안녕하세요 콥스랩(COBS LAB)입니다. 오늘 소개해드릴 주제는 pandas입니다. 이번 시간에는 저번 시간에 소개한 중복값에 대해서 좀 더 알아보도록 하겠습니다.
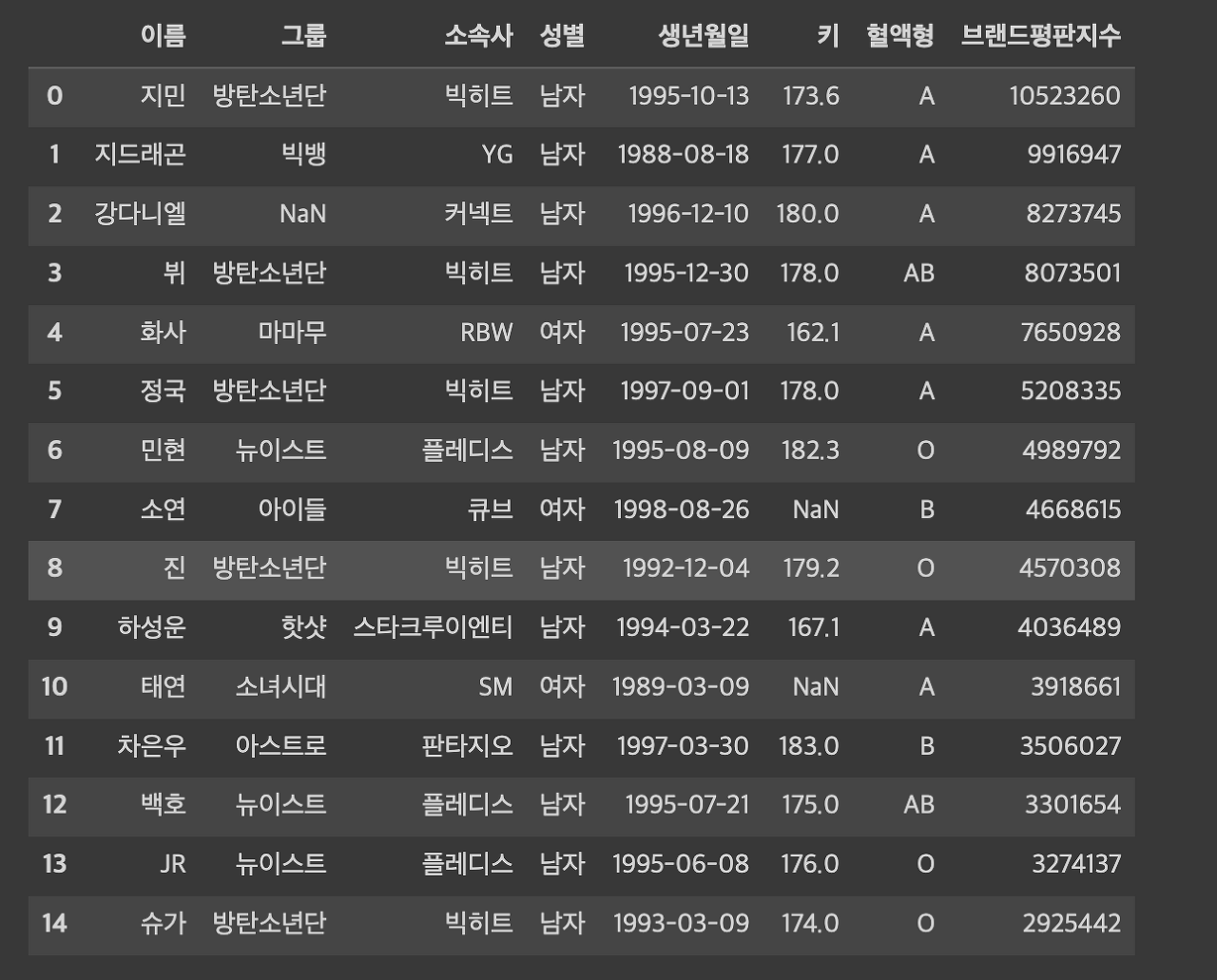
판다스 기초를 진행하면서 사용할 국내 아이돌 평판지수 데이터 프레임입니다.
drop.duplicates()
drop.duplicates( )는 데이터 프레임에서 중복되는 값이 있는 행을 제거하고 싶을 때 사용하는 메서드입니다. 아무것도 지정하지 않으면 모든 열(column)을 기준으로 중복을 제거해 줍니다.
df.drop_duplicates(['그룹'])
파라미터로 '그룹'열을 지정해 줘서 중복값을 제거했습니다.
keep='first'
중복되는 데이터 중에서 어떤 행을 남길지 지정할 수 있습니다. 'first'로 설정할 경우 인덱스 기준 가장 앞에 있는 행만 남습니다.
df.drop_duplicates(['그룹'], keep = 'first')
'first'가 default값이기 때문에 위와 같이 나왔습니다.
keep='last'
중복되는 데이터 중에서 어떤 행을 남길지 지정할 수 있습니다. 'last'로 설정할 경우 인덱스 기준 가장 마지막에 있는 행만 남습니다.
df.drop_duplicates(['그룹'], keep = 'last')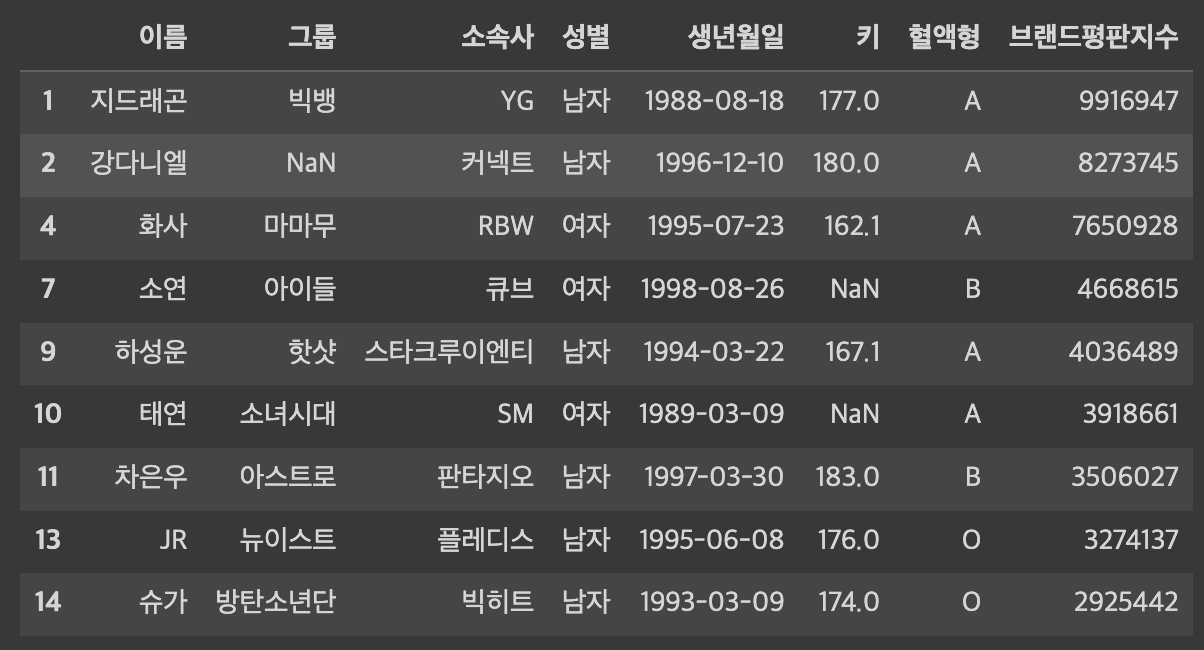
keep=False
중복되는 데이터 중에서 어떤 행을 남길지 지정할 수 있습니다. False로 설정할 경우 중복값이 있는 행을 모든 행을 제거해 줍니다.
df.drop_duplicates(['그룹'], keep = False)
'pandas' 카테고리의 다른 글
| pandas 기초(14) - 데이터프레임 합치기 concat() (0) | 2023.03.17 |
|---|---|
| pandas 기초(13) - 데이터프레임 합치기 concat() (2) | 2023.03.15 |
| pandas 기초(11) - 중복값 확인하기 duplicated() (0) | 2023.03.03 |
| pandas 기초(10) - 결측값 정리하기 dropna 옵션 axis, how, inplace (0) | 2023.02.27 |
| pandas 기초(9) - 결측값 정리하기 dropna(), fillna() (0) | 2023.02.22 |




댓글