안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Self-training Improves Pre-training for Natural Language Understanding’입니다. 이 논문은 페이스북과 스탠퍼드에서 2020년에 발표한 논문입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' 중 ‘Self-training Improves Pre-training for Natural Language Understanding’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/9iJLzmrUN-8)

Self training에 대해서 간단하게 설명하고 넘어가겠습니다. Self training은 Semi supervised learning 중 하나입니다. Semi supervised learning는 데이터 중에 Unlabel 데이터와 label 데이터 두 가지 데이터를 사용해서 학습하는 방법으로 이 논문에서 사용하는 건 두 가지 방법이 있습니다.
첫 번째는 label 데이터로 학습된 Teacher모델을 사용해서 Unlabel 데이터에 labeling을 해주어서 label 된 데이터를 이용하여 Student 모델을 학습하는 과정입니다. 이 과정에 속하는 부분 중 하나가 Self training입니다. Self training은 Teacher 모델과 Student 모델을 학습시킬 때 Student 모델이 Teacher 모델보다 크거나 같은 경우를 말합니다. 반대로 Student 모델이 Teacher 모델보다 작은 경우를 Knowledge distillation이라고 합니다. Semi supervised learning 방법은 이미지 처리나 speech Recognition 분야에서 성공적으로 활용되고 있습니다.
두 번째 Semi supervised 방법은 자연어 처리에서도 잘 알려진 Pre-training으로 Unlabel 또는 label 데이터를 이용해서 데이터의 Auxiliary Task(큰 맥락) 부분을 학습하고 그 후로 label링 된 데이터를 사용해서 Fine-tuning을 해주는 과정을 거쳐서 학습합니다. 이 방법은 자연어 처리 부분에 큰 도약을 일으켰습니다.

이 논문이 연구되는데 배경이 된 논문들로는 Do pretraining and self training capture the same information? Or are they complementary?라는 논문이 있습니다. 이 논문은 이미지 처리 부분에서 Pre-training과 Self training을 합쳤을 때 더 나은 결과를 도출할 수 있다는 논문입니다. 그리고 Unsupervised Data Augmentation for Consistenct Training과 Self-training with Noisy student improves ImageNet classification 이 두 개의 논문은 Self training에 있어서 가장 중요한 건 Unlabel 데이터가 downstream task 데이터와 같은 In-domain 데이터가 있는 것이 얼마나 중요한지 연구된 논문입니다. In-domain은 데이터의 출처나 스타일이 같은 데이터를 말합니다. 예를 들어 downstream task 데이터가 경제 뉴스 데이터라면 경제와 연관된 문장들로만 구성된 데이터를 In-domain데이터라고 합니다. 이 연구에서는 In-domain데이터의 중요성을 이해하고 Self training의 중요함을 이해하고 자연어 처리 부분에서도 이미지 처리 부분과 마찬가지로 빈 도메인과 Self training을 이용했을 때 효율적인 결과를 얻기 위해서 Data Augmentation을 통해서 웹에서 크롤링한 문장에 In-domain데이터를 구축하고 Semi supervised learning을 통해서 기존 자연어 처리 분야의 효율성을 높일 수 있는지 대해서 연구했습니다.

이 논문은 크게 두 가지 섹션으로 나뉘어서 진행이 되는데 첫 번째가 Data Augmentation으로 웹에서 데이터를 수집해서 데이터 간의 유사성을 학습하고 label 데이터로 학습된 Teacher 모델을 사용해서 수집한 Unlabel 데이터에 labeling을 해줍니다. 다음 섹션은 Semi supervised learning 섹션으로 augment 된 데이터를 가지고 Self training을 포함해서 다양한 Semi supervised learning의 모델들에 학습시켜보는 과정을 통해서 In-domain데이터와 Semi supervised learning의 데이터가 얼마나 중요한지, 그리고 학습했을 때 얼마나 더 나은 결과를 나타내는지 연구하고 있습니다.

그러면 첫 번째 섹션인 Data Augmentation을 위해서 가장 필요한 건 웹에서 뉴스를 수집하는 과정입니다. 웹에서 다양한 도메인과 스타일의 문장들을 수집하는데 이를 Large-scale sentence bank라고 부릅니다. 많은 문장들을 가져오는 것의 중요함을 확인하기 위해서 약 5천 개부터 5억 개의 문장 개수를 비교해 봤습니다. 1억 개가 될 때까지는 문장의 개수가 늘어날수록 성능이 좋아짐을 확인할 수 있습니다. 하지만 5억 개가 되면 정확도가 더 이상 높아지지 않는데 이 논문에서는 문장의 개수가 과도하게 많아져서 다양성이 줄어드는 것으로 추측하고 있습니다.
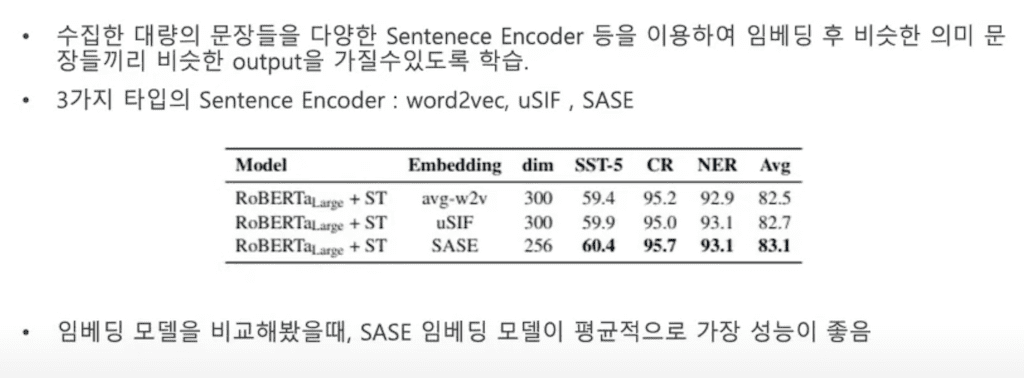
외부로 문장을 수집하게 되면 수집한 문장들을 embedding을 해 줘야 합니다. 이때 다양한 sentence encoder들을 사용해서 embedding을 해준 다음에 비슷한 의미의 문장들끼리 비슷한 벡터 값을 가질 수 있도록 학습합니다. 이때 사용하는 세 가지 embedding으로는 word2 vec, uSIF, SASE가 있습니다. embedding을 사용한 결과를 비교했을 때 다양한 task에서 평균적으로 SASE가 가장 성능이 좋은 것을 확인할 수 있습니다.
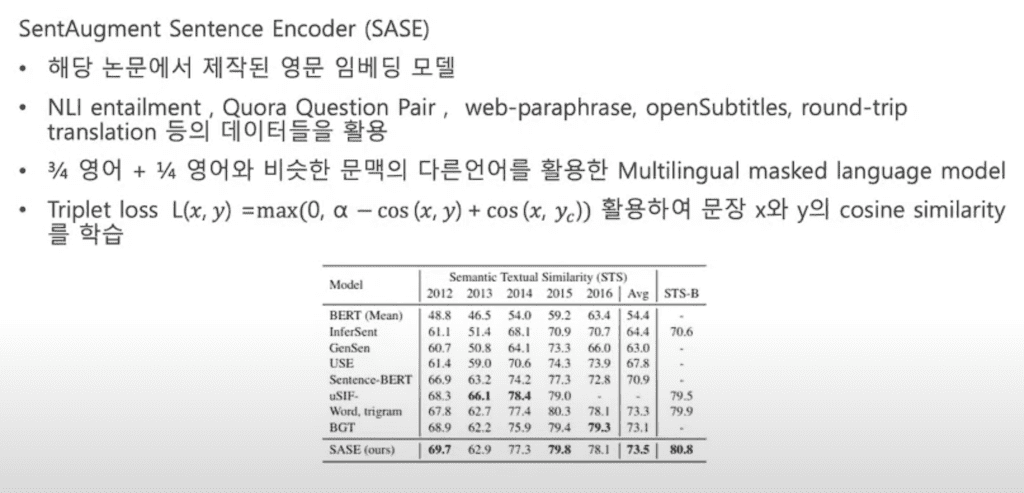
SASE는 이 논문에서 연구 및 발표된 embedding 모델로 SentAugment Sentence Encoder라고 합니다. embedding 모델은 NLI entailment - 연결된 문장 묶음, Quora Question Pair - 질문 및 답 문장 묶음, web-paraphrase - 웹에서 수집한 문장 묶음, openSubtitles - 영화 자막 묶음, round trip translation - 영화에서 다른 언어로 번역했다가 다시 영어로 번역하는 문장 묶음 등을 사용해서 4분의 3은 영어, 4분의 1은 영어랑 문맥이 비슷한 다른 언어를 사용해서 Multilingual masked language 모델입니다. 그리고 Triplet loss를 사용해서 세 개의 문장을 입력했을 때 비슷한 문장은 가깝게, 의미가 다른 문장을 멀도록 배치하도록 학습한 모델입니다.

Large sentence bank에서 원하는 Downstream task와 도메인이 같은 데이터 subset을 추출해야 하는데 이때 Downstream label 데이터를 사용합니다. Downstream이란 구체적으로 하고자 하는 문제를 말하고 예를 들어 개체명 분석 등이 있는데요. Downstream label 데이터에 같은 embedding 모델을 사용해서 embedding 해준 결과를 3가지 방법으로 Query를 사용합니다. 이때 Query로 사용한다는 건 labeling 된 데이터의 평균값을 Query로 두고 Query값과 Unlabel 데이터를 nearest neighbor를 통해서 In-domain sentence를 추출합니다. Query값을 만드는 데 사용한 세 가지 방법이 All-average, Label-average, Per-sentence average가 있습니다. All-average는 task embedding이 된 백터 값의 전체 평균을 말하고요. Label-average는 각 클래스당 벡터 값의 평균을 얘기하고요. Per-sentence는 각 task 데이터 안에 있는 embedding안에 문장별 평균값을 얘기합니다. 결과를 확인해 보면 테스크마다 다르지만 Label-average와 Per-sentence average를 Query로 사용했을 때가 All-average을 사용했을 때 보다 효과가 높은 것을 확인할 수 있습니다. 그래서 embedding 한 트레이닝 데이터셋에 nearest neighbor를 통해서 Unlabel 데이터에서 도메인이 같은 데이터 subset을 추출할 수 있습니다.

In-domain 문장 모음입니다. 문장들을 살펴보면 문장들이 원하는 도메인에 같은 도메인인걸 확인할 수 있습니다.

수집한 In-domain 데이터를 사용해서 Semi supervised learning를 진행했습니다. 이 논문에서 사용한 Semi supervised learning은 크게 3가지로 Self-training, Knowledge distillation, Few-shot learning이 있습니다. 그래서 Semi supervised learning 모델로서는 RoBERTa-Large 모델이 사용됐습니다.
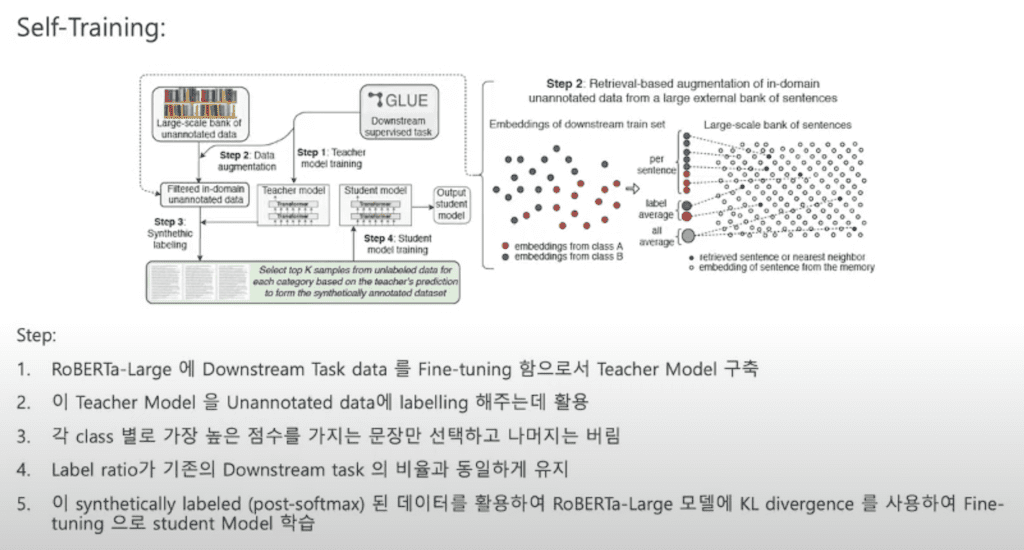
첫 번째로 사용한 Semi supervised learning은 Self training입니다. 순서는 RoBERTa-Large 모델에 downstream task 데이터를 Fine-tuning을 해줌으로써 Teacher 모델을 구축합니다. 이 Teacher 모델을 가지고 Unannotated 데이터에 labeling 해주는데 활용합니다. 이때 각 클래스별로 가장 높은 점수만 가지는 문장들을 선택하고 나머지는 버립니다. 그리고 기존에 downstream task와 새로 synthetically label 된 데이터를 같은 label ratio를 가질 수 있도록 유지합니다. 그리고 synthetically label 된 데이터를 사용해서 RoBERTa-Large모델에 KL divergence, 두 개의 데이터가 얼마나 다른지 비교하는 학습함을 통해서 Student 모델을 학습합니다.

synthetically label된 데이터를 합쳐서 1이 되는 post-softmax 또는 결괏값이 0과 1로 나타낸 discrete값을 label로 설정해서 Student 모델을 학습하는 결과를 비교했을 때 post-softmax 한 결과 값이 더 나은 경향을 가진다는 것을 알 수 있습니다.
그리고 Self training을 통해 얼마나 도메인을 잘 학습하고 결과가 잘 나오는지 확인하기 위해서 6개의 task에서 Self training과 In-domain Pretraining, 같은 도메인의 데이터로 Fine-tuning 한 결과를 비교했습니다. 결과적으로 Self training 한 결과가 In-domain-adaptation에 더 효과적이어서 6개의 task에서 평균적으로 높은 예측률을 가질 수 있는 걸 확인할 수 있습니다.

다음으로 실험한 Semi supervised learning은 Knowledge distillation입니다. Knowledge distillation은 Teacher 모델의 결과를 실험 모델에 학습시킬 때 softmax 아웃풋을 토대로 학습해서 더 적은 개수의 파라미터로 Student 모델이 Teacher 모델보다 작을 수 있도록 학습하는 모델입니다.
Knowledge distillation은 RoBERTa 모델을 사용했습니다. 이때 Large 모델과 small 모델을 사용해서 결과를 비교했을 때 Large 모델이 더 나은 결과를 가진다는 것을 알 수 있습니다.
data subset을 만드는 과정에서 training 데이터와 같은 양의 데이터를 사용할 때 이미 training 된 데이터를 한 번 더 사용하는 것과 랜덤 데이터를 선택해서 사용하는 것, 그리고 SASE를 사용해서 얻은 데이터를 사용한 것을 비교해 봤을 때, 랜덤 한 데이터를 사용했을 때 보다 SA(Sentence Augment)된 문장들과 그리고 Ground truth(labeling이 된 데이터)가 랜덤한 데이터를 사용했을 때 보다 더 뛰어난 것을 확인할 수 있습니다. 이로써 In-domain 데이터가 학습에 얼마나 중요한지 확인을 할 수 있습니다.
그리고 트레이닝 셋 보다 더 많은 양의 데이터를 랜덤 추출해서 쓰거나 또는 Augmentation 인코더 sentence를 사용해서 추출한 데이터를 사용한 걸 비교해 봤을 때 In-domain데이터를 사용한 sentence Augmentation 데이터가 모든 테스크에서 평균적으로 월등히 뛰어난 것을 확인할 수 있습니다.

마지막으로 사용한 Semi-supervised learning은 Few-shot learning 모델입니다. Few-shot은 labeling 된 데이터가 적은 환경에서 사용하는 Semi-supervised learning입니다. 각 label당 20개씩 트레이닝 데이터 샘플과 200개의 validation 데이터를 사용해서 Full shot setting과는 다르게 0과 1로 이루어진 discrete label을 사용하고 Fine-tuning 과정에서 데이터가 적기 때문에 Ground truth 데이터도 같이 사용합니다. 그리고 Data Augmentation을 기존의 데이터에 2배 or 3배로 학습시키고 Teacher 모델을 사용해서 synthetically labeling 해줍니다. 이 결과 Self training을 사용했을 때 예측값이 평균적으로 3.5% 상승함을 확인할 수 있습니다.

Conclusion입니다. 대부분의 자연어 처리 연구분야는 Unsupervised Pretraining에 집중되어 있지만, Self training을 사용함으로써 Unlabel 데이터를 활용하여 학습하기 효율적임을 증명하고 있습니다. Web 데이터로부터 In-domain 데이터를 추출하고 Pre-training 모델인 RoBERTa-Large 모델에 Self training을 접목시켜 6개 task에서 평균적으로 1.2% 예측률이 증가함을 확인할 수 있습니다.
그리고 Self training이 아닌 다른 Semi-supervised learning에서도 마찬가지로 3.5%, 2.9% 정확도 증가가 있었다는 걸 확인할 수 있습니다.




댓글