안녕하세요 콥스랩(COBS LAB)입니다. 오늘 소개해드릴 주제는 pandas입니다. 이번 시간에는 판다스 결측값에 대해서 알아보도록 하겠습니다.
판다스 기초를 진행하면서 사용할 국내 아이돌 평판지수 데이터 프레임입니다.

dropna()
dropna()는 모든 칼럼 데이터 중 하나라도 결측값이 있다면, 그 행을 삭제합니다.
df.dropna()

여기에서는 '강다니엘', '소연', '태연'행이 삭제되었습니다.
df.dropna(subset =['칼럼'])
모든 칼럼이 아닌, 특정 칼럼의 결측값 데이터만 삭제할 수 있습니다. subset 을 이용해서 리스트 안에 칼럼 이름을 입력하면, 해당 칼럼들에 비어있는 값이 있을 경우 해당 행을 삭제합니다.
df.dropna(subset =['키'])
여기서는 '키'칼럼에서 결측값이 있는 '소연'과 '태연'행이 삭제 됐습니다.
df.info()
저번 시간에 배운 df.info()를 사용해서 데이터프레임의 정보를 확인하였습니다.

여기서는 '그룹'과 '키' 칼럼에서 결측값이 있는 것을 확인할 수 있습니다.
df['키']'키' 칼럼을 추출해 보도록 하겠습니다.

인덱스 7번과 10번에 결측값이 있는것을 확인했습니다.
df.fillna()
fillna()는 결측값 데이터를 다른 데이터로 채워줍니다. fillna 괄호 안에 원하는 숫자를 넣으면 됩니다.
df['키'].fillna(1)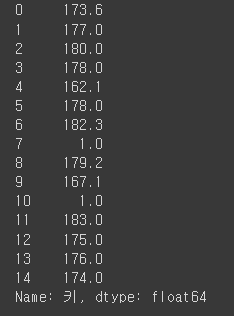
결측값에 원하는 숫자인 1이 들어간것을 확인할 수 있습니다.
'pandas' 카테고리의 다른 글
| pandas 기초(11) - 중복값 확인하기 duplicated() (0) | 2023.03.03 |
|---|---|
| pandas 기초(10) - 결측값 정리하기 dropna 옵션 axis, how, inplace (0) | 2023.02.27 |
| pandas 기초(8) - 결측값 확인하기 isna(), notna() (0) | 2023.02.01 |
| pandas 기초(7) - 칼럼 배우기 part 2 (0) | 2023.01.31 |
| pandas 기초(6) - 칼럼 배우기 part 1 (0) | 2023.01.30 |




댓글