안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Rainbow: Combining Improvements in Deep Reinforcement Learning’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Rainbow’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/oC1AOIefjT8)
오늘 발표드릴 논문은 Rainbow라는 2018년도에 딥마인드에서 발표한 논문입니다. 이 논문은 Deep Q learning이 발표된 이후에 Agent의 성능을 향상시키기 위해서 여러 EXTENSION들이 추가적으로 발표가 됐는데, 이 논문은 EXTENSION 들을 모두 다 integration 해서 Agent를 구성을 했을 때 기존에 발표됐던 Deep Q learning Agent보다 월등한 성능을 가질 수 있다는 것을 보인 논문입니다.

우선 백그라운드로 기존의 Deep Q learning에 대해서 설명드리겠습니다. 강화 학습의 목적은 Agent를 훈련시키는 것입니다. 주어진 환경에서 state가 주어지고, 그것에 따른 At을 취했을 때 Rt를 얻는 구조를 갖습니다. 이 과정에서 Agent의 최대 목표는 Rt의 총합입니다. 다시 말해 시간이 지났을 때 Agent가 어떤 행동을 해서 얻은 Rt의 총합의 기댓값을 최대치로 만드는 것이 그 강화 학습의 목표입니다.
Deep Q learning은 state space 또는 action space가 굉장히 클 수 있습니다. 이러한 limitation을 극복하기 위해서 Deep learning구조를 도입을 해서 Deep learning 구조와 Q learning의 이론적인 배경을 합쳐서 복잡한 상황에 대한 Agent 훈련을 Deep learning 구조를 통해서 할 수 있다는 것을 보인 논문입니다. 그 과정을 2014년도에 발표된 네이처 논문을 기준으로 설명을 드리겠습니다. State가 주어지고 그 State는 네이처 논문에서는 아타리 게임을 진행을 할 때 나오는 영상의 프레임을 사용을 했습니다. 프레임이 Convolution Neural network를 통해서 계산이 되고, 최종적으로는 주어진 State와 주어진 At에 대한 Q value 즉, action state space(Rt)에서의 기댓값을 추론하는 모델을 발표를 했습니다.
주어진 St, At, Rt+1, St+1에 대한 조합이 replay memory buffer로 저장이 되고 이 학습의 과정에서는 replay memory buffer에 저장되어 있는 Agent가 겪은 상황들이 네트워크에 전달이 됩니다. 그다음 네트워크가 구할 수 있는 현재의 모델이 추론할 수 있는 Rt보다 더 나은 Rt를 가질 수 있게끔 학습합니다. 이 과정에서 Target network와 Online network가 나눠지게 됩니다. Online network를 통해서 St+1에 대한 At를 추론하고 Target network를 통해서 가질 수 있는 Rt의 추론을 하게 되고 둘 사이의 차이를 이용해서 모델을 학습을 하게 됩니다.

다음에 발표된 여러 EXTENSION들이 있는데, 논문에서 사용한 EXTENSION들은 여섯 가지가 있습니다. 먼저 Double Q learning의 개념입니다. Double Q learning의 개념은 훈련 과정에서 다음 At에 대한 추론을 할 때 Target network에서 다음 At를 추론합니다. Target network에서 At을 추론을 할 때 At이 가장 큰 Rt를 가지게끔 하는 과정에서 Rt가 overestimation 될 수 있습니다. 그래서 그것을 극복하기 위해서 At을 추론하니까 다음 스텝의 사용할 At을 뽑아내는 부분하고 Rt의 계산을 하는 네트워크를 분리해서 overestimation 되는 bias를 줄이고자 했습니다.

논문에서 사용한 두 번째 Extension입니다. Prioritized reply는 replay buffer에서 학습에 필요한 experience를 가져오는데 이 부분을 기존의 DQN에서는 random sampling을 해서 가져왔지만, experience를 Priority를 주고 뽑아서 학습을 할 경우에 더 효과적일 수 있다는 아이디어입니다. Priority는 주어진 상황에서의 Temporal Difference에 프로포셔널 하게 Priority를 줬을 때 학습 효율을 높일 수 있다고 설명하고 있습니다.
그리고 Multi-step learning은 기존 DQN에서는 다음 현재 주어진 St에서 바로 다음 스텝에 대한 Rt만을 가지고 학습했습니다. 여기에서 n 스텝 이후에 얻을 수 있는 Rt를 가지고도 학습을 진행할 수 있다는 개념입니다.

Dueling network의 개념은 기존 네트워크에서는 바로 q value를 inference 하게 되지만 q function의 구성이 원래 주어진 St에 대한 value function과 다음에 어떤 At을 취했을 때 가질 수 있는 advantage로 구성이 되니까 value에 대한 inference 하고, advantage에 대한 inference를 따로 할 수 있게 네트워크 구조를 바꾸고, 이 두 개를 활용을 해서 새로운 q function을 구성을 하면 더 나은 학습을 진행할 수 있다는 개념입니다.
Noisy Nets은 E-greedy policy에 따라서 다음 스텝에 대한 At을 정하게 됩니다. 그때 E-greedy policy에 의해서 탐험될 수 있는 limitation을 네트워크 구조에다가 linear 계산이 들어가는 부분에다가 Noise를 더해서 조금 더 나은 학습을 할 수 있게 도입을 한 개념입니다.

다음으로는 Distributional RL의 개념입니다. Distributional RL은 기존의 Q learning에서는 Rt의 expectation value를 구했다고 하면 Distributional RL에서는 Rt에 대한 Distribution을 구함으로써 우리가 학습을 진행할 수 있다는 개념입니다.
그래서 Reward Distribution을 정의를 하는 개념들이 필요합니다. 첫 번째로는 support vector z가 필요합니다. support vector z는 가질 수 있는 Rt 공간을 미니멈 값과 맥시멈 값, 몇 개의 vector 요소를 사용할 것인지에 대한 세 개의 hyperparameter로 구성되어 있는 공간입니다. 공간이 주어져있을 때 St와 At이 주어지면 특정한 support element에 대해서 probability mass를 정의를 할 수가 있습니다. Distribution은 probability mass의 구성으로 이루어져 있고 이 개념을 바탕으로 해서 현재 상태에서 다음 스텝으로 넘어갈 때 어떤 optimal policy가 있다고 한다면 이 optimal policy에 대한 optimize를 진행해야 되기 때문에 Target Distribution에 대한 구성을 Q값이 아닌 Rt의 Distribution으로 구성을 할 수 있다는 개념입니다. Target Distribution을 optimize 하기 위해서는 DKL를 사용하는데, 그 공간에 대한 projection이 필요하게 됩니다.

위에서 설명한 EXTENSION들을 모두 다 기존의 Deep Q learning의 프레임에다가 추가를 하였습니다. 그래서 네트워크가 inference을 하는 것이 Q값이 아니고 Distribution이 되고 다음에 Multi step learning으로 가기 때문에 Multi step Distributional loss를 사용을 합니다.
마찬가지로 Double Q learning에서 나왔던 At을 inference 하는 부분과 Rt를 계산하는 네트워크가 디커플링 되어 있고요. 여기에서 Priority는 기존의 Priority를 계산할 때는 Temporal Difference를 사용을 했는데 여기에서는 Distributional을 쓰기 때문에 타깃 Distribution에 대한 DKL를 Priority로 사용을 하고 있습니다. 이 과정에서 마찬가지로 Dueling 네트워크 아키텍처를 활용해서 주어진 St에 대한 value function과 advantage stream 계산을 해서 네트워크를 구성했습니다.
마지막으로 모든 linear 계산층에다가 Noisy linear를 활용을 해서 Exploration을 하게 됩니다.

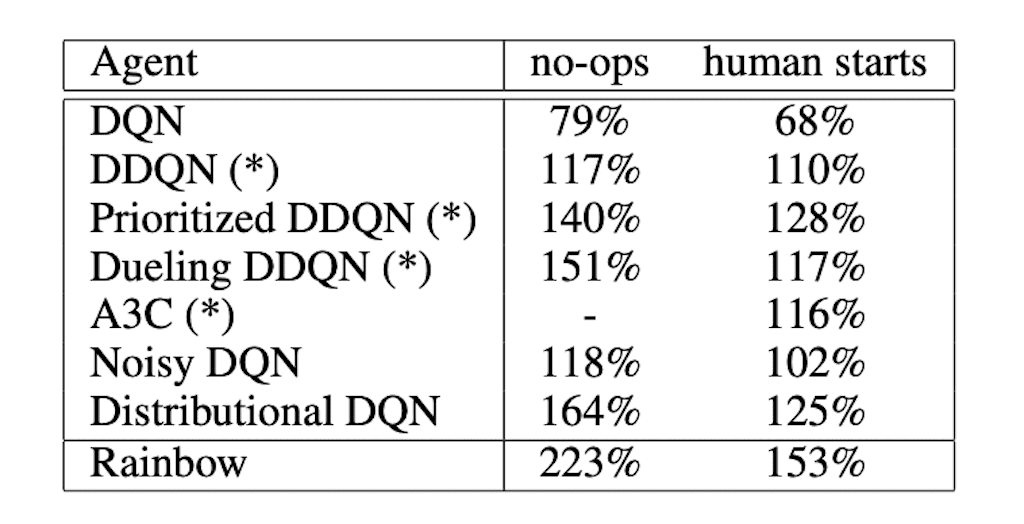
결과입니다. integration 된 Agent를 활용을 해서 기존에 발표됐던 결과들과 비교를 진행하였습니다. integration 된 Rainbow라는 Agent가 앞서 발표됐던 모든 Agent들을 능가하는 것을 확인할 수 있습니다. 이는 학습의 효율면에서도 굉장히 빠르게 학습을 하는 것을 확인을 할 수 있었고, 그리고 모든 다른 네트워크들 중에서 가장 높은 값을 월등히 능가하는 퍼포먼스를 보이는 것을 확인할 수 있습니다.

integration 된 Agent에서 특정 요소들이 빠졌을 때 얼마나 잘 퍼포먼스 하는지를 비교를 한 표입니다. 이 부분에서는 확실히 효율면에서는 거의 다 비슷한 부분을 보였습니다. 반면에 Distributional 원인이 빠졌을 때 최대 퍼포먼스를 낼 수 있는 부분이 전체적으로 줄어든다는 부분을 강조하고 있었습니다.

사람하고 비교를 해서 사람의 성능보다 20 퍼센트 정도 이상이 되는 게임에 개수를 나타내고 있는 표입니다. 사람의 퍼포먼스와 비교를 해서 상대적으로 이 정도의 퍼포먼스를 가질 수 있는 게임의 개수는 총 57개 게임을 가지고 테스트를 하였습니다. 그중에서 각각의 Agent들이 어느 정도의 퍼포먼스를 낼 수 있는지 비교했습니다. integration 된 Agent가 다른 모든 모델들보다 훨씬 더 많은 게임에서 우위를 차지하는 것을 확인할 수 있었고, 마찬가지로 특정한 요소들이 빠졌을 때 비교해보면 모든 요소들이 다 integration 되어 있을 때 퍼포먼스를 잘하는 것을 확인할 수 있습니다.

어떤 특정 요소가 빠졌을 때 특정한 게임에서 어느 정도의 퍼포먼스를 갖는지를 비교한 그래프입니다. 마찬가지로 전반적으로는 모든 요소가 다 들어가 있을 때 가장 퍼포먼스가 나은 것을 확인할 수 있습니다.

결론입니다. Deep Q learning과 여러 EXTENSION들에 대해서 리뷰를 진행했습니다. 그 결과 integration 된 Agent가 학습효율과 퍼포먼스에서 모두 다 월등히 다른 모델들을 능가했다고 결론을 지을 수 있습니다.




댓글