안녕하세요 콥스랩(COBS LAB)입니다.
오늘 소개해 드릴 논문은 ‘DeepFM: A Factorization-Machine based Neural Network for CTR Prediction’입니다.
해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임' DeepFM: A Factorization-Machine based Neural Network for CTR Prediction’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크:https://youtu.be/otjvQYbGzEI)

먼저 논문에 대해 정리한 내용입니다. 추천시스템에선 CTR을 최대화하기 위해서 유저 행동에 숨겨진 복잡한 상호관계인 feature interaction을 학습하는 게 정말 중요합니다. 그걸 통해서 되게 좋은 추천 시스템을 만든다고 보시면 됩니다.
기존 방법론 같은 경우는 low order랑 high order에 치우쳐서 학습을 하거나 아니면 어떤 전문가가 feature 인지해야 되는데 여기서 말하는 high order나 low order는 뒤에 좀 더 설명을 드릴 예정이라 잠깐 설명을 드리면 두 상품을 한 상품과 다른 상품을 산 사람이 그 상품을 봤을 때 연관도가 없는 상품일 수도 있고 연관도가 있는 상품일 수 있어야 그런 상호 관계를 맞추는데 급급했습니다.
논문의 저자는 그 두 개 low order와 high order를 end to end 모델을 활용해서 학습이 가능해서 그 두 가지를 다 맞추는, 한쪽에 치우치지 않고 두 가지 이용해서 다 추천 시스템 모델을 잘할 수 있다고 발표했다고 보시면 됩니다.

참고로 CTR 같은 경우 말 그대로 광고를 본 사용자가 해당 광고를 클릭하는 빈도라고 보시면 되는데 CTR이 많을수록 키워드와 광고나 무료 제품들의 실적 파악을 확인하고 즉, 내가 한 마케팅, 회사가 한 마케팅이 잘 이루어졌는지 유저들이 잘 들어와서 구매를 유도했는지 그런 것들을 보는 지표라고 보시면 됩니다.

CTR Prediction에 가장 중요한 것은 유저가 추천 아이템을 클릭할 확률을 추정하는 것이 되게 중요합니다. 왜냐하면 아이템 자체에서 아이템 랭킹 시스템이 없다면 단순히 매출등을 most popular를 이용해서 순위를 매길 수도 있지만 로그 데이터를 더 활용하려면 CTR를 활용을 해야 합니다. 그래서 CTR Prediction이 유저의 클릭 행동에 존재하는 내재적인 feature interaction을 찾는 과정이라고 보시면 됩니다.

Feature interaction은 쉽게 말하면 관계성이라고 생각하시면 됩니다.
A 예시처럼 사람들이 식사 시간에 배달 앱을 다운로드하는 경향이 있다는 거는 생각하는 자연적인 현상입니다. 우린 그거를 high order interaction이라 부를 건데 반대로 어떤 상품 품목에 또는 장바구니에 맥주와 기저귀를 함께 구매하는 경향이 있다는 게 사람이 봤을 때는 부모가 성인이고 그리고 자녀가 있는 집 안에서 구매했나 보다 생각할 수 있습니다.
machine learning 같은 경우는 저 관계가 정말 강한 연관성 갖고 있나 그런 걸 파악할 수 없으니까 low order interaction이라고 생각하시면 됩니다. 뒤에서 계속 나올 high order interaction과 low order interaction은 이 정도의 개념이라고 생각을 하시면 됩니다.

그럼 결국 이 논문에서 말하는 목적 그리고 CTR prediction의 목적은 한 유저가 여러 가지 아이템을 구매했는데 상품을 들어갔을 때 한 번에 바로 살 수도 있고 여러 번 상품에 들어갈 수도 있습니다. 그런 것처럼 유저에게 추천 아이템을 주었을 때 유저가 해당 아이템을 클릭할 확률을 통해서 랭킹을 매기면서 A라는 유저에게는 아이템 36번을 추천해 주는 게 좋다. 이런 식으로 랭킹을 매긴다고 보시면 됩니다.

DeepFM이 오기 전에 과거의 논문은 어떻게 구성이 되었냐면 되게 유명한 Factorization-Machine, Generalized Linear Model 이런 것들이 있었습니다.
먼저 Factorization-Machine을 간단하게 설명을 드리면 내적의 관계로 아이템끼리의 연관성, feature들의 연관성을 모델링했다고 보시면 됩니다.
되게 상관관계가 높은, 연관성이 높은 상품들을 구매한 interaction에서 모델링을 할 수 있지만 너무 복잡해지는 high compression에 의해서 두 가지의 상품으로만 갖기 때문에 만약 마트에 갔으면 우유를 샀으면 빵을 산다던지 이런 것만 가능하지 우유를 통해 시리얼 또는 우유를 통해서 컵 이런 식의 다양한 interaction은 고려하지 못합니다.
두 가지점만 할 수 있는 단점이 있고 Generalized Linear Model은 선형 모델로 학습을 하는데 복잡한 거는 다시 학습할 수가 없습니다. 그래서 interaction에 직접 feature vector를 넣어 주긴 하지만 이것 또한 아쉽게도 high order를 학습할 수 없고 더군다나 cold start 문제가 존재합니다.
cold start는 신규 유저가 들어왔을 때 유저에게 무엇을 추천해 줄지 모르는 현상인데 그런 현상을 해결할 수 없는 모델이라고 보시면 됩니다.

FNN Factorization-Machine을 Neural network와 결합한 모델은 되게 좋은 건 feature embedding을 통해서 가중치 학습을 초기화한 건 되게 좋았지만 성능에 제한이 이루어지는 게 안타까운 부분이라고 생각이 되고 product based 즉, 상품기반으로 Neural network를 구성했을 경우에는 상품끼리에 연관도는 되게 파악을 잘할 수 있지만 반대로 아까 맥주와 기저귀 예시처럼 상관관계가 되게 없어 보이는 제품들에 대해서는 interaction은 전혀 포착하지 못하니깐 아쉬운 부분이 있었다고 보시면 됩니다.

좋았다고 평가받는 게 Wide & Deep입니다. Wide & Deep은 low랑 high를 다 모델링하기 위해서는 어느 정도의 성능은 나왔지만 한 가지 단점은 Wide & Deep 하면서 Wide 파트랑 Deep 파트가 인풋으로 있는데 wide part input은 feature engineering이 필요합니다. 그래서 그걸 잘못하면 성능이 나오기 어려워집니다.
wide part input은 입력 vector가 되게 커져서 복잡성을 좀 증가시킬 수 있는 문제를 갖고 있었습니다.

그렇다면 과거까지 low order, high order 즉, 한 가지에만 feature interaction 되는 부분 혹은 너무 feature engineering에다 시간을 많이 써야 되는 모델링이 주였다면 DeepFM 같은 경우는 feature enginerring 없이 low order, high order에 상관 관계도를 end to end 방식으로 모델을 제안을 했습니다. 이에 자세한 부분은 뒤에서 설명을 드리겠습니다.

Contribution입니다.
FM과 Deep learning을 둘 다 활용을 해서 DeepFM이 구성된다라고 보시면 됩니다.

논문에서 어떻게 접근을 했냐면 DeepFM의 데이터. 모델 아니고 데이터 구조인데 데이터가 어떻게 들어오냐인데 n개 데이터가 있다고 했을 때 각 low는 유저의 아이템 정보를 갖고 있는 x, 그리고 아이템 클릭인 y가 있습니다.
x는 유저와 그리고 이 유저가 무슨 아이템을 샀는지를 구성하는 부분이라고 보시면 됩니다. 보통 x에는 categorical field 즉, 성별이나 위치 one hot vector 혹은 continuous field 즉, 연속적인 값 나이 같은 것 이러한 부분들이 주로 담긴 게 x라고 생각하시면 됩니다.
y는 클릭의 여부입니다. 클릭을 했나 안 했나 0 1 이진값이라고 생각하시면 됩니다.

결국 CTR DeepFM의 목표는 어떤 context가 주어졌을 때 특정 앱을 클릭할 확률을 추정하는 모델을 만드는 것이 CTR 모델 DeepFM의 목적이라고 생각하시면 됩니다.
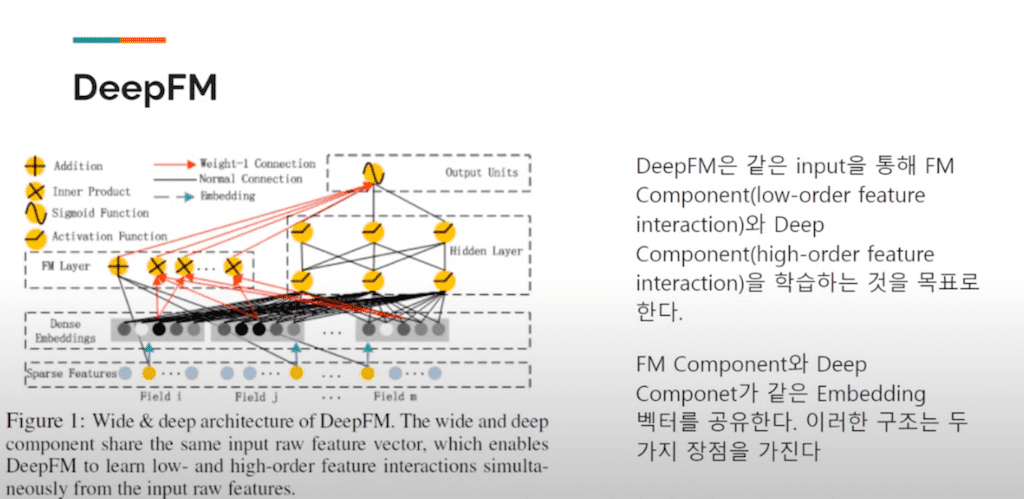
그러면 도대체 DeepFM이 어떻게 구성이 됐을까를 간략히 보시면 Wide & Deep는 다른 인풋값을 넣는데 DeepFM는 같은 인풋값을 통해서 FM 부분 즉, low order feature interaction을 잡는 FM 부분과 Deep Component high order feature interaction 부분을 학습하는 것을 목표로 하는데 FMComponent보다 Deep Component에서 같은 embedding vector를 공유를 합니다. 공유를 어떻게 할지는 뒤에서 FM component 부분과 Deep component 부분에서 더 자세히 설명하겠습니다.

이러한 구조가 갖는 embedding vector를 같은 embedding vector로 공유하는 것이 대체 어떠한 강점을 갖나 보시면 vector의 크기는 사실 다를 수 있습니다. 입력값마다 다를 수 있지만 결국엔 embedding layer로 인해서 조정이 됩니다.
지금 여기서 그보다 더 중요한 부분은 V 부분이 결국 행렬로 의해서 사전 학습이 되는데 그런 부분이 feature embedding 처음에 들어온 인풋값의 layer이고 그다음에 행렬의 값을 통해서 나온 embedding인데 이거를 가중치를 추가해서 학습을 하면 DeepFM이 Pretrain 할 필요 없이 end to end로 학습을 할 수 있다고 생각하시면 됩니다.
이미 FM에 있는 Pre train을 사용하기 때문에 굳이 할 필요 없다 그리고 바로 End to End로 학습시킬 수 있다고 보시면 됩니다.

이후에 하는 방법은 sigmoid로 FM에서 나오는 값 그리고 Deep learning Deep component에서 나오는 값 2개를 sigmoid 활용해서 예측을 합니다.

FM component와 Deep component가 무엇이냐면 그림에서 보는 것처럼 이 레이어 같은 경우 inner product랑 addition 이 두 가지 부분을 담고 있는 게 FM layer입니다. 즉, 내적 feature 여러 가지 상품들에 대한 그 정보들을 다 넣으면 내적을 통해서 모델링을 한 부분이라고 보시면 됩니다.

연산을 보면 Addition unit 즉, 덧셈하는 이 유닛과 그다음에 inner product 상품이 들어왔을 때 그 상품의 interaction을 계산하는 Unit의 합이 y F M이라는 부분입니다.

Deep component는 high order 즉, 연관성에 되게 깊고 많은 그러한 feature들의 interaction 하는 부분이라고 생각하면 되고 순방향 Neural 네트워크 방식으로 학습이 된다고 생각하시면 됩니다.

이러한 수식에 대해서 잠깐 설명해 드리면 첫 번째 부분은 i번째 필드에 embedding 한 부분이고 m은 field 수 embedding vector 레이어 사이즈를 같다고 한 부분이고 그걸 통해서 들어옵니다.
그래서 a(0) 값이 들어오게 되어서 a(1) 가중치와 학습을 시키는 부분이고 마지막에 Dense 한 실수 feature vector가 형성되면서 CTR을 예측하는 함수로 보시면 되고 h는 은닉 계층입니다.
FM component나 Deep component는 둘 다 feature embedding을 이런 수식을 통해서 증명한다 보시면 되고 이게 왜 좋냐면 low feature에서 low order 그리고 high order feature interaction 둘 다 학습할 수 있게 되어서 Wide & Deep의 문제였던 전문적인 feature engineering이 크게 필요하지 않다고 생각하시면 됩니다.
도대체 왜 feature engineering에 대해서 무조건 좋은 건 아니지만 어느 정도 필요성을 느끼는 이유는 사실 인풋 데이터가 Dense 하면 되게 좋은데 보통은 굉장히 Sparse 해서 super wide dimension 합니다. 그런 이유로 embedding layer를 통해서 인풋 vector가 low Dense 한 압축이 되어서 Neural 네트워크를 들어가야 저희가 그 과정 하나하나를 계산하면서 feature engineering 하면 되게 좋지만 쉽지 않은 데이터가 많을수록 Sparse가 쉽지 않으니까 이런 식으로 모델을 직접 짜주는 feature engineering을 하면 좋다는 게 이 논문의 내용이라고 생각하시면 됩니다.

마지막 실험 부분입니다.
Criteo Dataset 4500만 명 유저가 클릭한 데이터셋에서 13개 정도에 Continuous feature와 26개의 categorical feature가 나온다 했고 CTR를 DeepFM을 실제로 구현을 한 데이터도 설명을 합니다.
약 10억 개 가까이 기록이 되는 건데 APP store에서 실제로 7일 정도 유저가 클릭하는 기록을 바탕으로 다음날 하루치를 평가하는 부분인데 앱 관련된 feature 즉, identification이나 카테고리나 이런 부분에 대한 유저 feature, 마지막 context feature 이 세 가지 기록된 게 총 10억 개 정도 된다고 보시면 됩니다.

평가를 할 때 썼던 Metrics는 LogLoss랑 AUC score입니다.
LogLoss는 간단히 말하면 모델의 출력값과 정답 오차를 정의한 함수이고 AUC는 이 성능이 1에 가까울수록 우수하거나 아니면 최악의 성능 이러한 모델의 classification 능력을 판단하는 부분이라고 생각을 하시면 됩니다.

LR 대비 학습 시에 걸리는 시간을 나타내는 그래프라고 보시면 됩니다.
DeepFM 같은 경우가 되게 낮습니다. LR에 비해서 되게 빠르고 비슷한 논문인 FNN는 DeepFM에 비해 오래 걸리고 오래 걸리는 이유가 Pretrain 하는데 시간을 되게 많이 쓴다고 기록했고 IPNN과 PNN의 경우엔 내적을 하면 학습 속도가 되게 오래 걸립니다. 마지막 Wide & Deep 모델보다는 살짝 느리다고 결과는 나왔지만 그래도 준수하다고 평가를 했습니다

두 번째 효율성의 대한 비교 부분입니다.
feature interaction이 표현되지 않은 Linear 보다는 interaction을 표현하는 다른 모델들에 비해 성능이 좋다고 결과가 나왔고 low order, high order feature를 둘 다 같이 학습하는 모델이 DeepFM과 Wide & Deep 두 가지 모델이 다른 모델보다 성능이 되게 좋았다. 마지막으로 feature embedding을 share 하는 DeepFM이 가장 성능이 좋았다고 보시면 됩니다.

결과적으로 보면 그래프를 봤을 때 엄청나게 눈에 띄는 성능이 보이진 않았습니다. 지금도 기록을 보면 그전에 가장 유사한 Wide&Deep과 비교해 줬을 때 0.37 포인트와 0.42%의 성능이 좋아졌다고 하지만 보시는 것처럼 10%만큼 성능이 좋아진 건 아니라서 큰 의미가 있을까 싶지만 실제로 Wide & Deep에서 논문을 발췌한 거 보면 오프라인에서 0.275의 포인트 차이는 실제 CTR에서 3.9%의 차이로 이어진다고 봤을 때 이 수치가 실제 CTR 영역에서는 좀 더 성능이 좋다 많게는 2, 3배 가까이 성능이 좋다고 볼 수 있다고 생각하시면 됩니다.
왜냐면 실제로 회사에서는 APP store에서 일일이 전환율이 많게는 수십, 수백, 수천 달러에 이익을 내는 것처럼 지금 이런 포인트를 높이는 게 회사에는 추가 이익을 가져오게 되는 성능향상에 효과적이었다, DeepFM이 되게 좋았다고 평가받을 수 있습니다.

마지막으로 DeepFM의 장점을 조금 정리한 부분입니다.
DeepFM은 FM과 DNN 즉, Factorize machine의 부분과 Deep learning을 같이 쓰는 모델이고 pre train이 없고 embedding vector를 공유하기 때문에 feature embedding 또한 필요가 없다. 이로 인해서 둘 다 표현이 가능하고 실제로 결과적으로 아까 논문에서 말했던 것처럼 real word dataset 부분에서도 효율성과 효과성에서 다룬 SOTA 모델보다 성능이 되게 좋았다는 것을 알 수 있습니다.




댓글