오늘 소개해 드릴 논문은 ‘Fine-grained Interest Matching For Neural News Recommendation’입니다.
콥스랩(COBS LAB)에서는 주요 논문 및 최신 논문을 지속적으로 소개해드리고 있습니다.
해당 내용은 유투브 ‘딥러닝 논문읽기 모임’ 중 ‘Fine-grained Interest Matching For Neural News Recommendation’ 영상 스크립트를 편집한 내용으로, 영상으로도 확인하실 수 있습니다. (영상링크: https://youtu.be/XW93QvbFlaQ)

오늘 살펴볼 논문은 ‘Fine-grained Interest Matching For Neural News Recommendation’입니다. 이 논문은 사용자의 흥미에 맞게 뉴스를 추천해주는 추천 시스템에 관한 내용을 담고 있습니다. 많은 사람들이 뉴스를 접하는 방식이 종이에서 디지털로 전환되고 있습니다. 구글이나 ms뉴스 같은 매체가 다양한 소스로부터 뉴스를 수집하고 사용자들에게 전달을 해 주고 있습니다. 하지만, 새로 생성된 뉴스에 양이 방대해서 사용자들이 자신의 흥미에 알맞은 뉴스를 찾기 어렵습니다. 따라서 뉴스 추천 시스템이 현재 필요한 기술로 자리 잡고 있습니다.

추천 시스템에서 중요한 것은 사용자의 지난 뉴스 검색을 결과를 토대로, 각 사용자의 다양한 흥미 분야의 알맞은 뉴스를 추천해 주는 것입니다. 기존 뉴스 추천 시스템은 크게 두 가지 타입으로 구분이 됩니다. 첫 번째는 Conventional Methods로, feature engineering 기법을 활용해서, 사용자와 뉴스의 관계를 학습하는 모델입니다. 두 번째 타입은 Deep Learning 모델로, Conventional Methods보다 비교적 최근에 많이 발표되었으며, 기존의 Conventional 한 방법보다 더 나은 성능을 보이고 있습니다. 하지만 기존 추천 시스템의 구조적인 한계로, 개인에게 알맞은 뉴스를 추천을 하기에는 어려움이 있습니다.

기존 추천 시스템이 알맞은 추천을 하기에 어려운 이유는, 대부분 검색 기록을 1차원 벡터화시켜서 사용자의 잠재된 흥미를 후보 뉴스에 매칭 하기 힘들기 때문입니다. 예를 들어서 2017년 Okura, 2019년 wu 저자가 발표한 논문도 GRU네트워크 오토 인코더를 적용하고 어텐션을 활용했지만, 사용자들의 지난 뉴스 기록을 가지고 최종으로 그들이 무엇을 클릭하게 될지 예측하는 점에서는 어려움이 있었다고 합니다. 기존 시스템과 다르게 오늘 소개해 드릴 논문은 FIM이라는 새로운 구조의 추천 시스템을 만들어서 이러한 문제를 해결하려고 했습니다. 이 모델은 HDC라는 convolution 네트워크를 사용해서 좀 더 깊이 있게 사용자의 잠재적인 흥미 분야를 파악하고 뉴스와 후보를 좀 더 다양한 레벨에서 볼 수 있기 때문에, 후보 뉴스를 단어와 문장에 대해서 더 많은 정보 학습이 가능하다고 합니다.

기존 대부분의 추천 시스템 모델은 사용자의 특성을 추출하고, 그 특성에 잘 들어맞는 뉴스를 추천해 주는 방식으로 이루어져 있습니다. 이 논문이 제시하는 FIM 방식은 사용자들의 특성을 추출하는 대신에, 뉴스를 다양한 레벨에서 매칭 시키고 다양한 측면에서 비교하여서, 더욱 정확한 정보를 추려낼 수 있다고 합니다.

그러면 이 모델에서 제시하는 FIM이라는 모델을 구조를 큰 그림으로 살펴보겠습니다. 첫 번째는 Problem Definition을 합니다. 사용자별 뉴스 검색 기록을 추출하고 그 뉴스를 임베딩 시켜서 벡터화를 진행합니다. 벡터 매트릭스 형태로 구조화된 뉴스를 재구조해줘야 되는데, Hierarchical dilated convolution (HDC)을 이용해서 뉴스를 3D 형태 매트릭스로 변형합니다. 그리고 3D형태로 변형된 뉴스의 기록들과 사용자가 클릭을 하게 될지 하지 않게 될지 결정할 후보 뉴스를 내적을 해 줍니다. 마지막으로, 이렇게 내적 된 각각의 값을 전부 합쳐 준 후 , 3D CNN을 걸쳐서 이 후보 뉴스가 후보 뉴스에 대해서 사용자가 클릭할 확률을 계산합니다.

그러면 다시 처음부터 이 모델이 어떻게 학습되는지, 첫 번째 순서인 문제정의 부분을 순서대로 살펴보겠습니다. 첫 번째는 사용자 u에 대한 뉴스 기록을 추출합니다. d1 뉴스 기록 1부터 n개의 뉴스를 추출해서, 뉴스에 제목 카테고리, sub카테고리를 워드 시퀀스 형태로 바꿔 주고, Glove를 활용해서 임베딩을 진행합니다. 그리고 후보 뉴스에서는 후보 뉴스를 읽었는지 안 읽었는지 1과 0의 bianry labeling으로 구분을 해 줍니다. 그리고 이 모델은 사용자의 뉴스 탐색 기록과 후보 뉴스가 입력이 되었을 때, bianry 예측 값을 구하는 함수를 구하고, 그 함수를 다시 사용해서 새로운 후보 뉴스가 입력되었을 때, 사용자가 새로운 후보 뉴스를 클릭할 확률 (Y햇)을 구하게 됩니다.

해당 모델의 데이터는 Microsoft News dataset를 사용하였고, Glove를 사용하여서 임베딩을 진행하였습니다. 그리고 이 논문의 저자는 GPU 제한으로, 제목과 카테고리, sub카테고리의 길이가 20을 넘지 않도록 하고, 사용자의 최근 뉴스 기록 50개를 사용하였다고 합니다.
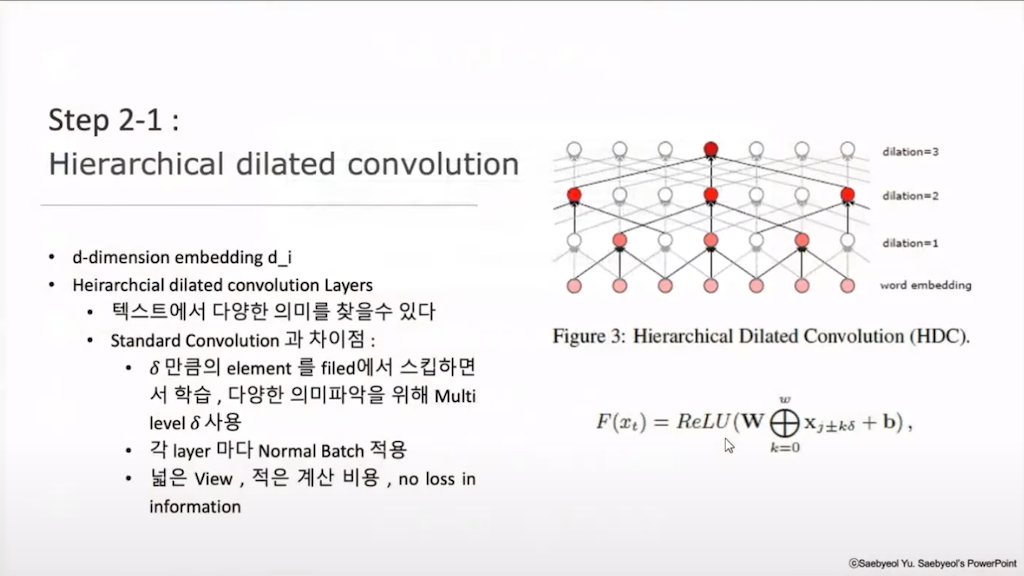
이렇게 수집하고 임베딩 한 뉴스들을 이제 3D 형태의 매트릭스로 바꿔 줘야 합니다. 첫 번째로 해야 할 일은 Hierarchical dilated convolution으로, 이 모델의 키포인트라고 할 수 있는 부분입니다. HDC는 저자가 이 모델의 장점이라고 강조하는 텍스트의 다양한 의미를 찾을 수 있도록 해주는 방식입니다. 그 방법은 각 layer에 델타 값을 다르게 주어서, 이 델타만큼의 엘리먼트를 스킵하면서 학습하여, 첫 번째 레이어에는 문장 군 학습이 가능하고, 델타가 점점 커질수록 깊이 있는 단어 군에서도 의미가 학습이 가능하다고 합니다.

이렇게 convoluted 된 결과를 3D로 다르게 주어진 각 layer의 결과에 대해서 normal batch를 적용해서 Variance를 줄여주고, Vanishing Gradient가 일어나지 않게 해 줍니다. 그리고 이 각 레이어의 결괏값을 쌓아줍니다. 이렇게 해 줌으로써, 델타 값이 1일때. 세밀한 문장군 학습부터 델타값이 클 때, 카테고리가 같은 다양한 의미의 학습이 가능합니다. 그리고 계산 비용은 적게 들지만 max pooling 같은 pooling이 들어가지 않아서, downsampling이 일어나지 않고, 따라서 정보 소실이 일어날 가능성이 적습니다.

이렇게 각 문서를 다방면에서 학습을 했으면, 이 문서들과 후보 문서에 대한 연관성을 알아봅니다. 이 후보 뉴스가 사용자가 좋아할 만한 뉴스인지 아닌지를 알아보기 위해서, 각 기록 문서 사용자가 브라우징 한 뉴스와 후보 문서를 짝지어주고 내적을 합니다. 이렇게 내적을 해줌으로써 HDC가 학습한 대로 델타 값이 다른 채널별로, 델타가 1인 채널, 델타가 3인 채널에 대해서 각각 중요한 정보를 학습할 수 있습니다.

이렇게 n개의 내적 된 페어들을 요약하기 위해서, 모두 합쳐서 큰 3D형태 이미지 Q라는 매트릭스를 만들어준 것을 확인할 수 있습니다.

이렇게 합쳐진 3D Q를 CNN과 max pooling을 해줌으로써, 이미지에서 특이하거나 중요한 시그널을 찾아냅니다. 그리고 이 결괏값이 1차원의 매칭 벡터가 되도록 계산해주고, 매칭 벡터를 가지고 사용자가 실제로 이 뉴스를 클릭했는지 하지 않았는지 주어진 0과 1 값에 대해 학습을 합니다. 그리고 이렇게 학습한 함수를 가지고 새로운 후보 뉴스가 주어졌을 때, 새로운 후보 뉴스를 클릭할지 클릭하게 되지 않을지 y햇에 대해서 계산을 해줍니다.

지금까지 모델 설명을 살펴봤습니다. 다음으로, 이 모델이 얼마나 잘 예측했는지 비교해야 하는 내용을 살펴보겠습니다. 저자는 다양한 추천 시스템 모델과 FIM 모델을 성능을 비교했습니다. 앞서 말씀드린 대로, 추천 시스템의 종류에는 두 가지 종류가 있습니다. 전통적인 방법에서는 matrix factorization을 응용한 모델들이 있고, Neural Recommendation Method들로는 Attention 또는 대부분 Encoder를 사용한 모델들이 있습니다. 위 표는 두 가지 방식의 대표적인 모델들의 성능을 비교한 표입니다.

결과는 Neural 추천 모델들이 전통적인 방식보다 나은 결과를 보여주었습니다. 그 이유로, 전통적인 방법이 최적의 방법은 아니고 deep neural model이 사용자와 뉴스 사이에 의미 있는 feature를 더 잘 분석하기 때문이라고 저자는 판단했습니다. 그리고 이 논문이 제시한 FIM 방식이 전통적인 방식과 neural network model 모델들을 전부 뛰어넘는 결과를 보여주었습니다. 그리고 마지막에 FIM first와 FIM last라는 메서드가 확인해보실 수 있는데, FIM first는 HDC 부분 델타 값을 다르게 주는 HDC를 빼고, 델타 값이 1인 평범한 convolution으로 뉴스를 학습한 모델입니다. FIM last모델은 HDC를 진행하고, 델타 값을 다양하게 주었을 때 맨 마지막의 레이어로만 학습한 가장 높은 델타 값으로만 학습된 레이어를 가지고 만든 모델입니다.
이렇게 비교해 봤을 때, 두 모델이 모두 기존 추천 시스템 보다는 나은 성과를 가진다는 걸 알 수 있습니다. 기존의 추천시스템 모델들은 사용자의 특성을 학습한 후에, 그 특성이 후보 뉴스를 예측하는 feature로 쓰였는데, FIM모델에서는 사용자의 특성을 학습하는 것보다 예측 후보 뉴스와 지금까지 읽은 뉴스를 pair 해주어서 학습하는 방식이 더 나았다는 걸 증명하고 있습니다.
FIM last 모델이 FIM first 모델보다 예측값이 높습니다. 이는 델타 값을 높게 주어서 좀 더 브로드하게 학습할 수록 더 나은 결과를 가질 수 있다는 것을 확인할 수 있습니다. 하지만 이 두 개의 결과가 fim 모델보다는 낮은데, 그 이유는 델타값을 다양하게 주어서 문서를 다양한 레벨에서 정보 학습이 가능하기 때문이라고 합니다.
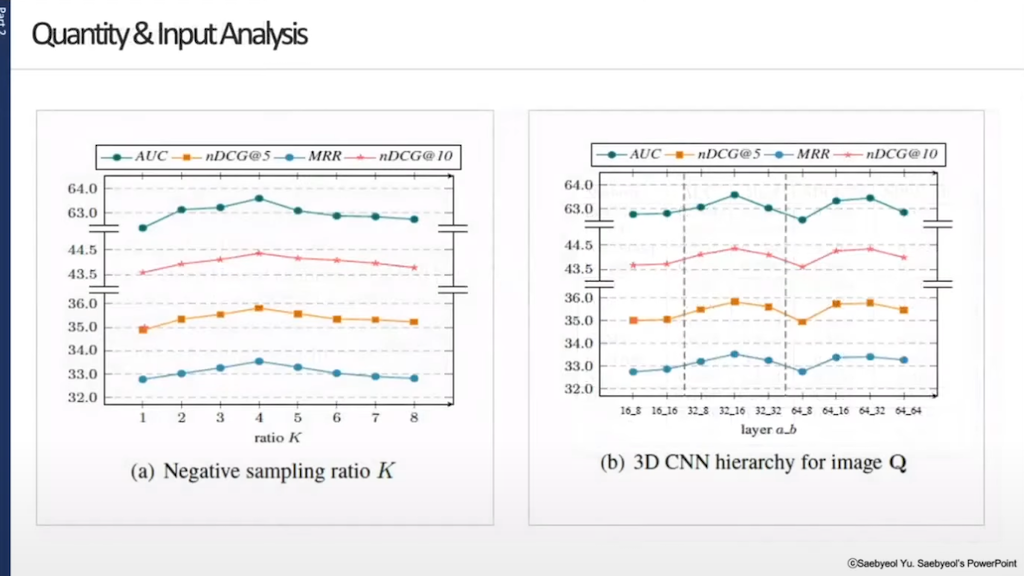
다음으로, 앞서 설명드린 모델에서 사용된 하이퍼 파라미터 값들을 얻게 된 Quantity & Input Analysis를 살펴보겠습니다. 위 그림의 왼쪽 그래프는 Negative sampling ratio K에서, 학습에 사용된 뉴스에서 실제로 사용자가 읽은 뉴스와 비슷한 내용이지만 읽지 않은 뉴스를 Negative sample이라고 표현합니다. 실제 읽은 뉴스와 읽지 않은 뉴스의 비율을 얼마 정도 했을 때, 가장 나은 결과를 나타내는지에 대한 비교 결과입니다. 결과를 보시면 읽은 뉴스는 1이고, 읽지 않은 뉴스를 4로 비율을 정했을 때 가장 높은 결과를 나타난다는 것을 알 수 있습니다.
위 그림의 오른쪽 그래프는 뉴스의 페어를 합친 Q에 대해서 3D CNN을 진행했을 때, 커널 값을 얼마나 주어야 최적의 결과를 나타내는지 비교한 내용입니다. 커널 사이즈를 32_16 이렇게 사용했을 때, 최적의 결과를 나타낸다는 것을 저자는 알아냈습니다.

위 그림의 왼쪽 그래프는 하이퍼 파라미터 델타 값입니다. 이 모델에서 HDC에서 델타 값을 다르게 준다고 했었는데, 이 델타 값을 얼마나 다르게 주었을 때 학습이 좋게 나오는 가에 대해서 델타가 3일 때 가장 높은 auc를 가진 다는 걸 알 수 있습니다. 그리고 위 그림의 오른쪽 그래프에서는 input에 대해서 분석했습니다. 이 글의 첫 초반 부분에, input에 대해 설명했을 때, 문장 제목과 카테고리 그리고 SUB카테고리 세 개를 넣었다고 설명드렸습니다. 위 그림의 오른쪽 그래프는 그 내용에 관한 것이고, 제목만 넣었을 때, 제목과 카테고리를 넣었을 때, 제목과 SUB카테고리를 넣었을 때, 그리고 전부 다 넣었을 때의 결과에 대해서, 전부 다 넣었을 때 가장 나은 결과를 나오기 때문에, 해당 논문에서는 그런 방식으로 input을 지정해 주었다고 합니다.

마지막으로 저자는 이렇게 추출한 추천 뉴스와 기록 뉴스의 단어에 대해서 내적 한 값을 시각화하였습니다. M1을 보시면 문장 1은 스포츠와 NFL이라는 단어가 있는데 문장 이해는 play off라는 단어가 문장 1에서 등장하지 않았는데, 그 두 개 단어가 높은 값을 가진 것을 알 수 있습니다. 그래서 문장1 주었을 때도 비슷하지만, 다른 내용인 문장 2도 역시 추천이 가능하다는 걸 알 수 있습니다. 그리고 M2를 보시면 파운드라는 단어와 문장 이해는 등장하지 않지만 역시 높은 값을 가진 다는 것을 알 수 있습니다. 이러한 결과를 토대로 저자는 이 모델이 의미 있는 추천 시스템 모델이라고 증명하였습니다. 지금까지 ‘Fine-grained Interest Matching For Neural News Recommendation’ 논문에 대해서 자세히 살펴보았습니다.




댓글