안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Multitask Prompted Training Enables Zero-Shot Task’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Multitask Prompted Training Enables Zero-Shot Task’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/AttJCATMhRo)

먼저 목차입니다. 배경으로 Implicit multitask learning과 explicit multitask learning에 대해 소개해드리고 본 논문의 접근법을 소개하겠습니다. 그다음으로 T0의 일반화 성능 Prompt에 대한 Robustness에 대한 실험 결과를 소개해 드리며 마지막으로 T0와 가장 유사한 FLAN과 T0를 비교하면서 마치겠습니다.

최근 language 모델 연구들은 여러 NLP task에서 준수한 Zero-Shot 성능을 보입니다. Next word를 예측하는 Pre training 과정에서 언어 모델은 Pre training corpus내에 여러 task 즉, Multitask에 의해 학습되며 이로 인해 Unseen task에 대해 일반화할 수 있는 능력을 얻을 수 있습니다. 다만 이때 모델의 크기가 충분히 커야 하며 Prompt wording이 민감하다는 한계점이 있습니다.

다음은 Explicit multitask learning 연구입니다. Mishra et al는 Multitask Prompt training을 통해 Unseen task에 대하여 few-shot 성능을 개선한 연구를 제안해왔습니다.
왼쪽 아래 그림이 Natural Instruction 구조입니다. task에 대한 definition과 몇 가지 예시들이 주어집니다.
Wei et al에서는 Instruction 튜닝이라는 Multitask Prompt training을 통해 Unseen task에 대한 Zero-Shot 성능을 개선한 연구를 제안하였습니다. 본 연구와 상당 부분 비슷한 점이 있지만 차이가 있습니다.
그 차이점에 대해서는 마지막에 소개해 드리겠습니다.

Prompt를 통해 어떻게 일반화에 성공을 하였는가 이 질문에 대해 가장 주력이 되는 가설은 위와 같습니다.
모델이 Prompt를 task instruction으로 이해하게끔 학습하기 때문입니다. 이러한 성공은 Prompt의 Semantic meaningfulness. Prompt에 의존적이라는 문제점이 있습니다.
하지만 본 연구에서는 Prompt는 단지 Multitask training을 위한 Natural format 역할을 하는데 그친다고 주장합니다.

T0는 Unseen task에 대한 Zero-Shot 성능을 일반화하기 위한 모델로 이 그림을 보시면 framework를 이해하실 수 있습니다. 여러 task들에 의해 학습이 되면 Unseen task인 Natural language Inference를 Zero-Shot으로 수행하고 있습니다. 또한 T0는 입력과 출력이 모두 텍스트인 text to text 구조를 띄고 있습니다.

이는 T5에 기반하였기 때문입니다. T5는 오른쪽 그림과 같은 classification QA, Translation 등 여러 task들을 text to text로 접근하는 encoder decoder 구조의 Transformer 모델입니다.

더 구체적으로는 T0 Architecture는 Prompt training 형식에 맞게끔 LM-adapted T5를 사용했습니다. Prefix가 주어지면 모델은 주어진 Prefix에 대한 정답을 이어 쓰도록 학습합니다. 이 예시를 보시면 Translate English to German: That is good. Target이 prefix고 Das is gut이 target입니다.
Prefix에 대해서는 양방향 Attention을 사용하며 target에 대해서는 단 방향 Attention을 사용합니다.

다음은 데이터셋입니다.
본 논문에서는 62개의 NLP 데이터셋을 12개의 task로 분류하여 사용했습니다. Unseen task에 대해 성능을 평가하기 위해 8개 task로 학습 후 나머지 Held-out task로 성능을 평가했습니다.
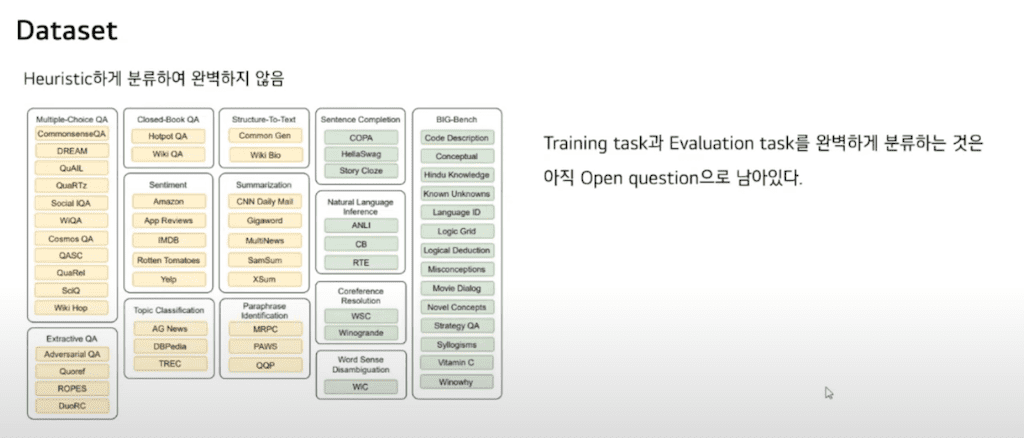
이 분류는 Heuristic 하게 분류하여 완벽하지 않습니다. 사실은 training task와 Evaluation task를 완벽하게 분류하는 것은 아직 Open question으로 남아있다고 합니다.

Held-out task입니다. 이때 Natural language Inference에 대해서 사람은 NLI 문제를 직접 학습하여 풀지 않고 기존에 있는 지식들을 위해 추론합니다. 이와 같이 language 모델의 성능 평가하기 위해서 NLI task를 explicit 하게 학습하지 않았습니다. 나머지 task들도 마찬가지로 같은 이유로 training task에서 제외하였습니다.
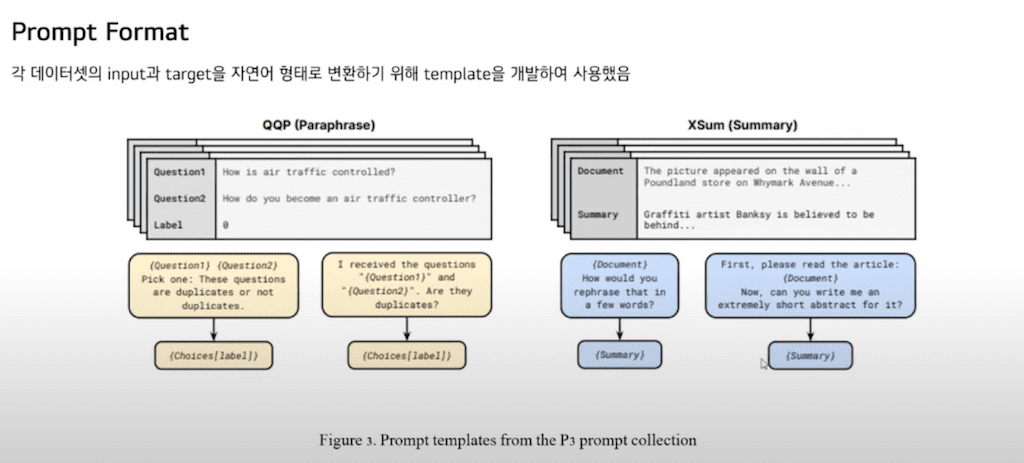
Prompt Format입니다. 각 데이터셋에 Input과 target을 자연어 형태로 변환하기 위해 template를 각 데이터셋당 여러 개씩 개발하였습니다. 이 그림에서 왼쪽 회색이 기존 데이터셋이고 그 아래 여러 개의 template이 존재합니다.

template 예시입니다. 이 task는 co reference로 He와 Mark가 동일 인물인지 묻고 있습니다.
He refer to Mark? Yes or no? He they mean Mark. Yes or no? 와 같이 다양한 문어체의 자연어 Prompt를 생성할 수 있습니다.
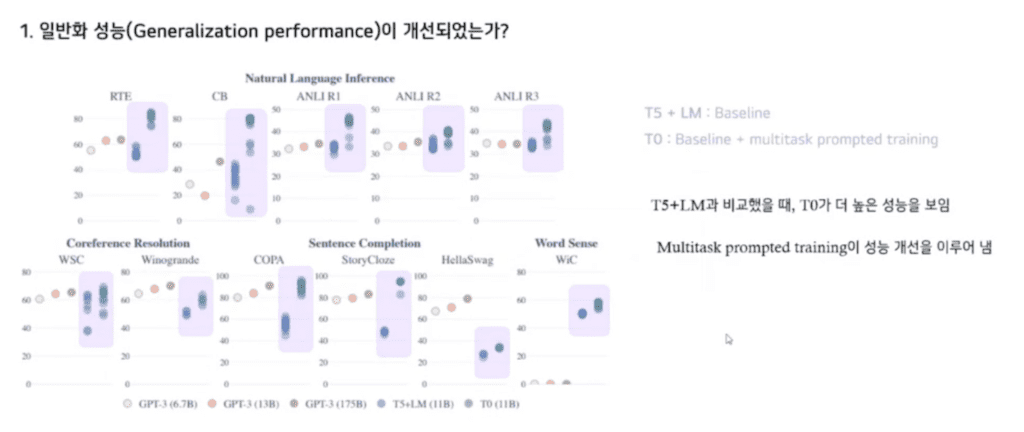
본 연구에서는 그 두 가지 질문을 중점으로 실험을 수행했습니다.
먼저 첫 번째로 정말로 Unseen task에 대한 성능을 일반화할 수 있는가에 대한 실험입니다. Held-out task에 대해서 실험을 수행했습니다. 각 점은 Evaluation Prompt에 대한 성능입니다. T5 LM은 LM adapted T5로 베이스라인 모델입니다. LM adapted T5에 비해 T0가 더 높은 성능을 이루는 것을 보아 Multitask Prompt의 training이 성능 개선을 이루어 냈다는 것을 알 수 있습니다.
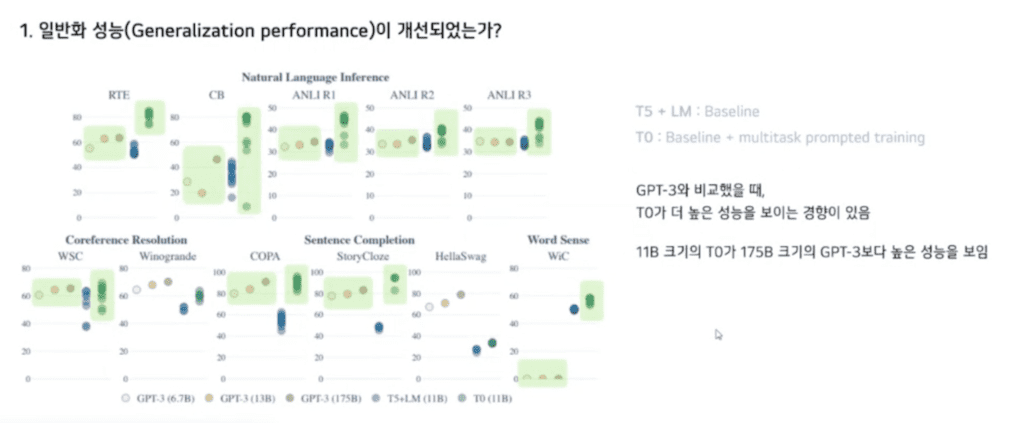
GPT-3와 비교를 했을 때 T0가 더 높은 성능을 보이는 경향이 있습니다. 이때 주목할 점으로 11B T0가 그의 10배에 달하는 GPT-3보다 더 높은 성능을 보이는 것을 확인할 수 있습니다.
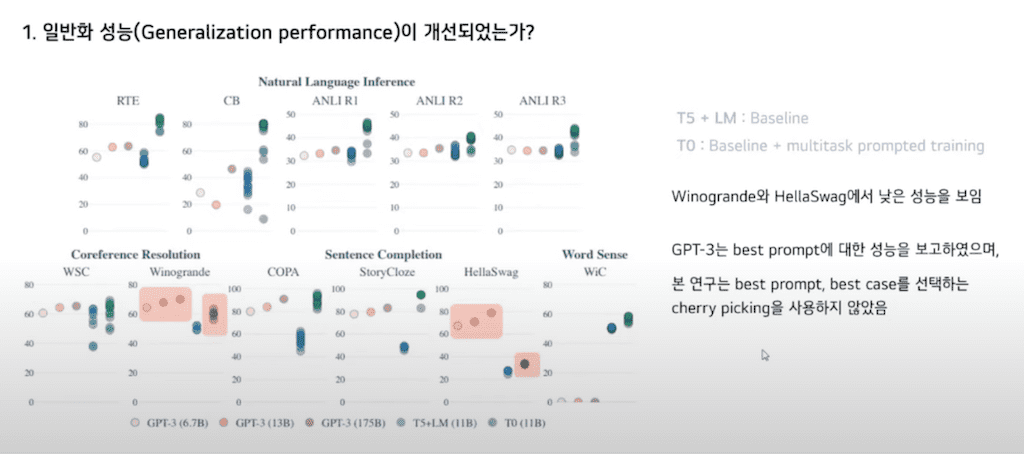
두 개 task에 대해 낮은 성능을 보이는데 이에 대해서 저자들은 GPT-3는 validation set 성능에 따른 베스트 Prompt에 대한 성능을 보고 하였지만 연구에서는 best Prompt, best case를 선택하는 cherry picking을 사용하지 않았기 때문이라고 밝히고 있습니다.
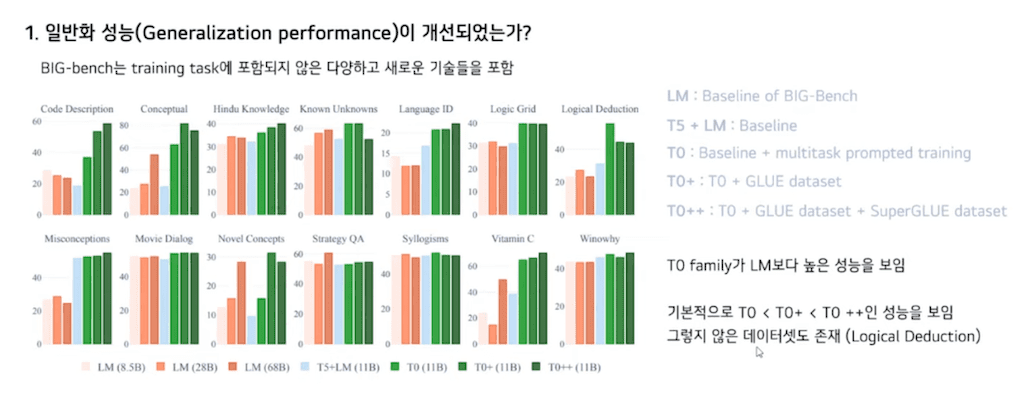
다음은 BIG-bench에 대한 성능입니다. BIG-bench는 training task에 포함되지 않은 다양하고 새로운 기술들을 포함하고 있습니다. 여기서 LM은 BIG-bench에서 제공하는 baseline입니다. 초록색의 T0 family가 LM보다 더 높은 성능을 보이고 있습니다. 또한 기본적으로 T0보다 T0+ 그보다 T0++가 더 높은 성능을 보입니다.
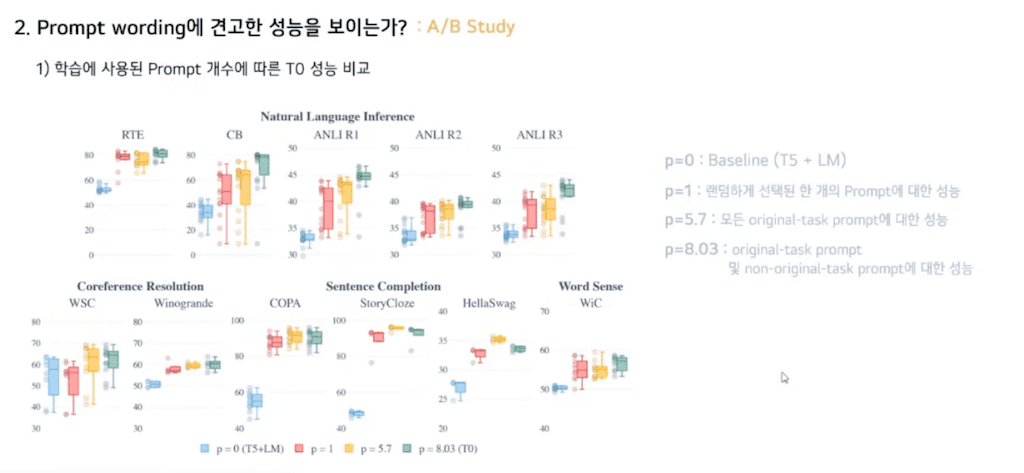
다음 질문으로 Prompt wording에 대해 견고한가에 대한 실험입니다. 이에 대해 Ablation study를 수행하였습니다. 먼저 Prompt 개수에 따른 성능 비교입니다.
p=0인 경우는 Prompt training을 수행하지 않은 경우로 baseline(T5 + LM)입니다.
p=1인 경우는 랜덤 하게 선택된 하나의 Prompt에 대해 학습하는 경우입니다.
p= 5.7인 경우는 모든 오리지널 task Prompt에 대한 학습한 경우로 각 데이터셋당 Prompt가 여러 개 있는데 그것에 대해 평균값을 낸 것입니다.
p=0.03인 경우는 original 및 non original task Prompt에 대한 학습한 경우입니다. 여기서 non original task Prompt는 예를 들어 Summary가 주어지고 그에 대한 도큐먼트를 출력하라와 같은 task에 대한 Prompt입니다.
p=8.03인 경우일 때가 본 논문에서 제안한 T0입니다.

평가 지표로 중앙값 성능과 IQR를 사용했습니다. Prompt의 개수가 증가함에 따라 중앙값과 spread가 개선되는 것을 확인할 수 있습니다.
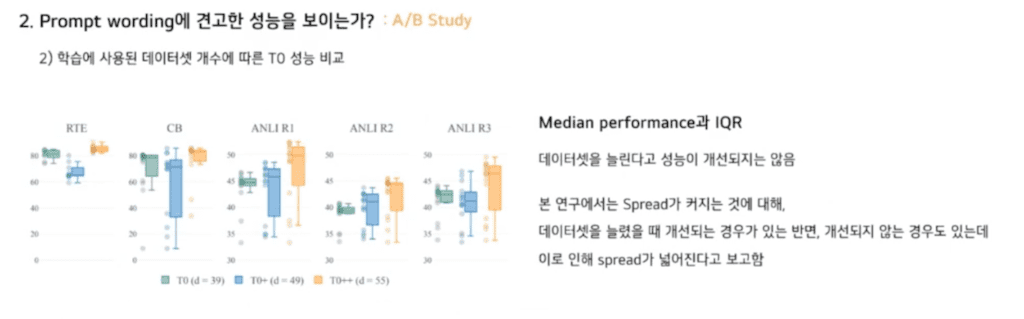
다음은 데이터셋 개수에 따른 성능 비교입니다. 이때 Prompt의 개수는 고정되어 있습니다. IQR이 T0에서 T0+로 갈 때 T0+에서 T0++로 갈 때 IQR이 널뛰거나 중앙값이 낮아지는 등 데이터셋을 늘린다고 성능 개선이 이루어지지는 않았습니다.
연구에서는 spread가 커지는 것에 대해서 데이터셋을 늘렸을 때 개선이 되는 경우도 있는 반면 개선이 되지 않는 경우도 있는데 이로 인해 Spread가 넓어진다고 보고 하였습니다.
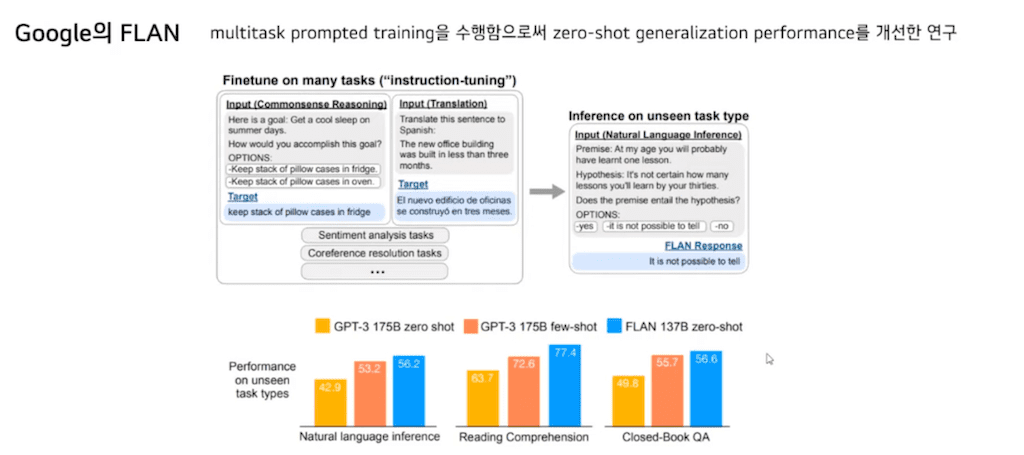
마지막으로 구글의 FLAN입니다. Multitask Prompt의 training을 수행함으로써 Zero-Shot generalization performance를 개선한 연구로 T0와 상당히 유사한 연구입니다.
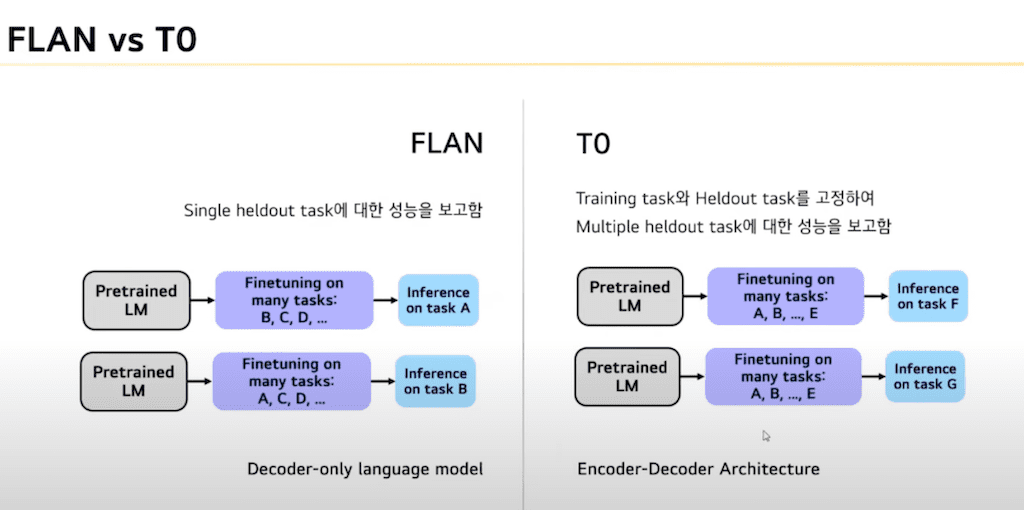
이를 비교했을 때입니다.
먼저 FLAN 연구에서는 Single heldout task에 대한 성능을 보고했으나 T0는 Multiple heldout task에 대한 성능을 보고하였습니다. 그림을 보시면은 Fine tuning 할 때 A B C D 등의 task들이 있을 때 FLAN는 task를 제외한 나머지 task로 학습을 시킨 후 나머지 하나의 싱글 heldout task에 대해서 성능을 보고 했으면 본 연구에서는 training task와 heldout task를 고정하고 training task에 대해서 학습을 하고 나머지 Multiple heldout task에 대해서 성능을 보고하였습니다.
또한 FLAN은 Decoder only language 모델로 GPT3와 비슷한 모델입니다. 본 T0는 encoder decoder Transformer에 기반한 모델입니다.
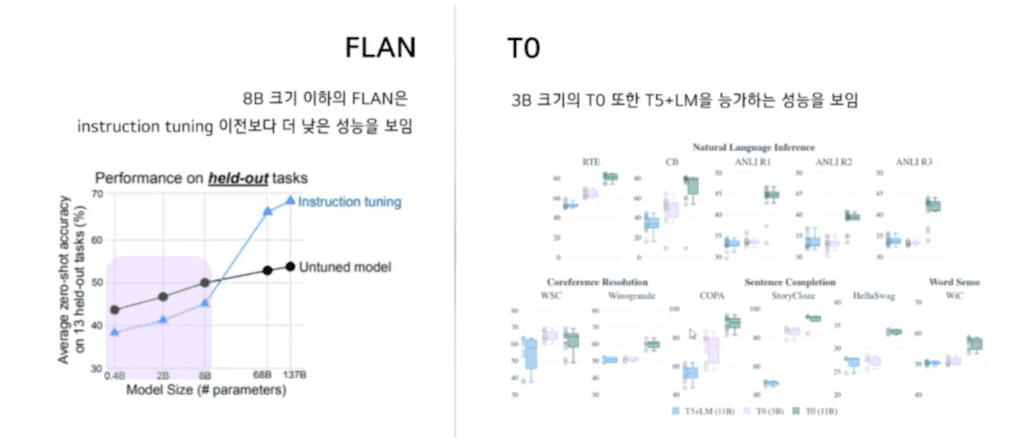
FLAN의 실험 결과에서는 8B 크기 이하의 FLAN instruction tuning 이전보다 instruction tuning을 했을 때 이전보다 더 낮은 성능을 보이는 것을 알 수 있습니다. 그에 비해 T0는 3B 크기의 T0 또한 튜닝을 하기 전 T5+LM을 능가하는 성능을 보이고 있습니다.
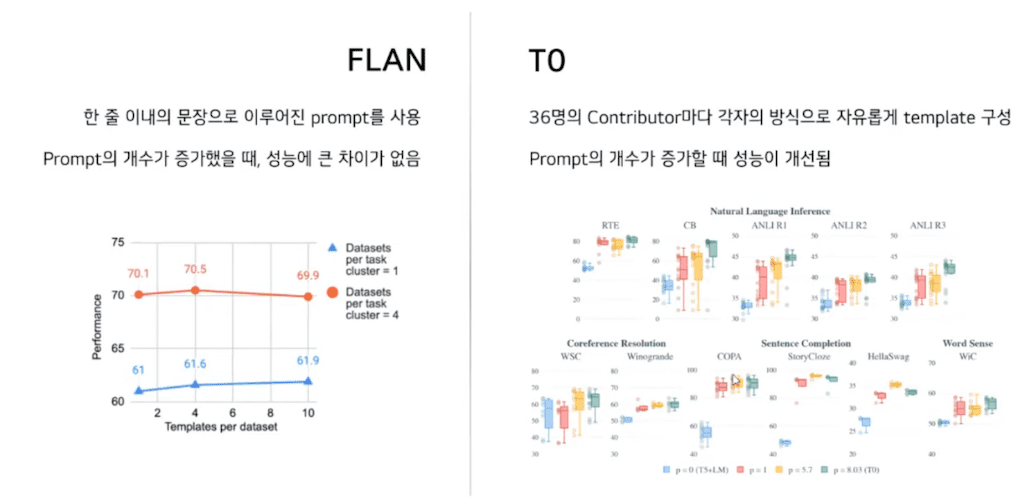
FLAN의 Instruction은 한 줄 이내에 문장을 이루어졌습니다. 이로 인해 Prompt의 다양성을 확보할 수 없고 Prompt의 개수가 증가했을 때 성능에 큰 차이가 없었습니다. 그에 반해 T0는 36명의 contributor마다 각자의 방식으로 자유롭게 Template을 구성하였고 이때 Prompt는 영어를 알 수 있는 사람이라면 누구나 이해할 수 있는 문법적으로 완성도가 있는 그런 Prompt로 각각의 Contributor 마다 자유로운 방식으로 Prompt를 제작했다고 설명하고 있습니다. 아까 실험 결과와 같이 Prompt의 개수가 증가할 때 성능이 개선되는 것을 확인하였습니다.

마지막으로 contribution을 정리한 것입니다.
본 연구에서 주력으로 내세우고 있는 가설은 Massively Multitask Prompt의 Fine tuning이 Zero-Shot 일반화 성능을 개선한다라고 주장하고 있습니다. 그에 대한 모델로 T0를 제안하였습니다.
또한 제안한 framework의 Robustness를 증명하기 위해 Ablation Study를 제공하였습니다.
본 연구에서 사용한 Prompt 및 Template을 공개함으로써 앞으로 있을 연구에 주력이 될 자료를 공개하고 있습니다.




댓글