Dense Passage Retrieval이라고 해서 일단은 각각의 Passage와 질의를 간단하게 서로 다른 독립적인 로딩된 모델로 여기서 BERT를 사용을 했는데 BERT로 인코딩을 해줍니다. 그러면은 continuous vector로 768개 dimension을 가지고 있는 Continuous vector로 바꿔 줍니다. 이것을 서로 내적 하면 결국 유사한 걸 찾습니다. 유사한 것 중에서 스코어가 가장 높은 relevance 스코어의 document Index를 뽑는 과정을 거칩니다.

DPR 같은 경우는 문제가 하나 있습니다. 일단은 말도 안 되는 메모리를 사용을 해야 되는데 지금처럼 예를 들어서 Continuous vector를 float로 저장을 해놓고 소수점이니까 그걸 총 768개 dimension에 모델 아웃풋을 뽑아놓고 그거 하나 Passage당 큰 사이즈가 3072 byte 정도 됩니다. 그러나 이것이 한 Passage니까 예를 들어서 2100만 개의 위키피디아 document를 메모리에 올려놓고 Indexing을 해야 된다고 하면 여기에 2100만을 곱해야 됩니다. 그러면 실제로는 65GB가 될 거고 그래서 65GB를 스토리지가 아닌 메모리에 상주해놓고 사용한다는 문제점이 있습니다.
그래서 나오게 된 게 BPR입니다.

메모리 문제가 있기 때문에 BPR이 나왔는데 일단 BPR은 DPR에서 좀 더 확장된 개념입니다. 가장 크게 보고 있는 키포인트는 hash 알고리즘을 써서 binary vector로 바꿔주는 과정을 거치고 있습니다. 그리고 두 번째는 Two stage approach를 사용을 했는데 결국은 두 개 목적함수를 각각으로 수행을 해서 최종적으로 마지막에 하나의 모델로 학습을 하는 과정이라고 보시면 될 것 같아서 그중 하나가 candidate generation 수행하는 게 있고 두 번째는 re rank 수행하는 두 가지 테스크도 학습한 모델이라고 보시면 될 것 같습니다.

다시 DPR로 돌아와서 Passage랑 query를 BERT로 바꿔준 다음에 유사도를 구했습니다. 그래서 일단 전제는 서로 다른 BERT입니다. 서로 독립적인 BERT 모델로 인코딩하고 이것을 내적을 합니다. 그리고 TOP-k Passage를 뽑기 위해서 가장 가까운, 주변에 분포하는 그런 Continuous space 안에서 찾는 알고리즘을 사용해 가지고 찾습니다.
방금 말씀드렸던 것처럼 최소 2100만 개 document를 상충시키려면 65GB 사용되기 때문에 큰 문제가 있습니다.

BPR 같은 경우는 지금처럼 좀 다른 스텝을 가지고 있습니다. 일단 앞단에서는 query encoder랑 Passage encoder가 들어오는 것은 동일합니다. 마지막 encoder의 마지막 단의 layer는 hash layer를 넣어놓고 데이터를 바꿔주는 부분이 있습니다. 이 부분은 sign function으로 만들어져 있습니다.
왜 sign function인지는 sign함수가 0과 1로 구분되는 함수이기 때문에 sign function인데 sign function을 그대로 neural 네트워크에 사용할 수 없는 이유는 역전 파할 때 역전파가 안 되기 때문에 다른 테크닉을 써서 수행을 합니다.
그다음에 hash layer를 거치면 binary로 바뀌는 코드로 아웃풋이라고 그 다음에 한쪽으로는 hamming distance를 구해가지고 가장 유사한 애들만 candidate를 뽑는 거를 candidate generation 이라합니다. 그 다음에 Passage랑 실제 query랑 유사도를 비교를 해가지고 다시 또 랭크를 조정하는 과정이 있습니다.

그래서 일단은 hash layer 같은 경우는 0보다 크면은 1이고 그렇지 않으면 -1입니다. back propagation은 적용할 수가 없기 때문에 scaled tanh function이라 그래서 scaled는 말 그대로 스케일 된 함수인데 결국 Hyperbolic tanh 함수로 값을 변경해줘서 최종적으로는 training step이 늘어나면 늘어날수록 결국은 1에 수렴하게 됩니다. 1과 -1에 수렴하게 되기 때문에 tanh Hyperbolic도 지금과 같은 scaled 된 상태로 계산을 해줍니다. 지금 수식을 보시면은 값만은 0.1로 고정되어 있습니다.
왜 0.1인지는 지금 보시는 것처럼 표가 나와 있는데 0.1이 가장 적합한 상태이기 때문이라고 보시면 될 것 같습니다. 그리고 베타는 말 그대로 training step이 돌아갈 때마다 증가하는 값이라고 보시면 될 것 같습니다.

다시 돌아와서 candidate generation은 hamming distance를 구해서 서로 다른 백터를 hamming distance로 구합니다.
hamming distance는 간단히 말씀드리면 예를 들어서 총 10개의 값을 갖고 있는 array가 있습니다. vector이고 각각 사이즈가 같아야 됩니다. 각 Index 마다 서로 다른 값이 몇 개가 있는지 계산하는 게 hamming distance인데 숫자가 당연히 크면 클수록 유사하지 않을 거고 숫자가 작으면 작을수록 완전히 일치할 수 있는 알고리즘이라고 보시면 될 것 같습니다.
그래서 hamming distance를 둘 다 binary 코드로 계산을 해서 어떤 특정 값으로 바꿔준 다음에 이걸 가지고 지금처럼 loss를 구해 줍니다. 그리고 마지막에 플러스 Alpha는 2.0입니다. 이것도 논문 어펜딕스에서는 여러 개의 알파를 넣고 학습을 시켜봤다고 합니다. 그런데 숫자를 여러 개 넣었을 때 optimize라든가 여러 실험에서의 set up 하기에 가장 적절한 값이 2.0이라고 주장합니다.
이렇게 해서 한 개 loss function을 가지고 학습을 합니다.

그다음에 두 번째로는 re rank입니다. 조금 다른 게 두 개의 binary 가 아니고 기존의 query BERT에서부터 뽑아낸 continous vector랑 Passage에 binary Code를 가지고 Inner Product 해서 구해 줍니다. 그래서 Inner Product 구해준 값을 가지고 이 차이를 가지고 학습을 한다고 보시면 됩니다.

그러고 나서 두 개를 합한 함수가 최종적인 전체 BPR 모델의 최종 목적함수라고 보실 수 있습니다.
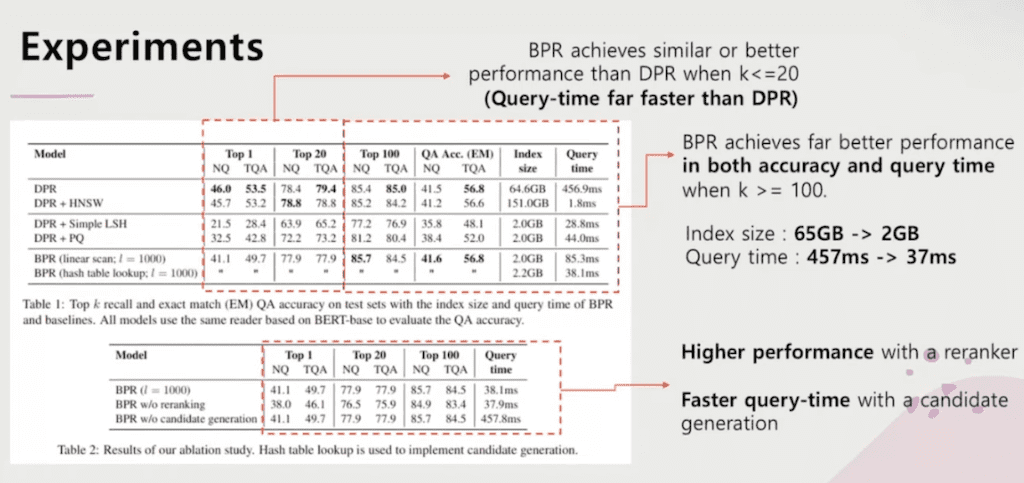
실험입니다.
가장 베이스라인 모델이었던 DPR과 비교했던 논문입니다. 그래서 일단은 지금 Top-k가 20개 이것도 하이퍼 파라미터인데 총 candidate를 20개 이내로 뽑아서 실험을 하는 데이터셋에서는 DPR과 비교했을 때 성능은 매우 비슷한 반면에 실제로는 한번 수행하는데 마다 41초가 걸렸던 게 BPR 같은 경우는 거의 걸리지 않았습니다. 그래서 상당히 Retrieval 하는 시간을 많이 단축시켰다고 볼 수 있습니다.
그다음에 k가 커졌을 경우에는 이 차이가 더 분명해집니다. 그래서 성능도 더 좋아지고 그 다음에 query 타임도 매우 빠르게 개선되는 모습을 볼 수 있었습니다. 그리고 Indexing 사이즈가 65GB가 아니고 2GB에서만 해서도 충분히 비슷한 성능을 낼 수 있었습니다. 그 다음에 질의 시간도 약 457초에서 37초로 많이 단축된 걸 볼 수가 있습니다.
그리고 Ablation study입니다. candidate generation이랑 re ranker를 넣었다 뺐을 때 차이점인데 확실히 있다 없다의 차이점은 확실히 분명합니다. 그래서 re rank를 넣지 않으면 성능이 떨어지고 넣었으면 성능이 늘어납니다. candidate generation을 했을 때는 당연히 candidate 된 Passage을 먼저 골라주기 때문에 당연히 query 타임이 훨씬 빨라진 상태에서 리딩을 할 수 있는 그런 조건을 만족했기 때문에 query 타임이 매우 빨라진 것을 볼 수가 있습니다.

그리고 Experiments 하나 더 있습니다. 기존의 다른 모델들이 RAG라는 것과 FiD라는 거를 비교했습니다. RAG랑 비교했을 때는 파라미터도 거의 라지 사이즈 기준으로는 3/4 수준인데 성능은 거의 유사하고 그다음에 FiD랑 비교했을 때는 베이스랑 라지 모델 모두 다 작은 모델 사이즈는 성능은 유사하게 나왔고 비교적 Electra 같이 모델이 큰 경우에서도 비교적 Retrieval 사이즈는 커졌으나 성능은 유사합니다. 그 다음 훨씬 기존의 라지 사이즈보다 훨씬 작은 사이즈 즉, 절반밖에 안 되는 그런 사이즈임에도 불구하고 성능은 매우 유사하게 나왔던 걸 볼 수가 있습니다.




댓글