안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘Proper Reuse of Image Classification Features Improves Object Detection’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임'Proper Reuse of Image Classification Features Improves Object Detection’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/Ikg5Mx3ITh4)
이 논문은 실험논문이고 논문에 대한 어떤 내용보단 실험 위주의 논문입니다.

가장 기본적으로 알고 있는 방법이 Fine-tuning 방법입니다. Pre-train 된 weight가 있고 여기서 ResNet을 쓰고 있습니다. 거기에다가 어떤 목적을 위한 여기선 object Detector를 붙이고 나서 Fine-tuning을 하게 되면 Pre-train weight도 변경되고 추가된 Detector도 변경되는 게 일반적으로 가장 많이 쓰이는 방법이고 성능이 가장 좋다고 알려져 있습니다.

다음은 다른 방법입니다. 여기서는 Detector가 있는데 추가적으로 backbone을 붙일 때, ResNet을 붙일 때 Pre-train을 붙일 수도 있고 아니면 랜덤 하게 초기화할 수 있고 이렇게 해서 모델을 만든 다음에 training을 오래 하고 나서 이때 나오는 Fine-tuning 된 weight나 Pre-train weight를 가지고 이렇게 하는 방법도 있습니다.
이게 뭐냐면 도메인에 대한 학습데이터가 많은 경우에는 데이터가 많으면 Pre-train을 쓰지 않아도 Longer training을 하면 충분히 좋은 결과를 얻을 수 있다고 합니다. 이때 여기서 training을 오래 했기 때문에 Pre-train 된 representation를 잊어버리게 된다라고 얘기하고 있습니다.

다음은 이 논문에서 제안하고 있는 것들입니다. 보시면 Pre-train 된 weight를 쓰고 그다음에 Detector를 추가한 다음에 이 아래쪽에 있는 Pre-training은 freezing을 하게 됩니다. 그리고 Fine-tuning 하게 되면 여기는 freezing 됐기 때문에 학습되지 않았을 거고 새로 추가된 Detector만 학습되는 결과를 볼 수 있습니다. 이렇게 되면 여기서 Pre-train 된 representation는 계속 유지가 됩니다. 이 논문이 제안하는 학습방법인데 이러면 아래쪽이 학습이 안 되기 때문에 resource로 학습을 할 수 있으면서도 그다음에 좋은 성능을 달성할 수 있다고 주장하고 있습니다.

여기서는 Faster-RCNN 기준으로 실험을 많이 했습니다. 아래쪽 부분이 ResNet이고 freezing이 되고 추가되는데 Detector 네트워크가 학습된다고 보시면 될 거 같습니다.

간단한 실험입니다.
ResNet의 FPN에 미치는 가장 기본적인 RCNN을 보시면 이렇게 freezing을 하게 되면 당연히 성능이 떨어지게 됩니다. 이렇게 FPN 대신에 NAS-FPN이나 Cascade NAS-FPN을 붙이게 되면 freezing을 했음에도 불구하고 성능이 좋아지는 결과를 볼 수 있다고 합니다.
그래서 추가된 Detector에 크기와 구조가 성능 향상에 중요한 역할을 한다, 그리고 또 한 가지는 Long-tail 즉, 우리가 자주 볼 수 없는, 레어 한 클래스에서도 좋은 성능을 달성할 수 있다고 얘기하고 있습니다.
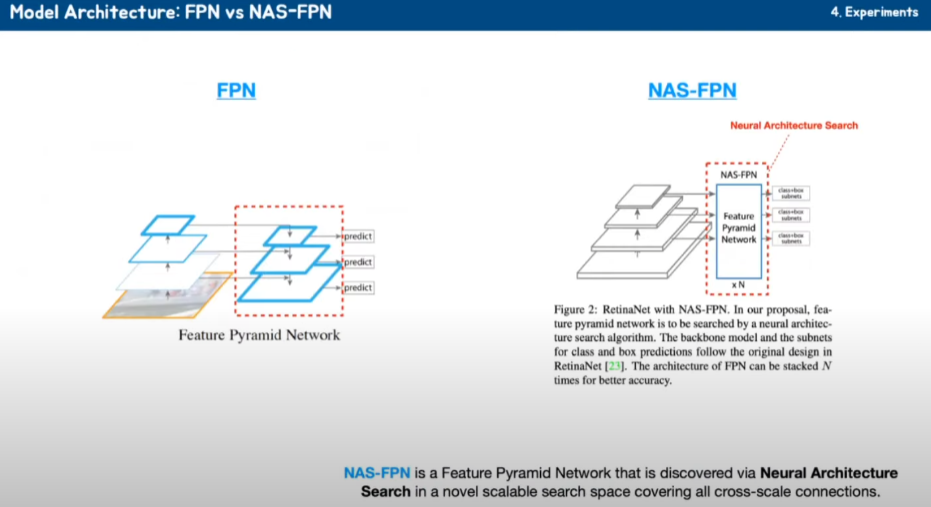
실험에 들어가기 전에 몇 가지 좀 필요한 것들이 있어서 정리하고 가겠습니다. FPN이라고 하면 보통 이렇게 backbone 네트워크에서 나온 것들을 Upsampling 해 가면서 어떤 특징을 추출해서 그거 가지고 예측하는 게 FPN입니다. NAS-FPN는 인공지능을 이용해서 Neural architecture search를 이용해서 인공지능이 Neural 네트워크를 구성하도록 했다고 합니다.
그래서 이게 좀 더 성능이 좋다고 합니다.
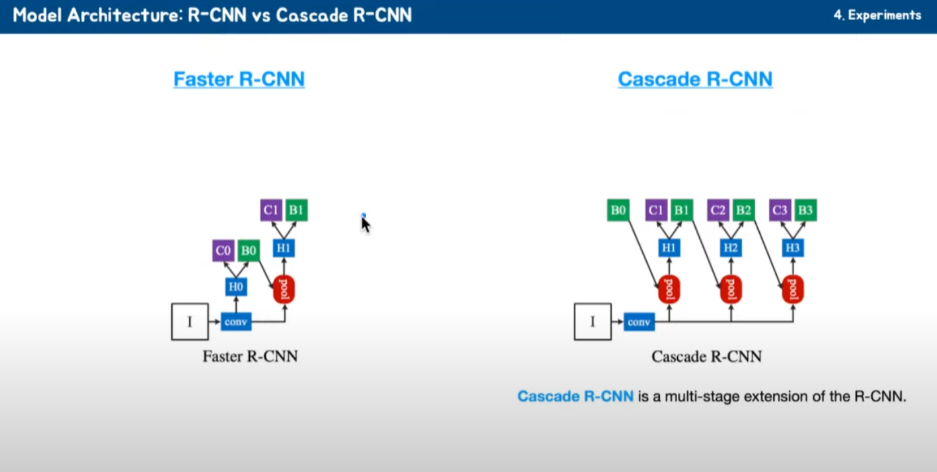
Faster R-CNN의 마지막 네트워크입니다. Cascade R-CNN은 이렇게 Detector 네트워크를 여러 개 두어서 multi-stage로 추론해 낼 수 있고, bounding box나 클래스를 추론해 낼 수 있도록 하는 것이 Cascade R-CNN입니다.

그다음에 Pre-train에는 두 가지를 썼습니다. ImageNet은 많이 알려져 있습니다. 1.2M 이미지가 있고 약 천 개 클래스가 있다고 합니다. 그리고 JFT-300M 데이터셋이 있는데 300M 이미지가 있고 그다음에 클래스 개수가 18,000 개
그리고 이 JFT-300M는 사람이 직접 한 게 아니고 알고리즘을 통해서 라벨링을 했다고 합니다. 그래서 약 20% 정도 label error가 있습니다. 데이터는 JFT-300M이 많지만 데이터 품질은 ImageNet이 좋다 이렇게 생각하시면 될 거 같습니다.

다음에 Fine-tuning에서 실험할 때 쓴 데이터입니다. MSCOCO는 118K의 이미지가 있고 클래스 개수는 91개 비교적 좀 적은 개수가 있습니다. LVIS 데이터는 100k 개의 이미지가 있고 클래스 개수가 1200개 정도 있고 1200개 중에는 Long tail. 즉, 개수가 아주 적은 레어 한 클래스도 있다고 얘기를 하고 있습니다.

그다음에 augmentation입니다. 어떤 이미지에다가 Copy-Paste 하듯이 이미지를 붙여놓기도 하고 이렇게 neural network이 예측하도록 하는 이런 Copy-Paste augmentation을 썼습니다.

그다음에 Residual Adapter입니다.
보통 이게 ResNet의 Residual block인데 W가 있고 Activation function이 있어서 이렇게 residual을 구성하게 됩니다. residual adapter는 여러 가지 task를 지원하기 위해서 이렇게 ResNet에다가 추가적으로 이렇게 adapter block들을 추가했습니다. 그러고 나서 w1, w2는 freeze를 하고 추가되는 네트워크들을 Fine-tuning 하도록 하는 게 residual adapter입니다.

실험 부분 정리해 보겠습니다.
72 epoch을 학습했을 경우입니다. FPN은 freeze 했을 때 성능이 떨어지는 걸 볼 수 있습니다.
그다음에 NAS-FPN을 썼을 때는 feeze를 하면 성능이 올라가고 있는 걸 볼 수 있습니다.
72 epoch 보다는 600 epoch을 학습했을 때는 FPN은 성능이 떨어지고 있는데 NAS-FPN는 성능이 올라오고 있습니다. 올라오고 있는데 72 epoch 보다는 600 epoch이 성능이 더 많이 올라가는 걸 볼 수 있습니다. 그리고 freeze 했기 때문에
학습이 일부만 되기 때문에 이게 600 epoch을 하더라도 연산양이 많지 않다 이렇게 생각하시면 좋을 것 같습니다.

그다음에 각각에 대해서 비교했습니다.
보시면 FPN, NAS-FPN 그다음에 Cascade, ResNet 키워가면서 비교해 봤는데 freeze 하지 않았을 경우에는 ImageNet이나 JFT-300M이 비슷한 성능을 내고 있는 것을 볼 수 있습니다.
그다음에 freeze 했을 경우에는 JFT-300M을 하는 것들이 훨씬 더 좋은 성능을 내고 있는 걸 볼 수 있습니다. 무슨 말이냐면 JFT-300M을 했을 때가 이미지가 조금 더 분포가 좋진 않지만 많은 데이터를 학습하고 weight를 유지함으로써 좋은 성능을 낼 수 있다 이렇게 볼 수 있습니다.
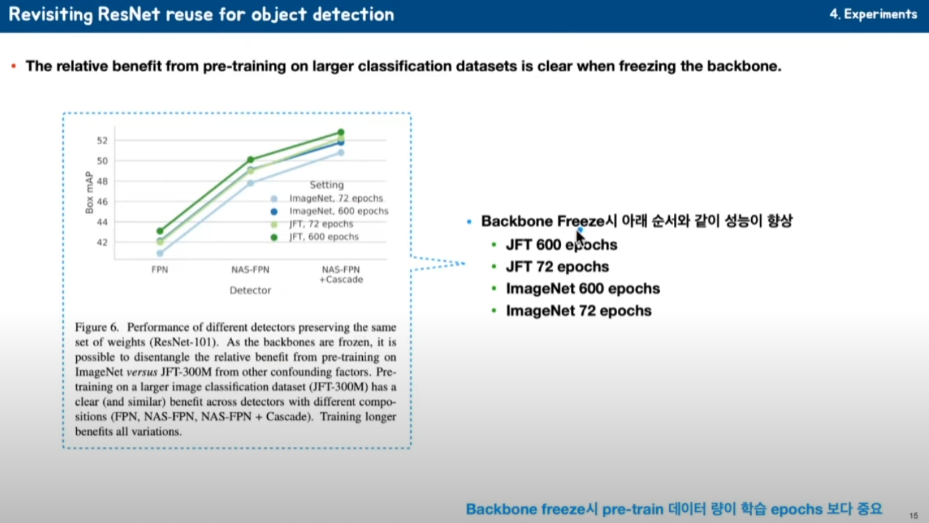
그다음에 성능에 대한 얘기를 하고 있습니다. 가장 위에 것이 JFT로 Pre-train 하고 600 epoch을 한 경우고,
두 번째 경우가 JFT로 Pre-train 하고 72 epoch을 한 경우, 세 번째가 ImageNet을 학습하고 600 epoch을 한 경우,
마지막이 ImageNet으로 Pre-train 하고 72 epoch을 했습니다. Pre-training 학습양이 학습을 얼마나 하느냐보다 더 중요하다고 할 수 있습니다.

좀 더 자세하게 비교해 봤습니다.
ImageNet과 JFT을 사용하고 그다음에 짧게 72 epoch을 하고 backbone을 freeze 했을 때 보시면 약간의 성능 차이가 있는 것을 볼 수 있습니다. 그다음에 ImageNet과 JFT로 Pre-train 하고 학습을 오래 하고 freeze를 하지 않으면 두 개가 비슷한 것을 볼 수 있습니다. 그리고 여기서 제안하는 JFT로 Pre-train 하고 학습을 오래 하고 backbone을 freeze 하면 가장 좋은 성능을 내는 것을 볼 수 있습니다.
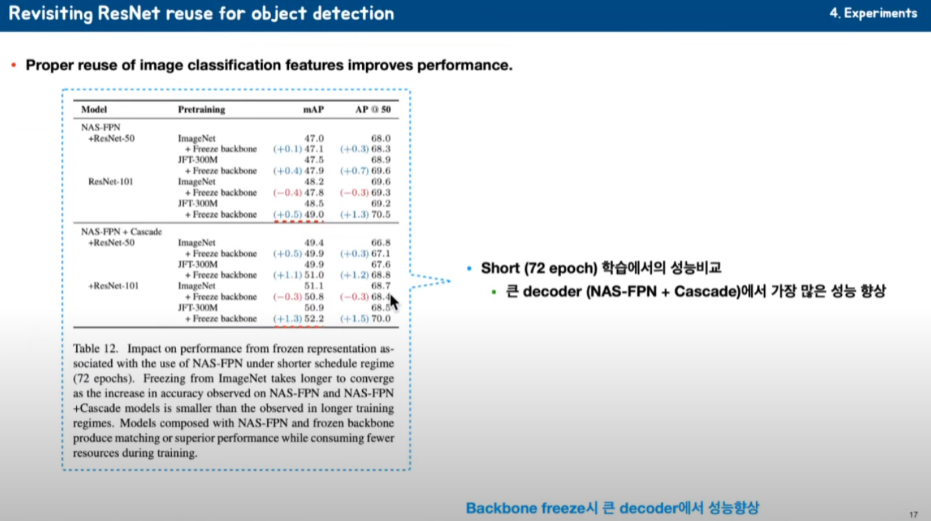
그다음에 NAS-FPN과 Cascade에 대한 성능을 비교하고 있습니다.
freeze 한 것들이 성능이 지속적으로 좋아지는 것 들을 볼 수 있습니다. 그렇지만 NAS-FPN 보다는 Cascade를 추가한 게 가장 좋은 성능향상을 보이고 있는 것을 볼 수 있습니다. 이걸 어떻게 볼 수 있냐면 backbone을 freeze 했기 때문에 추가되는 decoder 네트워크가 좀 더 크고 어떤 정보를 담기에 충분하게 어느 정도 파야지 잘 된다라고 decoder 좀 커져야 잘 된다고 얘기를 하고 있습니다.

그다음에 freeze 하고, 하지 않았을 때 Fine-tuning 했을 때랑 freeze 했을 때 패턴을 볼 수 있습니다.
freeze 했을 때는 패턴을 찾기가 어렵습니다. 그런데 freeze 하지 않았을 때는 보시면 NAS-FPN이나 FPN, Cascade NAS-FPN 모두 약간 다양성이 보입니다. 그래서 decoder의 크기 Pre-train의 데이터의 양 epoch 등에서 일정한 패턴을 보이고 있는 것들을 확인할 수가 있습니다.

FPN, NAS-FPN, Cascade NAS-FPN 보시면 기본적으로 FPN보다는 NAS-FPN이 파라미터가 많고 그다음에 NAS-FPN보다는 Cascade NAS-FPN 파라미터가 많은 데 training 되는 것들을 실제로 보시면 26%, 39%, 53% 이런 식의 추가된 네트워크들이 많은 것들이 좀 더 많이 training 되는 걸 볼 수 있습니다.
이때 데이터를 보시면 decoder 네트워크가 클 때 성능향상이 되는 것을 알 수 있습니다.
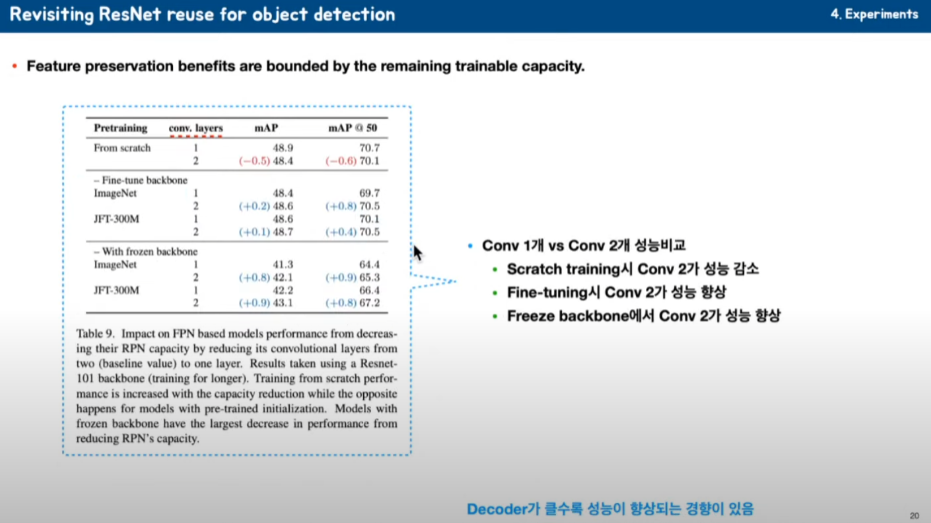
FPN 대신에 Convolution을 한 개 또는 두 개 아주 극단적인 테스트를 해봤습니다. Scratch로 training 했을 때는 오히려 Convolution layer가 커지면서 성능이 감소하는 것들을 볼 수 있습니다. 다음에 Fine-tuning 했을 때 보시면 ImageNet을 학습했을 때나 JFT를 학습했을 때나 Convolution layer가 커지면 성능향상이 있는 걸 볼 수 있습니다. 마찬가지로 freeze 했을 때도 Convolution이 커지면 좀 더 성능향상이 많이 되는 것을 알 수 있습니다.

지금까지 RCNN계열이었고 EfficientNet으로 했을 때 보시면 MSCOCO 하고 LVIS에 대해서 봤습니다. 이때 NAS-FPN을 추가했을 때가 좋은 성능을 보이고 있습니다. freeze 했을 때 성능 향상이 되고 있는데 Copy-Paste augmentation을 쓰고
backbone freeze를 하면 더 좋은 성능이 나는 것을 볼 수 있습니다.
LVIS도 freeze를 하고 Copy Paste를 썼을 때 가장 좋은 성능을 내는 것을 볼 수 있습니다.
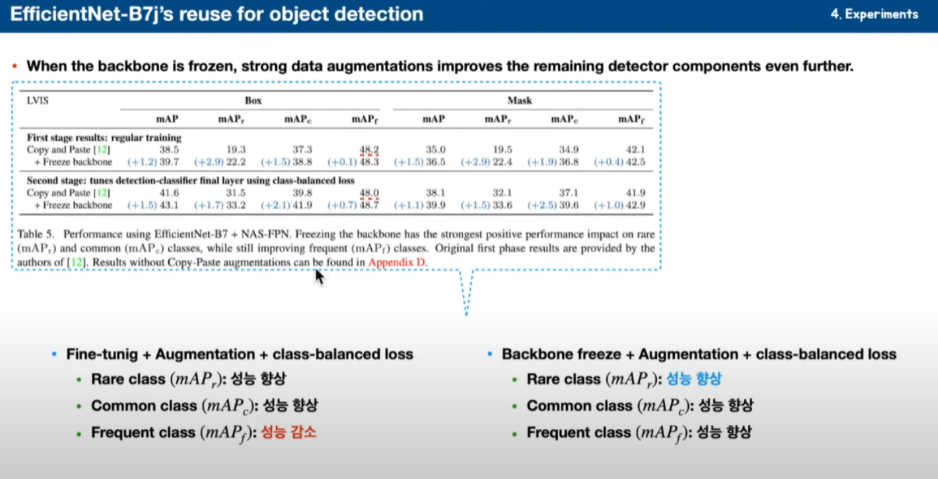
라벨의 특징에 대해서 얘기를 하고 있습니다. 2 stage를 했는데 처음에 그냥 일반적인 training을 하고 다음에 class balance Loss를 줬을 때입니다.
Fine-tuning 경우에는 freeze를 하지 않았을 경우에 성능 향상들이 있습니다. Rare, Common, Frequent 한 경우를 볼 수 있는데 Frequent 한 경우는 성능 감소가 있는 것을 볼 수 있습니다.
그런데 freeze 했을 경우에는 Rare, Common, Frequent 모두 성능 향상이 있었고 특히 Rare 한 곳에서 성능향상을 주목해 볼 수 있을 겁니다. Rare class가 class 임베디언스에서도 조금 더 잘하고 있다고 얘기하고 있습니다.

그다음에 이미지 사이즈입니다.
이미지 사이즈가 small, medium, Large 이렇게 했을 때, freeze backbone을 했을 때 보시면 Large 쪽에서 성능 항상 있는 것을 볼 수 있습니다. 이미지 특성 중에서는 Large를 좀 더 잘 잡아낸다 이렇게 얘기하고 있습니다.

학습 데이터양에 대해서 얘기를 하고 있습니다.
데이터양이 늘어날 때 어떻게 되는지 비교해보고 있는데 ImageNet으로 학습했을 경우, JFT를 학습했을 경우 보시면 FPN의 경우는 backbone을 freeze 한 게 성능이 낮은데 Cascade 보시면 아래쪽에서 조금 더 성능 항상이 있는 것을 볼 수 있습니다.
데이터가 적은 경우에 상대적으로 성능 향상이 효과가 뛰어나다고 얘기하고 있습니다. 이건 아무래도 파라미터가 작기 때문에 그런 것으로 추정됩니다.

데이터양에서 비교를 하고 있습니다. Copy Paste를 안 하는 경우와 Copy Paste를 한 경우를 비교해보고 있습니다.
Copy Paste를 안 한 경우는 데이터 양이 아무리 작기 때문에 기본적으로 성능 향상이 있고 Copy Paste를 augment를 했을 경우에는 성능향상이 적지만 그래도 성능향상이 있다고 볼 수 있을 것 같습니다.

backbone freeze가 최선의 방법이냐라고 얘기하고 있는데 그렇진 않고 이렇게 freeze를 한 다음에 residual adapter를 추가적으로 더 넣었을 경우에 성능향상이 있다고 얘기하고 있습니다.
가장 좋은 경우는 Fine-tuning을 하고 residual adapter를 추가하고 다음에 NAS-FPN + Cascade 이 경우가 가장 좋다고
얘기하고 있습니다. 이거는 논문에서는 결국 엄청나게 많은 파라미터를 학습하기 때문에 좋아진 것이다 이런 식으로 얘기하고 있습니다.




댓글